Hi everyone.
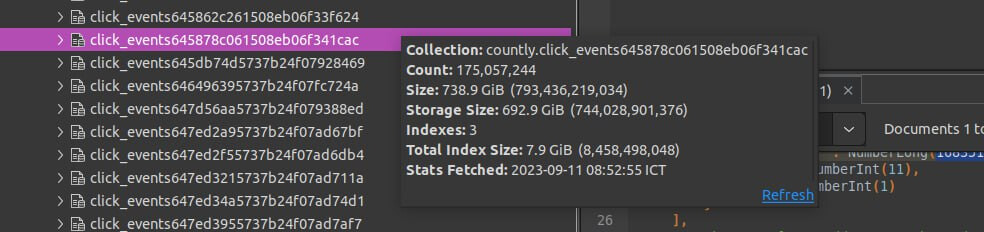
I have a huge collection as below image. Currently, I want to reduce the size of this collection without deleting documents in the collection. Can someone give me some recommendations to resolve this problem??
That storage to data ratio seems high…what are you storing and whats the server version and storage engine?
Hi @John_Sewell, I am storing the click events information which is tracked from websites. This is connection info
Can you do db.collectionName.stats() to get the storage information about the collection?
The only way to reduce the size of the collection would be to delete or archive documents, or store less data in each document. It looks like the average document size is 4kb, which is relatively large for a click event. What data are you storing?
@John_Sewell this is storage information about my collection
click_events_cac_stats.txt (30.5 KB)
@Peter_Hubbard, I store click events information. This is an event in my collection
{
"collection": "click_events645878c061508eb06f341cac",
"query": "insert",
"data": {
"events": [
{
"key": "[CLY]_action",
"count": 1,
"segmentation": {
"type": "click",
"x": 1001,
"y": 333,
"width": 1920,
"height": 931,
"view": "/xx/xx/xxx",
"parent": {
"x": 0,
"y": 0,
"width": 0,
"height": 0
},
"domain": "xxxxxx.xx.x"
},
"timestamp": 1694422960299,
"hour": 16,
"dow": 1
}
],
"app_key": "f977476dde83086c0eb9a69d14f1a3ed52a937a7",
"device_id": "d0940293-d24e-4632-baf7-fb3735089542",
"sdk_name": "javascript_native_web",
"sdk_version": "22.06.0",
"t": 1,
"timestamp": 1694422960300,
"hour": 16,
"dow": 1,
"raw_html": null,
"screen_size_type": "Desktop1920",
"_id": "64fed7b0b92d6649b012cc3c"
}
}
From the stats you’re using snappy as the compression routine, you could try making a new DB with different compression zlib etc and then copying a sample of the data into that and check what the compression rates you get are like.
Obviously there are upsides and downsides to different compression engines so read around that, I’m surprised by the low compression of the data though in your collection, currently using snappy in prod we’re getting a compression ratio of about 7:1 so 14TB of data requires 2TB of storage.
I know not all data is compressible but you’re basically getting no compression on your data.
I’ve not played about enough with compression at that level to suggest much more I’m afraid, perhaps one of the Mongo team can see something amiss in the stats output.
You may try to see if the bucket pattern is applicable.
You may also make your schema less verbose by transforming some of your x,y,width,height fields to an array such as making
"parent": {
"x": 0,
"y": 0,
"width": 0,
"height": 0
},
"parent": [ 0, 0, 0, 0 ] ,
1 Like
Hii @Peter_Hubbard ,plz give solution to this Performance issue,I am facing… I am getting performance issue with this aggregation pipeline?This almost takes 20 sec to give response of 30000 records
Thanks for your help @John_Sewell, I will try with zlib