Sharded Cluster Configuration of 2 Shards node
collection_name is “test”,
document_content is
for (var i = 0; i <= 10,000; i++) db.test.insert( { index : i } )
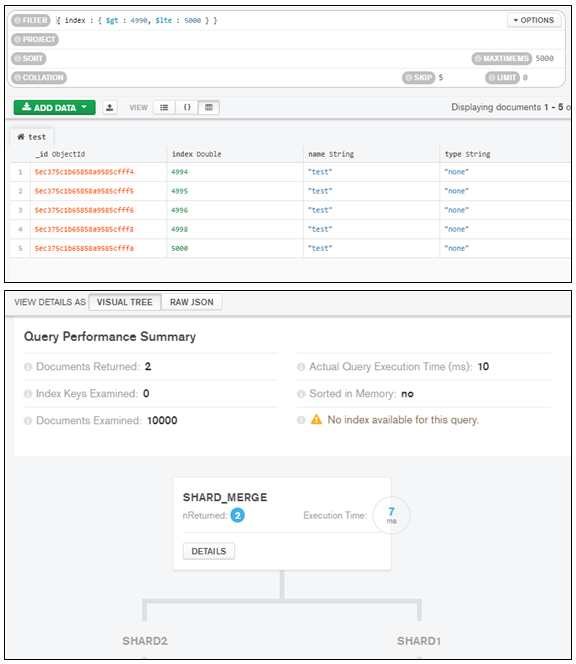
How does this-SHARD_MERGE nReturned: 2- be make final result 5 Documents when i did “db.test.find( { index : { $gt : 4990, $lte : 5000 } } ).skip(5).explain()”?
I don’t understand this sentence.
- If the query specifies a number of records to skip using the skip() cursor method, the mongos cannot pass the skip to the shards, but rather retrieves unskipped results from the shards and skips the appropriate number of documents when assembling the complete result.
1 Like
Hello. What is the Shard Key field (is the collection sharded)? Is there an index created on the index field (in case it is not the shard key)?
Hi. Thank you for reading my post
Shard Key is { “index” : “hashed” }.
The actual query was executed this way in your cluster with two shards:
- Two cursors were opened by
mongos router against the two shards.
- The query predicate
{ index : { $gt : 4990, $lte : 5000 } } was executed on two shards (and returned the cursors to the mongos); mongos has two results.
mongos merged the two results.mongos applied the skip on the merged result.
NOTE: The mongos applies the skip to the merged set of results (not at the shard level).
Based upon the above steps, the query returns the five documents - as expected.
You have generated a query plan with “executionStats”. And, your question is more related to the query plan numbers from the “executionStats”. I will try to explain.
Stages:
- SHARD_MERGE: The stage is for merging results from shards.
- SHARDING_FILTER: The step specifies the documents fetched from a particular shard. The
mongos compares the shard key of the document with the metadata on the config servers to get the documents.
These are some details from the plan’s “executionStats”:
"executionStages" : {
"stage" : "SHARD_MERGE",
"nReturned" : 2,
"shards" : [
"shardName" : "shard01"
"stage" : "SKIP",
"nReturned" : 0,
"stage" : "SHARDING_FILTER"
"nReturned" : 3
"shardName" : "shard02"
"stage" : "SKIP",
"nReturned" : 2,
"stage" : "SHARDING_FILTER"
"nReturned" : 7
]
}
The "nReturned" values from the "stage" : "SHARDING_FILTER" is the actual number of documents returned from the cursors (from each shard). Note the values of "nReturned" are 3 and 7 (sums to 10); the total number of documents returned to the mongos. The skip(5) is applied to this total number of 10 documents, returning 5 documents (the actual result).
If you notice, each of the shards also have a "stage" : "SKIP". And, the "nReturned" value for that shard is actually the skip applied on the "nReturned" value from the "stage" : "SHARDING_FILTER". For example, for the "shard02", the skip is applied on the value 7 and which results as 2. For the "shard01", the skip is applied on 3, which results a negative number and hence shows 0. But, actually the skip is never applied - these are just projections on each shard, I think. The sum of these projections are shown in the "stage" : "SHARD_MERGE", "nReturned" : 2.
You mean the final result could be different from explain().
Thank you for your answer. It really helped me a lot.
Then, can I call this a notation bug?
Thats what I found too ( I created the similar cluster and generated the query plan on the same query and data). I am working with MongoDB version 4.2.3 Enterprise Server.
I don’t know. if its a bug. May be its the way the plan is for shard clusters. I will be looking up for more details and post the findings here (later).
Thank you, Thank you~
Very Very your answer helped me a loooooooooooooooooooooooooooooooooooooooooot