Hi all,
we use a time series collection and need to regularly collect and display the first 50, 100, 250 documents of a device. Individual entries must be unique and updatable, so duplicates must always be filtered out (using a group). I’m new to mongo and stuck at calculating the document count.
I have two ideas:
-
Aggregate the documents via the system.bucket and use its control.count field to determine the current document count. Then break as soon as the desired limit is reached. Yet, I don’t know how to do this dynamically and more important directly in the aggregation. In fact, I currently just guess the $limit.
-
Use the time series collection (not the internal bucket collection) and limit documents using a time window. Yet, I don’t know how to dynamically increase the window in the aggregation.
Here are two examples.
Example aggregation using the time series collection:
const cursor = await db.collection(test).aggregate([
{
$match: {
"meta.ti": ti,
"meta.type": "P",
ts: {
$lte: new Date("2022-05-27T16:40:29.000Z"),
$gte: new Date("2022-05-09T06:10:22.000Z"),
},
},
},
{
$group: {
_id: {
ti: "$meta.ti",
trace: "$trace",
ts: {
$dateTrunc: {
date: "$ts",
unit: "day",
startOfWeek: "monday",
binSize: 1,
},
},
},
docs: {
$topN: {
output: "$$ROOT",
sortBy: {
_id: 1,
},
n: 1,
},
},
},
},
{
$sort: {
"docs.ts": -1,
},
},
]);
Example aggregation using the system.bucket collection:
const cursor = await db.collection(system.buckets.test).aggregate([
{
$match: {
"meta.ti": ti,
"meta.type": "P",
},
},
{ $limit: 2 },
{
$_internalUnpackBucket: {
timeField: "ts",
metaField: "meta",
bucketMaxSpanSeconds: 3600,
},
},
{
$group: {
_id: {
ti: "$meta.ti",
trace: "$trace",
ts: {
$dateTrunc: {
date: "$ts",
unit: "day",
startOfWeek: "monday",
binSize: 1,
},
},
},
docs: {
$topN: {
output: "$$ROOT",
sortBy: {
_id: 1,
},
n: 1,
},
},
},
},
{
$sort: { "docs.ts": -1 },
},
]);
Devices provide data points with different insertion rates (i.e. some devices insert within seconds and others in days to weeks). So for some devices I will scan too little for others too much documents if I just guess the time span or the limit.
Is it possible in both scenarios to avoid this under and over fetching? Is there a smarter way to approach this problem?
Thanks,
Ben

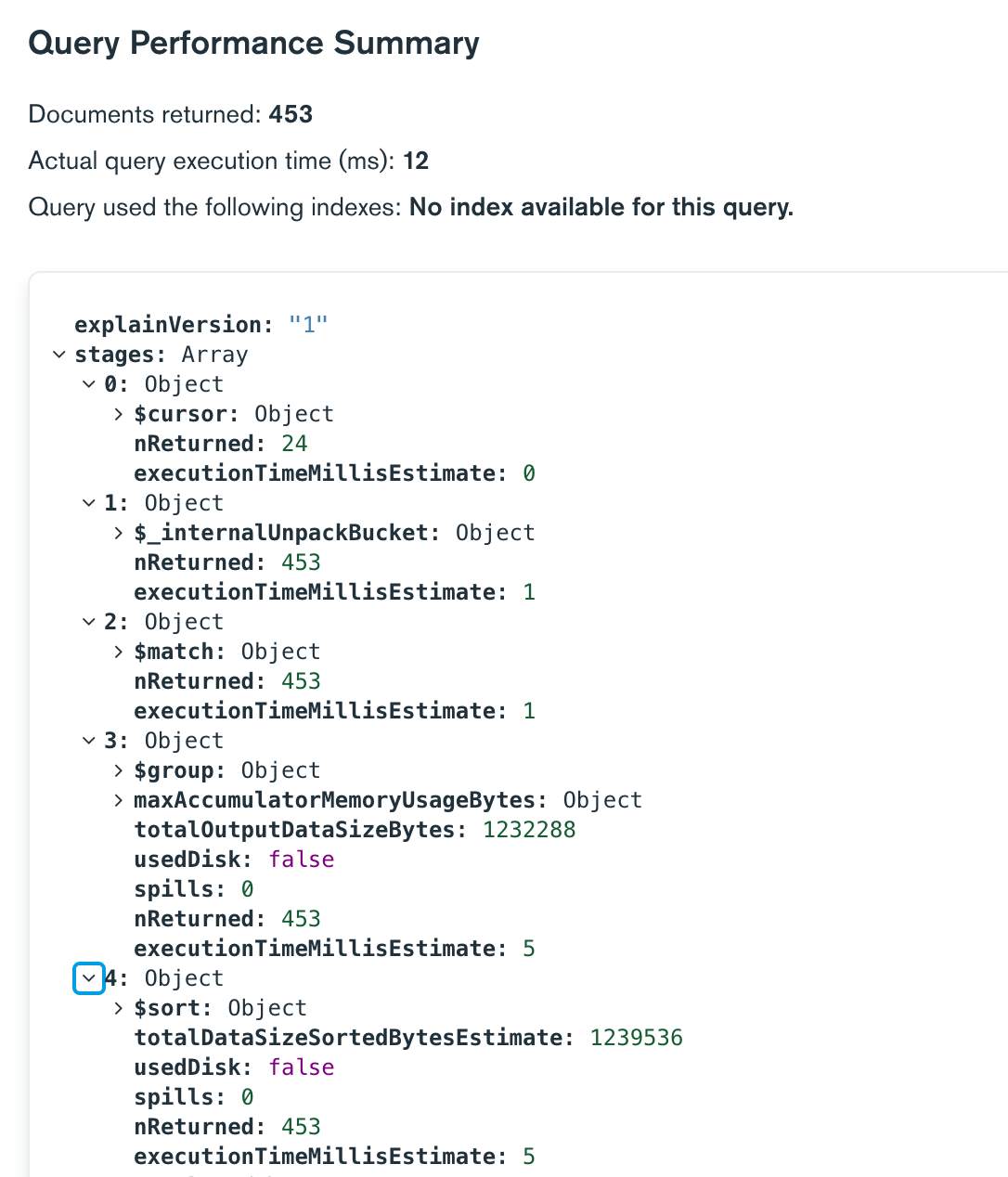
 Just need to $match, $sort and $limit before doing anything else. This way mongo limits the number of buckets to be unpacked and does not unpack all buckets anymore. For instance:
Just need to $match, $sort and $limit before doing anything else. This way mongo limits the number of buckets to be unpacked and does not unpack all buckets anymore. For instance: