BUT yesterday I broke my server with the master node and the api couldn’t switch to the new master. Although the sysadmin told me that the nodes themselves agreed among themselves which of them is the main one. What could be the problem ? Why can’t the api automatically connect to the new master node ?
I get an error:
ServerSelectionTimeoutError: No replica set members match selector “Primary()”
Hi @Kaper_N_A and welcome in the MongoDB Community !
What does the hosts variable contains?
No routing/firewall issues? You can connect to all the nodes from the server that executes the python code?
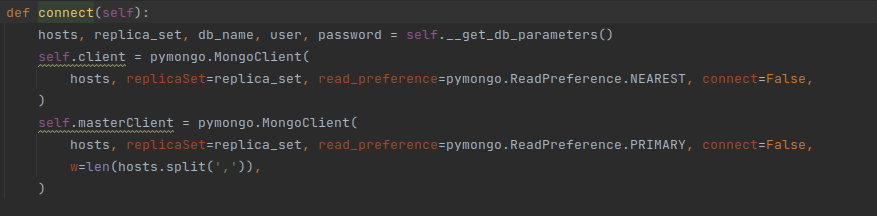
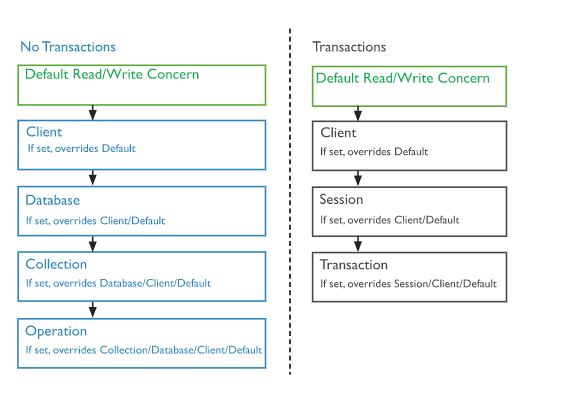
Why are you using 2 different clients client and masterClient here? Looks like you just want to change the readPreference parameter which can be overloaded at the “level” you want. A new readPreference at the database level will overwrite the readPreference defined at the client level, etc. query > collection > database > client to keep it simple.
w, i.e the writeConcern should NEVER be equal to len(hosts.split(',')). If you have 3 nodes, it means that w=3… So it means that as soon as one of your node starts to fail (or you are doing a maintenance operation like an upgrade or daily backup), you cannot acknowledge any write operation on your entire cluster as you cannot write to 3 nodes anymore. That’s not really “Highly Available”. That’s the first FIRST reason for replica set to exist. They provide HA. By doing this, you break this principal and increased your chances of failure compared to running on a single server.
Did this error just last for the time of the election process or did it persisted after the new Primary was elected? If this just happened during the election process, it’s expected as you cannot write to a cluster that doesn’t have a primary… BUT you could have been saved by the automatic retryWrites. Maybe you are actually using it already, by default. But it depends which versions you are running. CF the doc for this.
What’s your serverSelectionTimeoutMS? Looks like your election took longer than your serverSelectionTimeoutMS to find a new Primary. Maybe you could increase it or resolve the issue(s) that prevent your cluster from electing a new Primary in a timely manner.
That’s all the idea & comments I have for now .
I hope this will help a bit.
I don’t speak very good English, but I will try to answer your questions correctly .
I got the old code from the developer for support.
I use a 4-node server.
hosts = ‘db0.mongo_server.com:27017,db1.mongo_server.com:27017,db2.mongo_server.com:27017,db3.mongo_server.com:27017’
yes, there are no routing/firewall issues.
client and masterClient these are different points for methods inside a self-written class for working with databases and data.
As far as I understand, the idea was that methods that modify data in the database should use PRIMARY . And the methods that get the data went to the nearest database and took the data there.
The databases are located in different geolocation.
сlient - used for methods: find, count_documents, aggregate, count.
masterClient - used for methods: find_and_modify, drop, create, count,
masterClient -used only primery.
client -used nearest node.
I can’t say anything about point 4 yet. The code was written by a previous developer.
As far as I understand, w =4, because the previous developer wants the write confirmation to be from all 4 nodes. I understand this in my case . if one node is unavailable, the record cannot be confirmed ?
our version of mongo is 4.0.19 .
Event history:
Our network got into the
DigitalOcean for a couple of seconds, and it only had access to one node, the api couldn’t connect to one node. Then the network appeared, the replica was reassembled and started working. But the api couldn’t connect to the mongobd replica. Everything was solved by restarting the servers using mongobd. When the servers were rebooted, the api was able to connect to mongobd.
our serverSelectionTimeoutMS default 30 seconds
Now I’m trying to understand the situation, maybe it’s something else. But if you give any recommendations, I will be happy, as I am not an expert in mongobd. I can try to throw you a list of code where the database is connected and methods are written for inserting updating and deleting data from the database . If it helps.
I don’t know why your connection failed and why you couldn’t reconnect automatically. This isn’t supposed to work like that and I can’t find the reason without an in-depth analysis of the entire system… which isn’t really possible in a forum…
What I can do though is provide another set of recommendations because I see a lot of issues here.
You should follow MongoDB University free courses. You will learn a lot and get more confidence in your system in just a few days. All the time you invest in here will be paid back in just a few days, I can guarantee that.
4 nodes cluster isn’t a recommended configuration. There is an entire course about Replica Sets in MongoDB University that explains that a lot better than me. Usually it’s 3 or 5 because MongoDB needs to access the majority of the voting members of the replica set to elect a primary and work properly (move forward the majority commit-point…)
With 3 nodes, majority == 2. With 4 or 5 nodes, the majority = 3. So in a config with 4 nodes, if 3 healthy nodes can’t communicate correctly, you have no primary. With 5 nodes, you also need 3 nodes. And if 2 nodes are failing, you are still fine. That’s why 5 is better than 4. And 4 isn’t better than 3. Because with 3 or 4 nodes only 1 node can fail until you cannot have a primary anymore… But you have mathematically more probability to fail with 4 nodes than with 3.
To sum up, unless you are doing something very specific with hidden nodes, this doesn’t make a lot of sense to use 4 nodes instead of 3.
Your developer who developed this application probably didn’t follow the MongoDB University courses and using 2 clients in the same code isn’t the right way to implement this. So I would remove client & masterClient to use only one client CORRECTLY configured with w=“majority” and DEFINITELY NOT w=4 which is clearly a big mistake. Because in that case, if one single node is offline, then you cannot write anymore with your default writeConcern that is set by default at the connection level unless it’s manually overwritten somewhere in a lower level.
My colleague @ado explains very well the priority order of the read and write concerns in his blog post. You can overwrite the level of read of write concern all the way down from the connection up to a specific query. You should use this and specify the options for each collection, db or query instead of creating 2 connections.