i want to run a singleNode replicaset in my development environment.
Should i set voting count as 3 for my replica in this case or voting count should be default which is 1?
Hi @Divine_Cutler, the values for votes, if I’m not mistaken are 0 and 1.
In the case of a single node replica set, since there is only a single node the vote count would need to be set at 1. Changing the vote count, even if it could be greater than 1, wouldn’t have any impact as it’s the only node that can vote. If the machine is running it’s automatically the primary node. If it’s down, well then it doesn’t matter how many votes it gets. 
While a single node replica set might be fine for development purposes, it is strongly cautioned against putting that into production.
What are you trying to accomplish with having a single node replica set?
1 Like
@Doug_Duncan for testing changeEvents in mongodb
Hi @Divine_Cutler, you can follow this documentation to convert your stand alone to a single node replica set.
If you going to create a repl set to test think you need atlest two members to witness replication and voting would only matter if there is more than one member.Else single node I dont think would be much different from a single mongod instance.
@Kirk-PatrickBrown For what @Divine_Cutler is doing(change streams) using a replicaset of one is perfectly fine.
But for a production system where you want some kind of HA, yes you need three nodes. PSA or PSS.
2 Likes
@chris @Doug_Duncan yes, but i do have a doubt when comparing a singleNodeReplicaset with a 3node-replicaset.
When i run a 3node replicaset node1,node2,node3 and if node1 goes down, then among node2,node3 a primary node is elected.
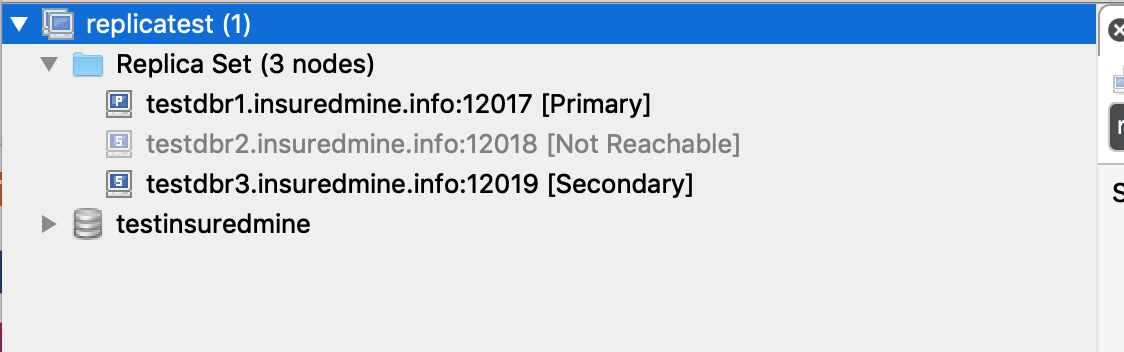
When node2 goes down, then node3 remains as secondary.
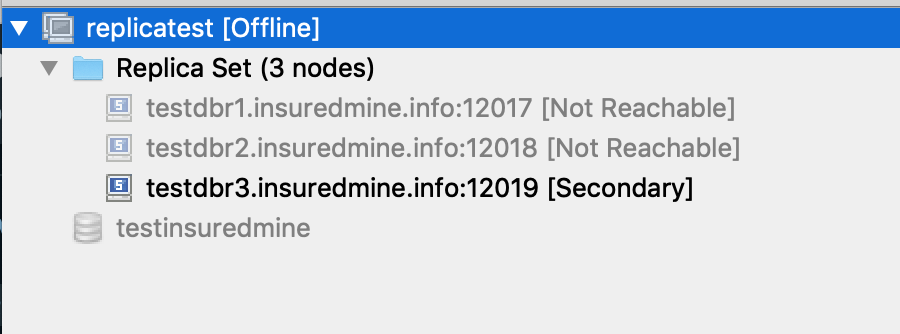
is it possible to have the node3 as a primaryNode when node1,node2 is down? if it is not possible, then i would like to know the reason on how is it possible for a singleNodeReplica set to act as a primaryNode.
@Divine_Cutler when you need to have a majority of the nodes up for a replica set to have a primary. This means in a three node replica set that two members must be available.
