I’m working with relatively small (10k documents) database and need to combine collections in an aggregation pipeline. I’m using Compass for this, and it is timing out at a $group stage, but I can’t quite understand the reason.
My goal is to create a view showing the number of paid/free/total memberships, and number of paid/free/total members. (members are different than memberships).
Here is an example of the first doc:
account:
{
_id: '1234566788',
url: 'www.site.com',
memberships: [
{0:
{membershipType: 'free'},
{1:
{membershipType: 'paid'}
]
}
The second doc:
members:
{
_id: 'xxxxxxx',
site: '12345667', // maps to _id from other doc
stripeInfo: {
customer: 'xyz' // This field will not exist if it is a free account
}
}
… and this is the pipeline:
[
{
'$addFields': {
'total_memberships': {
'$cond': {
'if': {
'$isArray': '$memberships'
},
'then': {
'$size': '$memberships'
},
'else': 'NA'
}
}
}
}, {
'$project': {
'_id': 1,
'url': 1,
'memberships': 1,
'total_memberships': 1
}
}, {
'$unwind': {
'path': '$memberships',
'preserveNullAndEmptyArrays': True
}
}, {
'$group': {
'_id': {
'_id': '$_id',
'url': '$url'
},
'total_memberships': {
'$sum': 1
},
'count_of_free_memberships': {
'$sum': {
'$cond': [
{
'$eq': [
'$memberships.membershipType', 'free'
]
}, 1, 0
]
}
},
'count_of_paid_memberships': {
'$sum': {
'$cond': [
{
'$eq': [
'$memberships.membershipType', 'paid'
]
}, 1, 0
]
}
}
}
}, {
'$lookup': { // connecting to members
'from': 'members',
'localField': '_id._id',
'foreignField': 'site',
'as': 'members'
}
}, {
'$unwind': {
'path': '$members',
'preserveNullAndEmptyArrays': True
