Hello guys, could anyone give me some insights on how to solve my DB’s performance issue?
This is the scenario: I have an API endpoint that will return an array of objects, and each object contains a set of coordinates:
[
{
cid: 1234,
name: "john",
latitude: -27.98161,
longitude:-66.71234
},
...
]
Since I need to collect the coordinates to build a track, I’m fetching this data every 15 seconds and append the coordinates to the document, this is a simplified version of my schema:
const trackSchema = new mongoose.Schema(
{
cid: {
type: Number,
},
track: [
{
latitude: {
type: Number
},
longitude: {
type: Number
},
}
}
)
I have a function that removes the documents from the collection if they are not in the latest fetched data, however, most of the time data with the same cid will be fetched over hours, which means a HUGE track array will be built. In fact, it really didn’t take that long to slow my response time from 4 seconds to almost 2 minutes. The first query after I drop the collection and import data would respond within 5 seconds, and it’s slower and slower, In fact, it really didn’t take that long to slow my response time to almost 2 minutes.
This is the result if I call TrackModel.find({}):

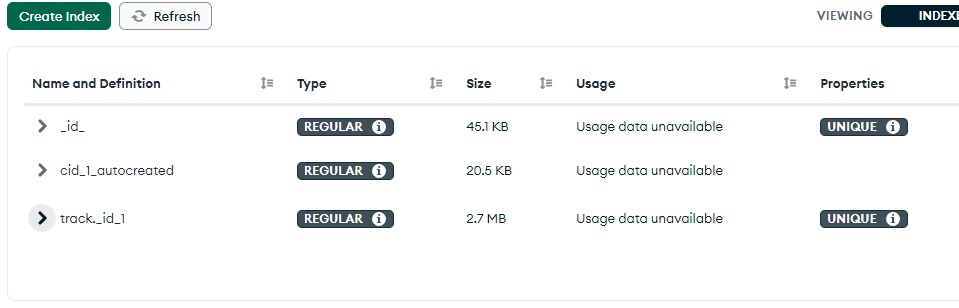
I’ve ran
explain("executionStats") and find({}) in mongosh, this is the results:
I don’t know why the executionTimeMillis is showing 6 but the actual response time would take over a minute.
So my question is: what is the best practice to solve this issue? I’m thinking of creating another collection solely to store track objects, and associate the object with cid, meanwhile maintaining an order when I query the data. But I’m not sure if this is the best way to do this.