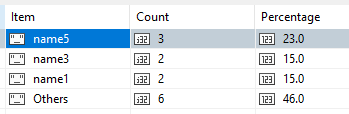
Thank you for your help. $facet step with $limit, $skip and $group does good job. But unfortunately i can’t use it because in fact this computation is part of another higher level $facet step. Original documents have much more fields than just name, and i have to calculate different statistics on same amount of matched docs.
This is how it looks in general:
{
$match: {} // some match
},
{
$facet: {
name: [] // topic of our discussion,
category: [],
type: [],
...
}
},
{
// some formatting steps of results from above steps.
}
I found an option to get this sort of statistics that works in my case:
{
$facet: {
name: [{ $sortByCount: "$name" }],
...
}
},
{
$set: {
name: {
$reduce: {
input: {
$map: {
input: {
$zip: {
inputs: [
"$name",
{
$range: [
0,
{
$size: "$name",
},
],
},
],
},
},
as: "item",
in: {
$mergeObjects: [
{
$arrayElemAt: [
"$$item",
0
],
},
{
index: {
$arrayElemAt: [
"$$item",
1
],
},
},
],
},
},
},
initialValue: {},
in: {
$mergeObjects: [
"$$value",
{
$cond: [
{
$gt: [
"$$this.index",
3
],
},
{
other: {
$add: [
{
$cond: [
"$$value.other",
"$$value.other",
0
],
},
"$$this.count",
],
},
total: {
$add: [
{
$cond: [
"$$value.total",
"$$value.total",
0
],
},
"$$this.count",
],
},
},
{
top: {
$concatArrays: [
{
$cond: [
"$$value.top",
"$$value.top",
[]
],
},
[
{
_id: "$$this._id",
count: "$$this.count",
},
],
],
},
total: {
$add: [
{
$cond: [
"$$value.total",
"$$value.total",
0
],
},
"$$this.count",
],
},
},
],
},
],
},
},
},
},
},
{
$set: {
name: {
$concatArrays: [
{
$cond: [
"$name.top",
{
$map: {
input: "$name.top",
as: "item",
in: {
$setField: {
field: "percentage",
input: "$$item",
value: {
$multiply: [
{
$divide: [
"$$item.count",
"$name.total"
],
},
100,
],
},
},
},
},
},
[],
],
},
{
$cond: [
"$name.other",
[
{
_id: "__other__",
count: "$name.other",
percentage: {
$multiply: [
{
$divide: [
"$name.other",
"$name.total"
],
},
100,
],
},
},
],
[],
],
},
],
},
},
}
It can be not as optimal as possible, but for now it works. Feel free to give your feedback