Hi all,
I thought I’d share my experiences of upgrading from M2 to M5 recently and hopefully pass some lesson’s learned on to others.
So I had a production database running on an M2. I know MongoDB don’t recommend running a production system from shared infrastructure and perhaps this highlights one of the reasons it’s a bad idea. It was about 1.8GB in size with a couple of collections having more than 3M records. I chose a Saturday morning to start as it would mean I was free from distractions.
Step 1 was to take a copy of the most recent back-up and download it for safe keeping if anything went wrong.
Step 2 was to disable all of the running scheduled jobs and incoming HTTPS endpoints so that they wouldn’t be putting data into the database during the upgrade.
Step 3 I also tried to unlink the database from the App so that no data could be written to the database. However, clicking unlink in the UI didn’t do anything (possible bug?) and trying to disable the link via a deployment also didn’t work. Given I’d already done steps 1 and 2, I wasn’t too worried about it.
Step 4 was to click the upgrade button. A message next to the button said it would take between 7 - 10 minutes.
After about an hour into the upgrade I started to get worried that it was going badly. During the upgrade process you lose access to all of the metrics so I couldn’t check to see how far through it was. I started to think about rolling back and restoring my back-up. I then created a fresh M5 instance to see if I could restore my back-up to it. However, it turns out the format of the back-up is not suitable for restoring back into MongoDB directly. I read online that I could install a local instance of Mongo and use that to convert the format but that seemed like a big job and not an area I was familiar with.
After another hour, I started to wonder whether not unlinking the application was causing data to be written to the database and restarting the migration process. I hurriedly wrote a site under maintenance page for my website, which, I should have done from the beginning but I thought the site was only going to be down for 10 minutes so hadn’t bothered.
I thought about contacting support but being a Saturday they weren’t available on my plan. Perhaps choosing a Saturday wasn’t a good idea.
I then had the idea to switch my application linked database to the empty M5 database I created earlier to divert any remaining traffic away from the migrating database. I then just left it for a few more hours to see if the migration would complete. Finally the migration completed about 7 hours later with a message saying that it had failed.
Once the database was back up, I could check the stats and saw that it had restarted a couple of times but the third time (after I had diverted the app to the empty database) succeeded. Although the migration still took several hours (much longer than the advertised 10 minutes).
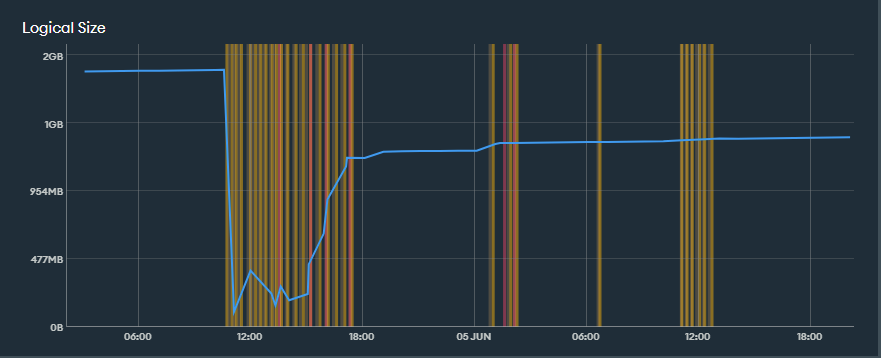
Whilst it said it had failed, it was up and running on an M5 and all of the collections appeared to be in place with data in them so as far as I was concerned it appeared successful. I linked the app back to the migrated database, took down the maintenance page and re-enabled the endpoints and schedules.
I was a bit worried that the database had shrunk in size from 1.8GB to about 1GB but I put this down more efficient use of storage rather than data loss as all my data appeared to be in place.
A few days later I got an email from a user saying they had lost some data and I started to dig into exactly what was missing. What I discovered was that all of the indexes on the collections had gone missing (not something I thought to check after the migration). The reason this hadn’t caused a massive performance issue is because Mongo had created some indexes automatically for me (nice feature!) however, it didn’t know that they needed to be unique. So I quickly tried to recreate the unique indexes but they failed due to the presence of duplicate records. I spend a few hours hunting down the duplicates one by one and deleting them but I wasn’t sure how many I had. Finally I wrote an aggregation to count them all and discovered that I had tens of thousands of duplicate records (not easy to spot in millions of records). I presume these came about from the migration restarting as many that I spot checked were of quite old data.
I then wrote a function to find the duplicates via an aggregation then loop through and delete them using a bulk update in batches of 1000. Finally then was I able to reapply my indexes. Luckily I had written a script to create all of my indexes and views from scratch so this step was easy.
The reason the user thought they had lost data was because an aggregation was failing due to the missing indexes and making it look like there was missing data in the application.
I guess what I should have done and will do next time is create a fresh M5 instance then restore the M2 back-up into the M5 then delete the M2 and re-point the app to the new M5 instance. Hopefully this will be useful to anyone who is considering upgrading from M2 to M5.
I’m also not entirely convinced that disabling the https endpoints really worked as I saw log entries showing them working even after I disabled them
Requests from MongoDB:
- change the advice on upgrade to say that it could take several hours.
- add additional advice about disconnecting your application and what steps to take to do this.
- ensure unlinking your application works properly.
- provide some indication as to how long the migration may take - e.g. keep the access to the stats during the migration process.
- provide the ability to import a back-up that has been downloaded and saved locally.
Sorry for the long post. Hope someone finds it useful.

