I have a list of candidates (with first name, last name and date of births) who been tested on multiple occasions and I now want to find those duplicate occasions however names may well have spelling mistakes and synonyms may have been used. Ideally I’d like to do a group by using information an Atlas Search index. Is this possible?
Hi @Brian_Henderson - Welcome to the community ![]()
I’m not entirely sure of the use case details (including how to verify which documents would be duplicates) but perhaps the following documentation may help:
Would this work flow for identifying “duplicates” be used on an every now and then basis? Or would it be considered part of your application’s standard workload? Curious to know if it’s just going to be used irregular to update / remove duplicates or just for identifying duplicates.
If you could also provide some examples / demonstrations using sample documents that would be helpful as well.
Regards,
Jason
Sorry I should give a bit more information. We work with schools and assess the same cohorts of students over a number of years but do not normally have a unique student identifier so we need the synonyms lookup (e.g. Elizabeth, Beth, Liz) as well as fuzzy logic matching. Ideally we would want to be able to group ‘on the fly’ to take the top table and run a query to generate the second:
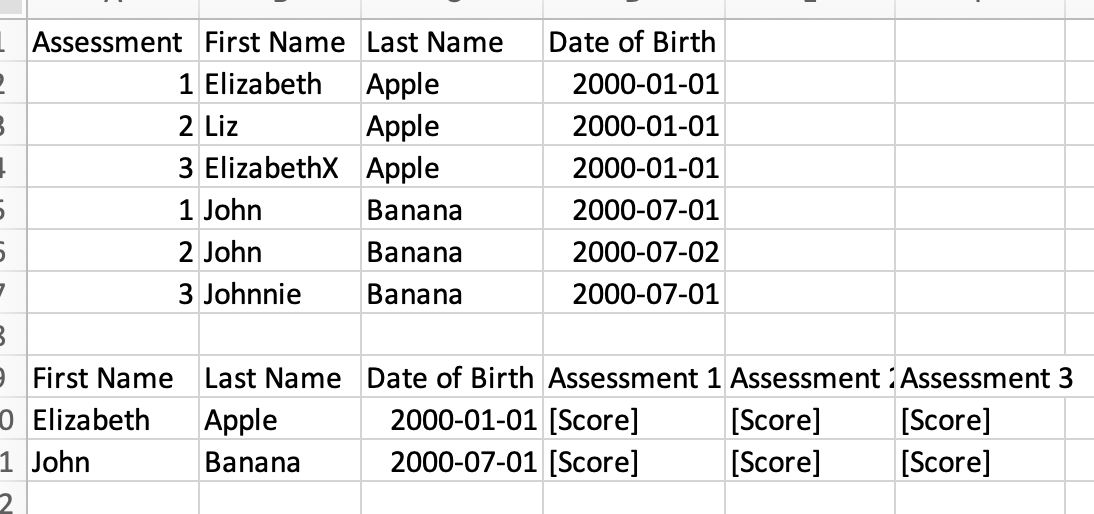
Thanks
Is this possible?
Thanks
Thanks for providing those details Brian. Firstly, I’m not sure of all other requirements here but based purely off the sample documents and information provided, it may be possible to obtain the second table assuming the first table is a collection where the atlas search index exists.
In my example below for the student with a first name of "Elizabeth", I have just added an "assessment" field which contains the score for a particular assessment. This is not what I am recommending the schema to be and is only for demonstration purposes for Atlas search (and in particular, the compound operator, the text operator with fuzzy and synonyms options used).
Sample documents used in the test:
testdb> db.school.find({},{_id:0})
[
{
firstName: 'Elizabeth',
lastName: 'Apple',
DOB: ISODate("2000-01-01T00:00:00.000Z"),
assessment: { a1: 70 }
},
{
firstName: 'Liz',
lastName: 'Apple',
DOB: ISODate("2000-01-01T00:00:00.000Z"),
assessment: { a2: 80 }
},
{
firstName: 'ElizabethX',
lastName: 'Apple',
DOB: ISODate("2000-01-01T00:00:00.000Z"),
assessment: { a3: 90 }
}
]
I am using a default Atlas Search index (named the "scores" index) but have defined Synonym Mappings. For the synonym mappings, I’ve created the "nameSynonyms" mapping below:
testdb> db.schoolsynonyms.find({},{_id:0})
[ {
mappingType: 'equivalent',
synonyms: [ 'elizabeth', 'liz' ]
} ]
Assigning "Elizabeth" to variable "queryFirstName" and details of the $search portion of the pipeline (assigned to var a):
var queryFirstName = 'Elizabeth'
var a =
{
$search: {
index: 'scores',
compound: {
should:[
{
text: {
query: queryFirstName,
path: 'firstName',
fuzzy : {}
}
},
{
text: {
query: queryFirstName,
path: 'firstName',
synonyms:'nameSynonyms'
}
}
]
}
}
}
Output (removed "_id" for brevity):
testdb> db.school.aggregate(a)
[
{
firstName: 'Elizabeth',
lastName: 'Apple',
DOB: ISODate("2000-01-01T00:00:00.000Z"),
assessment: { a1: 70 }
},
{
firstName: 'Liz',
lastName: 'Apple',
DOB: ISODate("2000-01-01T00:00:00.000Z"),
assessment: { a2: 80 }
},
{
firstName: 'ElizabethX',
lastName: 'Apple',
DOB: ISODate("2000-01-01T00:00:00.000Z"),
assessment: { a3: 90 }
}
]
I presume the question here was more based off identifying duplicate names using $search. How you uniquely group and identify a student is a different matter. Hopefully the above example provides a bit of help in determining if this works for your use case.
You may wish to consider cleaning duplicates prior to them being entered into MongoDB if possible. This may assist with inaccuracies that may appear with the above method (for example - consider if an entry had the first name “Lizx”).
Regards,
Jason