I am looking for a query in mongodb which is similar to the below sql
Select count(users),count(issues), count(fingercnt)
from issuedetails
group by created_date
I am looking for a query in mongodb which is similar to the below sql
Select count(users),count(issues), count(fingercnt)
from issuedetails
group by created_date
Hi @vinodkumar_Mallikarj! Welcome to the community!
MongoDB allows you to create Aggregation Pipelines. Aggregation Pipelines are handy when you want to perform analytical queries or combine data from more than one collection.
You can use the $count and $group stages as part of the Aggregation Pipeline.
Hi @vinodkumar_Mallikarj and welcome onboard ![]() !
!
I think what you are looking for here is $facet which is part of the Aggregation Pipeline.
Here is an example that I executed on the MongoDB Open Data COVID-19 cluster on the collection covid19.global_and_us.
This collection contains all the COVID-19 stats from different countries in the world, sub-divided in states then counties.
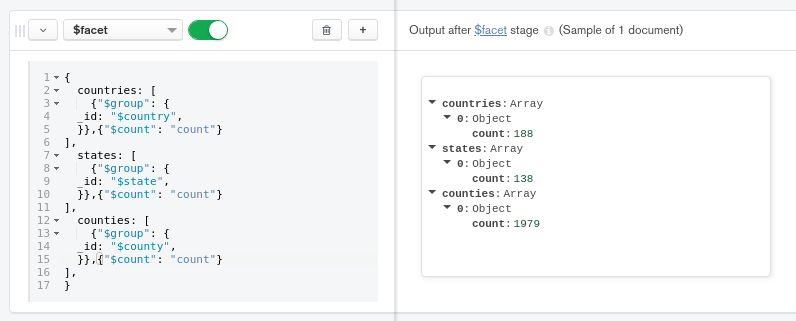
With the following query, I’m counting how many countries, states and counties are in this collection.
[
{
'$facet': {
'countries': [
{
'$group': {
'_id': '$country'
}
}, {
'$count': 'count'
}
],
'states': [
{
'$group': {
'_id': '$state'
}
}, {
'$count': 'count'
}
],
'counties': [
{
'$group': {
'_id': '$county'
}
}, {
'$count': 'count'
}
]
}
}
]
The result looks like this:
You could also choose to run these 3 sub-pipelines separately in 3 separated queries but the $facet stage makes it possible to run them all at once.
Cheers,
Maxime.
Hello
I think this does the same.
Group by created_date.And count the non null values on the fields.
Example data
[
{
"user": "",
"issues": "",
"finger": "",
"created_date": "2019-01-01T00:00:00Z"
},
{
"user": "",
"issues": null,
"finger": "",
"created_date": "2019-01-01T00:00:00Z"
},
{
"user": "",
"finger": "",
"created_date": "2019-01-02T00:00:00Z"
},
{
"user": "",
"issues": "",
"finger": null,
"created_date": "2019-01-02T00:00:00Z"
},
{
"user": "",
"issues": "",
"created_date": "2019-01-02T00:00:00Z"
},
{
"user": "",
"issues": "",
"created_date": "2019-01-02T00:00:00Z"
}
]
The command.The pipeline is the code to use in any driver.
It can be much sorter if you use a function,because its 3x the same code.
It groups by created_date,and counts excluding missing fields or fields with null values
{
"aggregate": "testcoll",
"pipeline": [
{
"$group": {
"_id": "$created_date",
"user_count": {
"$sum": {
"$cond": [
{
"$or": [
{
"$eq": [
{
"$type": "$user"
},
"missing"
]
},
{
"$eq": [
"$user",
null
]
}
]
},
0,
1
]
}
},
"issues_count": {
"$sum": {
"$cond": [
{
"$or": [
{
"$eq": [
{
"$type": "$issues"
},
"missing"
]
},
{
"$eq": [
"$issues",
null
]
}
]
},
0,
1
]
}
},
"finger_count": {
"$sum": {
"$cond": [
{
"$or": [
{
"$eq": [
{
"$type": "$finger"
},
"missing"
]
},
{
"$eq": [
"$finger",
null
]
}
]
},
0,
1
]
}
}
}
},
{
"$addFields": {
"created_date": "$_id"
}
},
{
"$project": {
"_id": 0
}
}
],
"maxTimeMS": 0,
"cursor": {}
}
Results (missing or null are excluded on counting)
[
{
"user_count": 4,
"issues_count": 3,
"finger_count": 1,
"created_date": "2019-01-02T00:00:00Z"
},
{
"user_count": 2,
"issues_count": 1,
"finger_count": 2,
"created_date": "2019-01-01T00:00:00Z"
}
]
Your query is different than mine in the sense that you are only grouping by one criterion and then counting different fields so it works with a single pipeline.