}
}, {
'$addFields': {
'is_paid_member': {
'stripeInfo': {
'customer': {
'$ifNull': [
1, 0
]
}
}
},
'is_free_member': {
'stripeInfo': {
'customer': {
'$ifNull': [
0, 1
]
}
}
}
}
}, {
'$project': { // cleaning up/ flatening output
'_id': '$_id._id',
'url': '$_id.url',
'total_memberships': 1,
'count_of_free_memberships': 1,
'count_of_paid_memberships': 1,
'is_paid_member': '$is_paid_member.stripeInfo.customer',
'is_free_member': '$is_free_member.stripeInfo.customer'
}
},
/* **This group is where the pipeline is timing out** */
{
'$group': {
'_id': {
'_id': '$_id',
'url': '$url',
'count_of_free_memberships': '$count_of_free_memberships',
'count_of_paid_memberships': '$count_of_paid_memberships',
'total_memberships': '$total_memberships'
},
'free_members': {
'$sum': '$is_free_member'
},
'paid_members': {
'$sum': '$is_paid_member'
},
'total_members': {
'$sum': 1
}
}
}, {
'$project': {
'_id': '$_id._id',
'url': '$_id.url',
'free_memberships': '$_id.count_of_free_memberships',
'paid_memberships': '$_id.count_of_paid_memberships',
'total_memberships': '$_id.total_memberships',
'free_members': 1,
'paid_members': 1,
'total_members': 1
}
}, {}
]
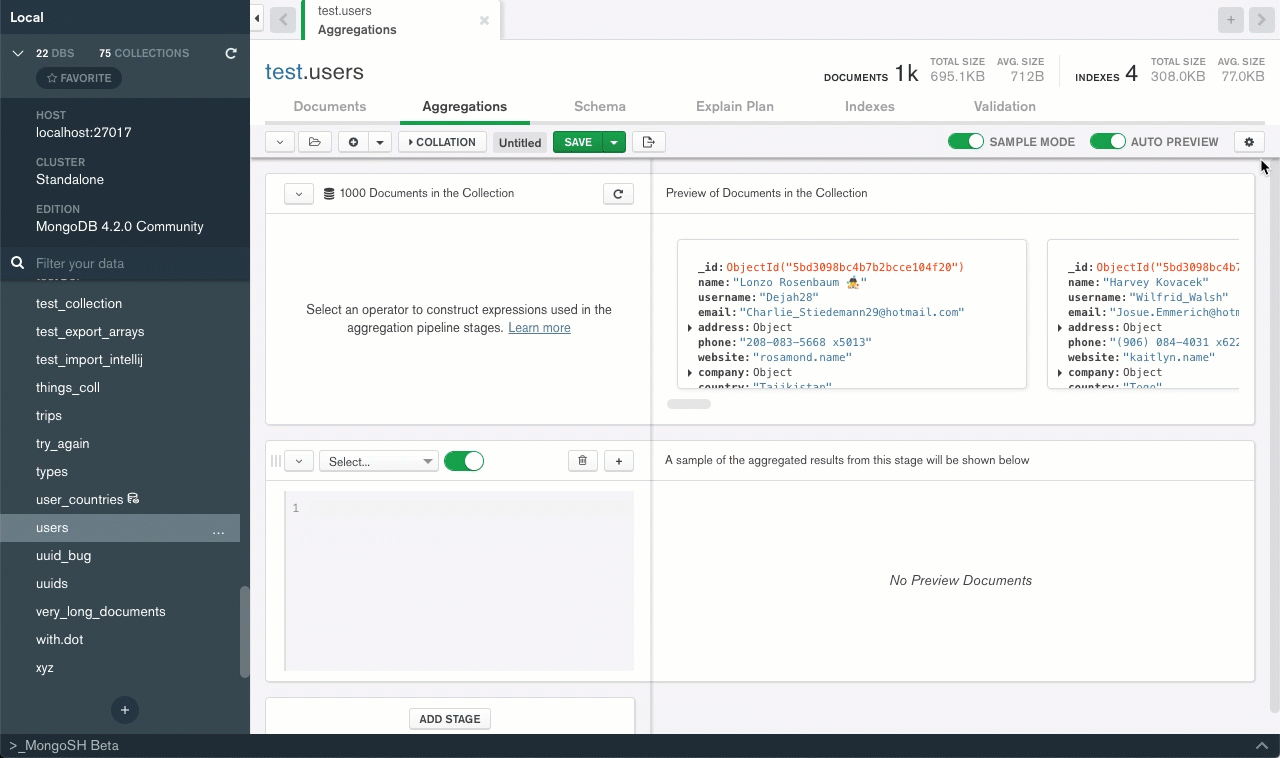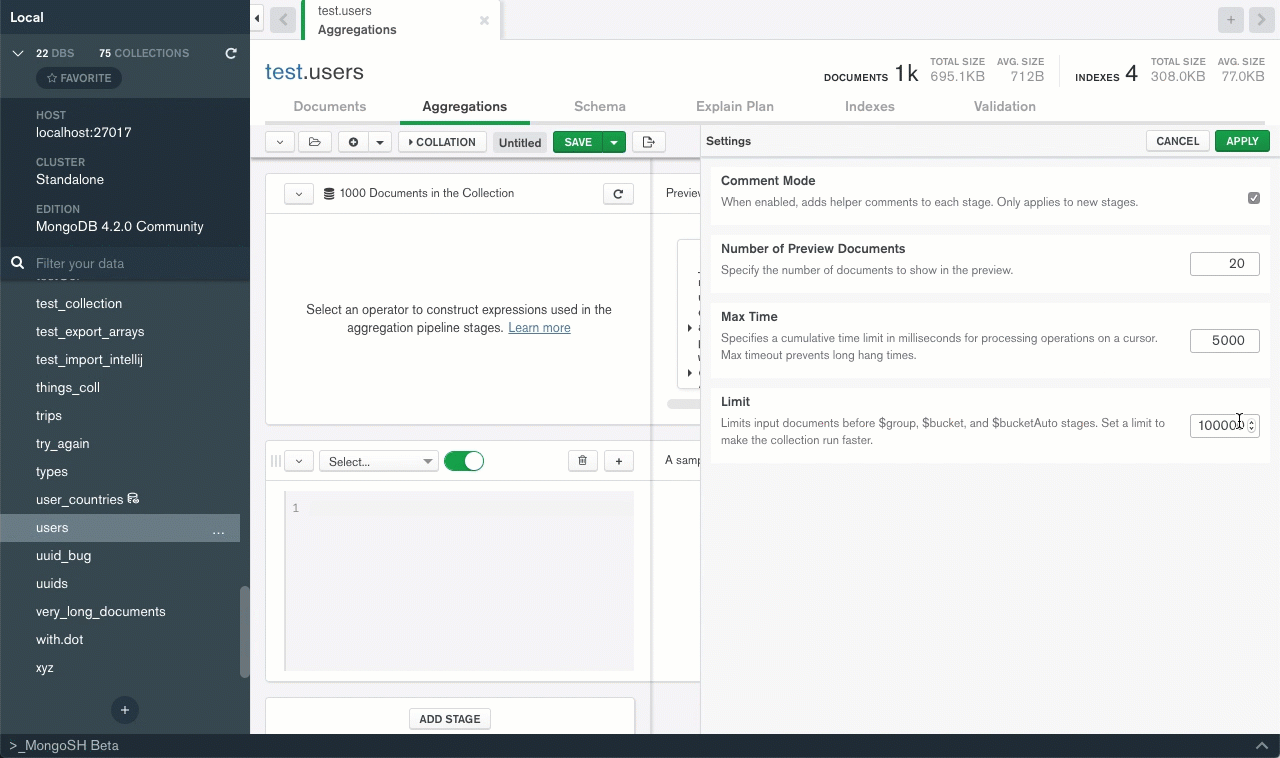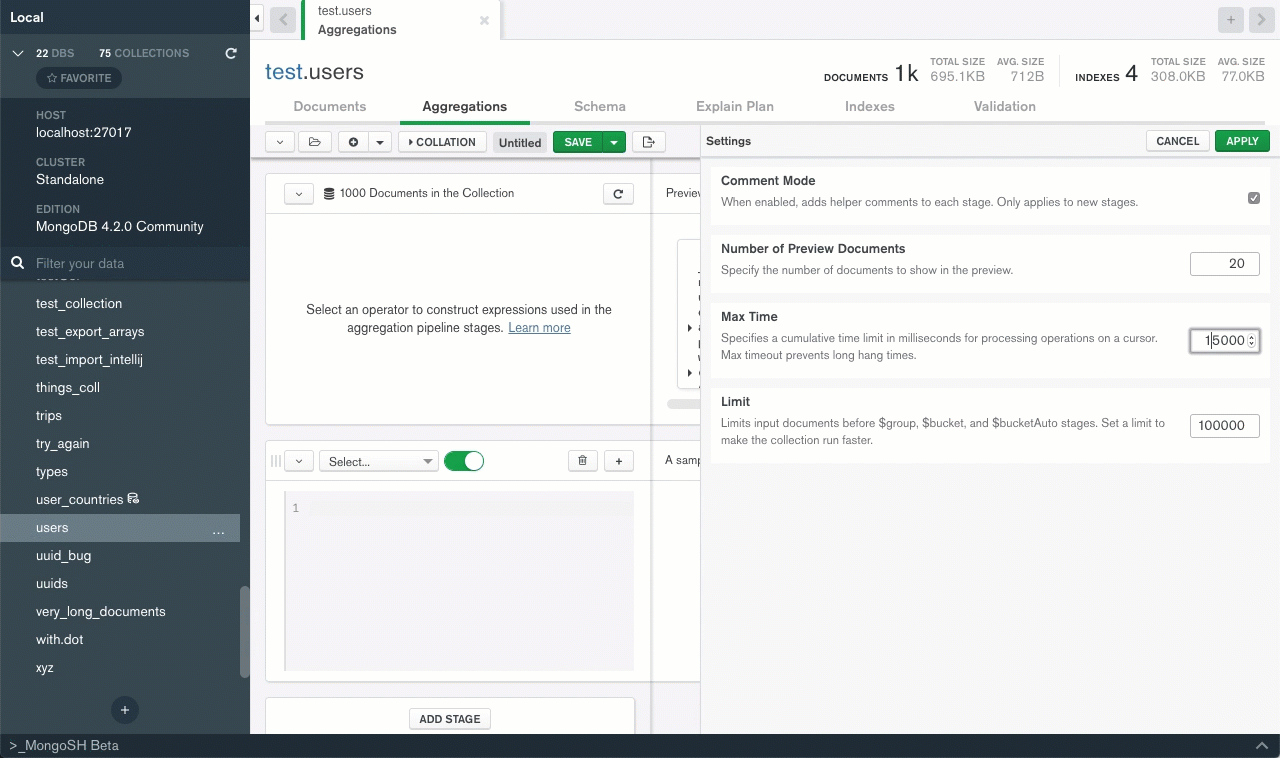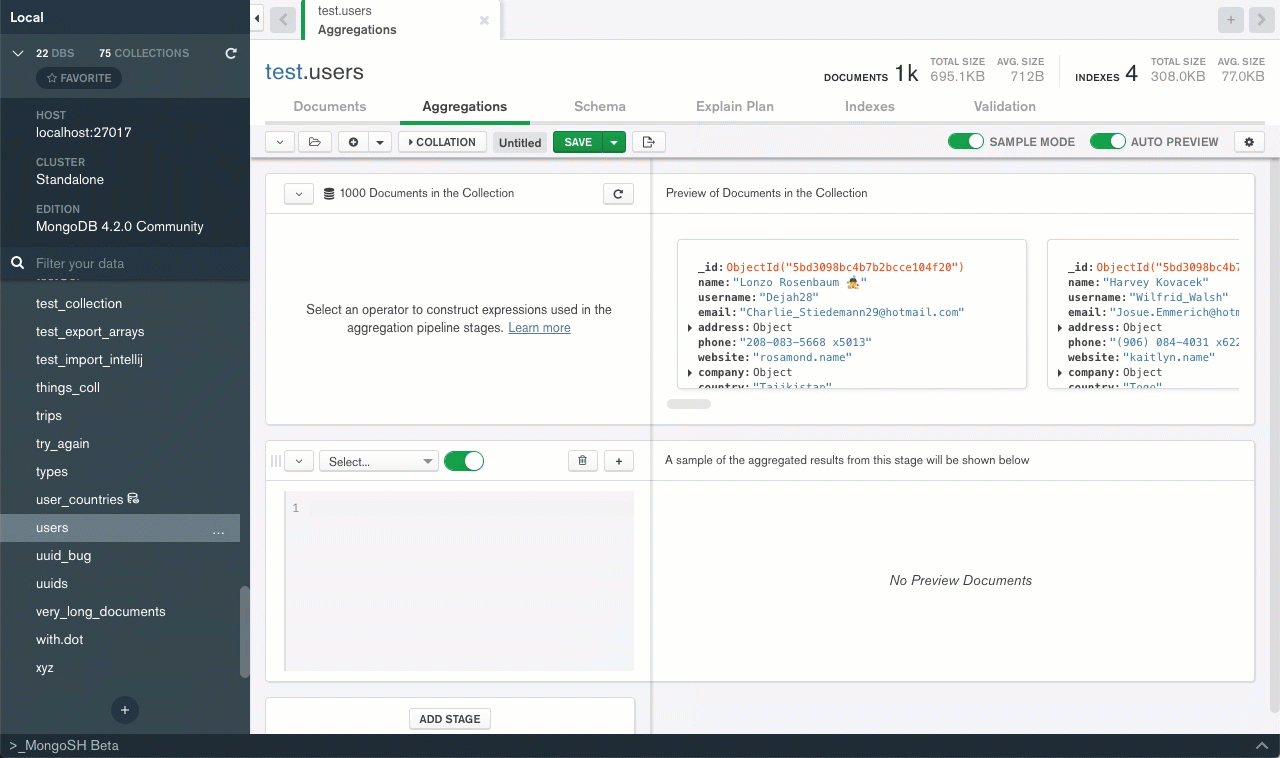
This Aggregation pipelinen will run if I limit the input to 1000, or increase the max time from 5000 to 20000, but otherwise will throw :
error in $cursor stage ::caused by:: operator exceeded time limit
I appreciate any advice in optimizing this aggregation pipeline.