Hi Jason,
Wow, thanks for your great help! Really appreciate it ![]()
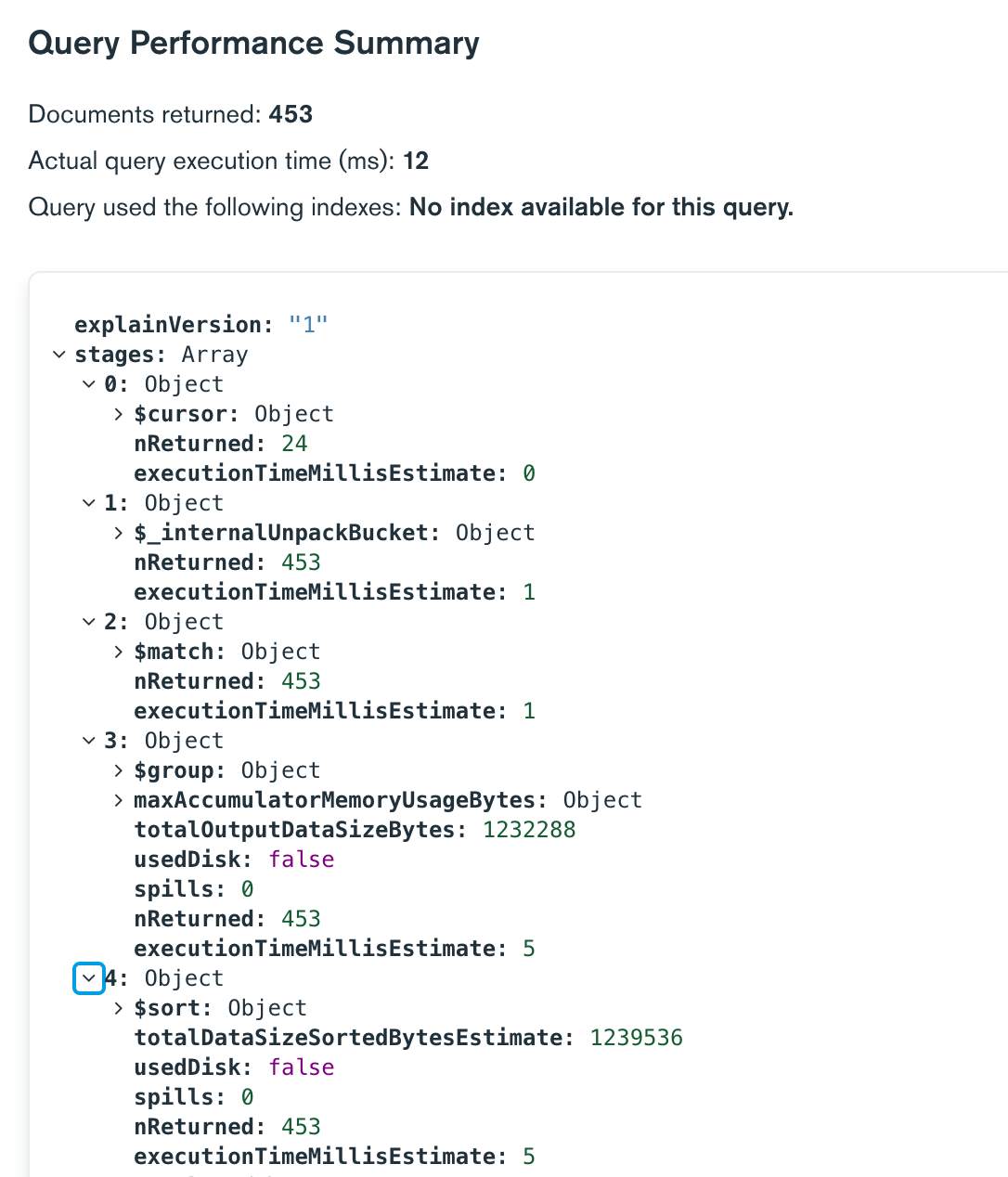
I tested your approach. Unfortunately, performance depends on the maximum number of documents as internalUnpackBucket needs to unpack all documents and subsequent grouping is performed on all of them. So this wouldn’t scale well? Moreover, the sort operation might fail eventually? Below is an example with 12108 transactions to be unpacked and grouped. We retrieved the last 200 transactions.

Using the approach in my first post is significantly faster, since we need to unpack the required documents only. In the given time frame the last 453 documents have been retrieved, grouped and sorted in 12 ms. Note that Compass used the index, but didn’t indicate it. However, we would under fetch or over fetch and would need to use limit to cap at 200 documents…
This is why I thought just going through the system.bucket might help, but that doesn’t feel right and comes with the drawbacks you mentioned.
Some more questions:
- How would you realize a separate process for filtering?
- How would you implement an aggregation to get the next 200 transactions in your approach (i.e., get 200, the next 200, the next next 200, …)?
Going back to the duplicate documents, how often does this occur?
~0,23% of documents are duplicates in our sample (50k docs)
have you considered using a regular collection with a unique index that can deal with the duplicate values as it is being inserted?
Yes, but time series feel natural for this problem, since it takes the burden of creating buckets, efficiently storing the data, enabling nice queries, … off our shoulders.
With regards to the above and starting in MongoDB version 5.0.5, you can perform some delete and update operations
Unfortunately, queries can be only performed on the meta fields, which doesn’t help in our scenario.
Thanks,
Ben