I hope we can make this more a discussion because i know that there is no right or wrong here.
I am trying to optimize a special collection that serves as a fulltext index over other collections. There are many reasons for that, but I don’t want to dig too much into that. Btw: I have also considered other solutions, like Algolia, OpenSearch, Atlas full text (which seems to be OpenSearch).
My problem is the pure size of the index. As you can see it is much bigger than the actual data:
Due to my business model I have only one collection for all customers. My goal here is to improve performance. I have realized that the most performance issue is when you search for very common words, that could be part of many texts, e.g. just “test”, because this actually drives the performance the most.
My model looks like this:
public sealed class MongoTextIndexEntity
{
[BsonId]
public string Id { get; set; }
public string DocId { get; set; }
[BsonElement("_ci")]
public string ContentId { get; set; }
[BsonElement("_ai")]
public Guid AppId { get; set; }
[BsonElement("_si")]
public Guid SchemaId { get; set; }
[BsonElement("t")]
public List<MongoTextIndexEntityText> Texts { get; set; }
}
public sealed class MongoTextIndexEntityText
{
[BsonElement("t")]
required public string Text { get; set; }
[BsonElement("language")]
public string Language { get; set; } = "none";
}
- AppId is like a tenant ID.
- SchemaId defines the kind of content, most customers have one schema with many content items (500 - 50000) and a few more schemas with relatively few content item (~100).
My query uses almost all of these fields, so the following fields are part of the index in this order:
- AppId (_ai)
- SchemaId (_si)
I have made a small test application where I can play with different shapes of the index and performance improvements. For this I have test data in a file and use that to test different approach with the same data all the time. Each entry has a text with 1500 random words (not real words, just concatenation of characters).
First Optimization
The first optimization I did was to ensure that we use more compact binary representations everywhere and this has actually helped a lot:
Version 2 has way smaller index than version 1.
Next Attempt
The second attempt is to reduce the number of fields in the Index. For my understanding there are 2 reasons why an index is fast in general:
- The index size is usually way smaller than the data size. This is not the case here.
- The index structure is optimized for the queries (usually binary trees), which means that the algorithmic complexity is usually better and the if the index does not fit into memory, we have to load less pages from the disk.
Because the index is way bigger I wonder if the data size counters the advantages of the additional index fields.
So I made a few tests:

- The index in Version 3 only contains the text
- The index in Version 4 also contains the app ID, but not the schema ID.
I am running the same query on all tests and the results are interesting:
The first test uses a word that is only part of a single result. The second test uses a word that is part of all items. So the difference is big.
V2 Specific elapsed: 00:00:00.0699443
V2 Hello elapsed: 00:00:02.5310926
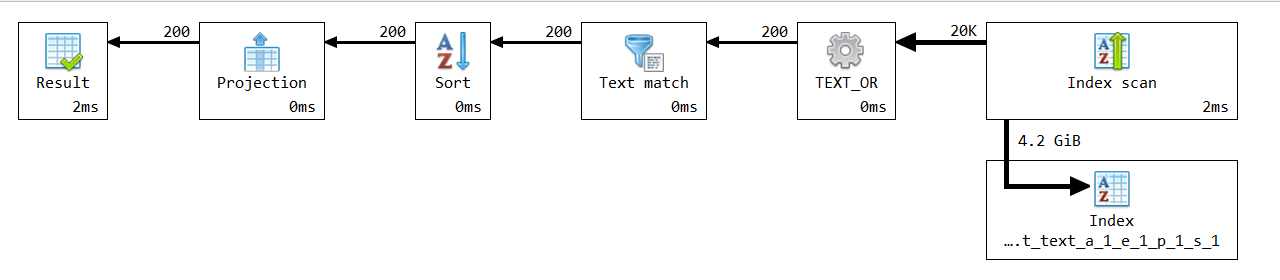
V3 Specific elapsed: 00:00:00.0661136
V3 Hello elapsed: 00:00:08.8725249

V4 Specific elapsed: 00:00:00.0698579
V4 Hello elapsed: 00:00:02.1809471

What is very interesting is the following:
-
V3 is way slower due to the missing app id. As you can see it has to fetch way more documents which makes it slow.
-
V4 is faster than V2, even though it has to fetch more documents.
For me it seems that my theory about the index is somehow correct to an extend. So V4 IS faster because of the smaller index size and because it does not have to fetch that many documents from disk. But I am not
sure if this can be transferred to production system where the number of content items per app is very different between customers.
Therefore I tested another setup where I have one app, one schema and 10.000 content items. The results are:
V2 Specific elapsed: 00:00:00.0705089
V2 Hello elapsed: 00:00:30.9860188
V3 Specific elapsed: 00:00:00.0725020
V3 Hello elapsed: 00:00:30.5357975
V4 Specific elapsed: 00:00:00.0757402
V4 Hello elapsed: 00:00:04.5597619
- V2 and V3 are almost identical in performance, because there is only one APP ID. But the indexes have very different sizes.
- V4 is super fast, no idea why.

I am very confused right now. V4 is the clear winner, but I don’t understand why this is the case. I have run the tests in isolation and together and also restarted my docker container to verify my results, it seems to be independent of that, so the performance is probably not related to the cache hit ratio and the memory usage of my container that much.