In my case, I’m grouping by 3 different criteria “at the same time” so I need to use $facet to run 3 different $group over the same input.
Maybe you will need it some day 
Cheers,
Maxime.
I used the below query, it is giving the output.
db.Issues.aggregate(
[
{
"$project": {
"_id": NumberInt(0),
"issueid": "$issueid",
"program_name": "$fin.program_name",
"issue_type": "$issue_type",
"client_name" : "$client.client_mnemonic",
"zipfile_dt" : "$zipfile.zip_file_dt_tm",
"user_name" : "$user.user_name",
"finid" : "$fin.finid"
}
},
{
$match: {"client_name" :{$in: ["ACL","CEC"]},"zipfile_dt" : "2020-01-01"}
},
{
$group: {
_id: "$zipfile_dt",
Fincnt: {$addToSet: "$finid"}
}
},
{
$project: {
uniqueFinCount:{$size:"$Fincnt"}
}
}
]
)
But in the above query i can only able to retrieve the distinct count of only one column, for multiple columns i am facing the issue. If I add addtoset on one more column, the previous values will overwrite and give the count as 0
The query is giving the overall count, assume there are total 7 records and out of 7 if we use distinct count then it should return 3.
I want the count 3 instead of 7.
Hello
What do you mean overriden and get count as 0.
$group: {
_id: “$zipfile_dt”,
Fincnt: {$addToSet: “$finid”},
Issuecnt: {$addToSet: “$issueid”}
}
Add fields like that?
Maybe like that?
$group: {
_id: “$zipfile_dt”,
acount: {$addToSet: {"finid" : “$finid”, "issueid" : "$issueid"}}
}
If you give example data in,how they should become,and your query,it could help alot.
$match should be the first stage in your aggregation so it can benefit from the index {zipfile_dt:1, “client_name”:1} that you should create for this query to run fast.
After a $project stage, your index won’t work anymore.
Always $match and $sort first if you can do so.
Hello : )
I think you want count distinct in each field,in the first answer,it was about count only.
Because in that sql query you didnt add the distinct.
I used “$group”: {"_id": null …} because you already kept only 1 date on match stage,
so here all collection will be 1 group.
Maybe this is what you want.
Example data.
Data in
[
{
"program_name": "E",
"user_name": "B",
"zipfile_dt": "2019-01-01"
},
{
"program_name": null,
"user_name": "B",
"zipfile_dt": "2020-01-01"
},
{
"program_name": "E",
"user_name": "B",
"zipfile_dt": "2020-01-01"
},
{
"program_name": "C",
"user_name": "B",
"zipfile_dt": "2020-01-01"
},
{
"program_name": "D",
"user_name": "A",
"zipfile_dt": "2020-01-01"
},
{
"program_name": "D",
"user_name": "A",
"zipfile_dt": "2020-01-01"
},
{
"program_name": "D",
"user_name": "A",
"zipfile_dt": "2020-01-01"
}
]
Query
{
"aggregate": "testcoll",
"pipeline": [
{
"$match": {
"$expr": {
"$eq": [
"$zipfile_dt",
"2020-01-01"
]
}
}
},
{
"$group": {
"_id": null,
"program_name_array": {
"$addToSet": "$program_name"
},
"user_name_array": {
"$addToSet": "$user_name"
}
}
},
{
"$project": {
"_id": 0
}
},
{
"$project": {
"users_count": {
"$size": "$user_name_array"
},
"program_count": {
"$size": "$program_name_array"
}
}
}
],
"maxTimeMS": 0,
"cursor": {}
}
Result
{
"users_count": 2,
"program_count": 4
}
If you want to not count the null values
In the above query replace the last project with that,it filters the array and keeps
only the not nulls,you can make a function and generate the ,here is the same code 2x
{
"$project": {
"users_count": {
"$size": {
"$filter": {
"input": "$user_name_array",
"as": "m",
"cond": {
"$not": [
{
"$eq": [
"$$m",
null
]
}
]
}
}
}
},
"program_count": {
"$size": {
"$filter": {
"input": "$program_name_array",
"as": "m",
"cond": {
"$not": [
{
"$eq": [
"$$m",
null
]
}
]
}
}
}
}
}
}
Result (program_name null value wasn’t counted)
{"users_count":2,"program_count":3}
Hope this time helps
This topic was automatically closed 5 days after the last reply. New replies are no longer allowed.