Check out the Consider Fault Tolerance section of the Replica Set Architectures document.
Having a single node running from a three node replica set is not the same as running a single node replica set.
1 Like
@Doug_Duncan thank you. i understand this post. but here is my doubt.
Let’s say that i have a singleNodeReplicaSet - it accepts both read/write. then i add 2 additionalnodes to this singleNodeReplicaSet which becomes a 3NodeReplicaSet.
So, Once a singleNodeReplicaSet that runs on its own is converted to 3NodeReplicaSet, i could never scaledown the 3NodeReplicaSet back to a singleNodeReplicaSet and make this singleNodeReplicaSet to accept read/write requests?
@Divine_Cutler, you can force reconfigure your remaining member to remove the downed nodes, but that’s not recommended unless absolutely necessary.
If you’re running a three node replica set and two nodes go down I would first look into why I have two nodes down at the same time. While bad things can, and do, happen, it’s rare in my experience for two of the three nodes in a replica set to go down at the same time. Your time is better spent trying to bring the downed nodes back online. If you can get just one of them up and running you have a majority again and one will be promoted to PRIMARY status.
Forcing your three node replica set back down to a single node replica set is very dangerous, especially in a production environment as you’ve lost any sort of HA. I would strongly caution against doing that.
@Doug_Duncan thank you.
i have one more question and it troubles me a little bit.
Please assume this scenario.
i have a 3nodeReplicaSet (node1,node2,node3). There are no problems in the configuration, so everything is functioning as expected.
Assume, there are huge number number of write/update/delete operations going on.Then, at one point, the oplog collection in primaryNode(node1) reached the memory limit and as it is a capped collection, the old data in oplog collection gets overridden and the data from oplog gets synced successfully to the secondaryNodes(node2,node3) without any problems.
Suddenly Node3 goes down for some reason(may be the developer shut it down), but the application is functioning successfully as node1,node2 are running fine. But still there are huge number of write/update/delete ongoing.
My understanding of data sync between nodes in replicaSet is, the secondaryNodes replicate the data from primaryNode by reading the oplog collection of the primaryNode.
Coming back to our scenario,
Assume, that the oplog got filled completely thrice counting from the moment node3 was down till the moment node3 was started again. Now, if the node3 was started again, then
- Would there be any error thrown while syncing data to node3?
- Will all data from primaryNode get synced to node3? (i assume not)
- If all data from primaryNode doesnot sync to node3, then how to sync data to node3 and make it up and running?
@Doug_Duncan i got answer for my above question.
even though i went throught that article previously, i forgot about it yesterday
1 Like
Hi,
What is this tool name ?
Can you please expand on why this is the case when all 3 nodes would be running on a single VPS anyway? What is the failure case that a single node replica does not catch that a 3-node replica does catch - when the context is a single physical server that regularly does a mongodump?
Thank you.
Running all the nodes of a replica set on the same piece of hardware is really not the best because you have a single point of failure.
An upgrade is one scenario that multi-node replica set, even on single hardware, is something that can be done without down time. With a single node replica set you cannot.
I’m curious if @Doug_Duncan concurs…
This doesn’t really answer the question; I realize that the hardware is a single point of failure running with and without replicas (if they’re all contained on the same hardware). The question is: how or why is a single node replica more dangerous than mongodb running without replicas?
If we only want to scale vertically in production, then why isn’t a single node replica usable in production (considering the same careful backup process we use with our single node non-replica mongodb)? The point is to be able to use transactions.
This is not the same question and it is not what was said. What was said was that running a single node replica set was risky.
A single node replica set IS NOT MORE dangerous than an instance without replication. They represents the SAME HIGH risk of losing data. Replication is needed for both transactions and change streams.
Sorry for the lack of clarity on the question.
If that is true, then why is it officially OK to run mongodb in production without replicas and running a single node replica in production is listed as only for development environments / testing (everywhere I’ve seen it talked about so far)? Surely, then, it is a reasonable workaround in production for the transaction support issue?
Thanks again for entertaining my inquieries.
I did not know it was Okay to run mongod in production without replication. What I am aware is that the recommendation is PSS.