Hi,
We are planning to implement MONGO DB. Approx. 100 writes per month.
How can we estimate RAM and DB Size initially. Please provide me with some docs as to what
are the parameters that’s needs to be considered for planning this.
Hi,
We are planning to implement MONGO DB. Approx. 100 writes per month.
How can we estimate RAM and DB Size initially. Please provide me with some docs as to what
are the parameters that’s needs to be considered for planning this.
Hi @Ramya_Navaneeth,
100 millions writes per month isn’t a lot if the workload is evenly distributed across the months.
100000000/(60×60×24×31) = 37.34 writes/sec on average.
The first question are:
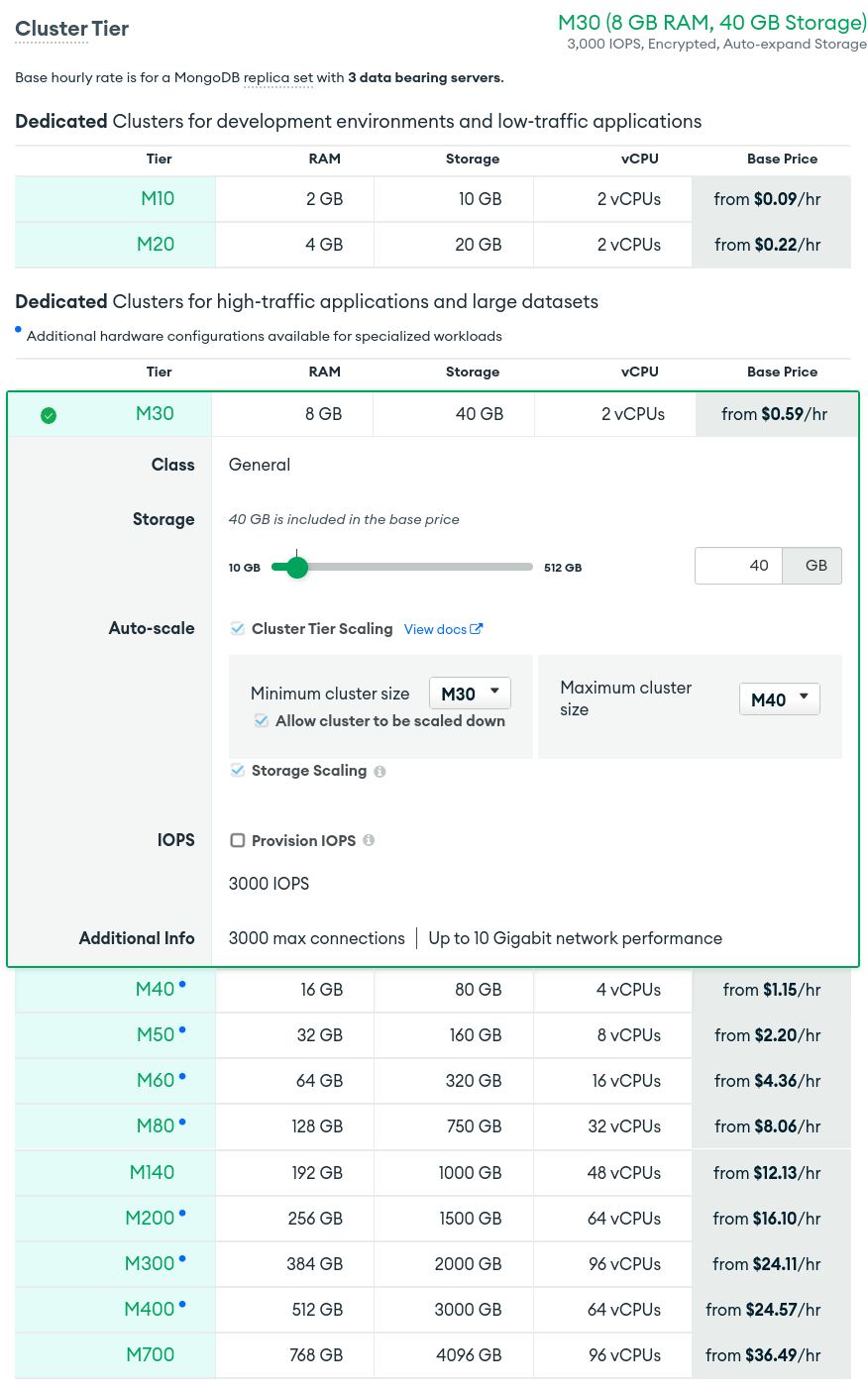
MongoDB Atlas Tiers are usually a good place to start. It gives you a good idea of the ideal ratio of CPU/Disk/RAM that you need.
Usually 15 to 20% of your data storage as RAM is a good starting point for a healthy cluster.
Cheers,
Maxime.
Thanks Maxime. Here the data size is approx 80G, then the estimate RAM 30G, 8 cores, 2000 iops is sufficient?
Hi Maxime,
Estimate RAM, vCPUs, Storage, IOPS and how many nodes we can configure initially?
A 3 nodes Replica Set is usually enough from 0 to 2 TB of data. Unless their is another constraint (data sovereignty, low latency targets, …), usually you only need to switch to a Sharded Cluster when you reach 2 TB.
If you have about 100 GB of data today, then the equivalent of an M50 should do the job just fine. I’m more worried about the growth rate per month of 20 to 30%. Your hardware will have to follow this growth as you go so your cluster isn’t missing RAM in 2 months; unless you implement an archiving policy that retires data to a cheaper storage solution (S3) as fast as you are adding some more in the cluster.
That’s what Atlas Online Archive automates, so you don’t have to upgrade to a higher tier every month or so. With this solution, you only keep the hot data in the cluster.
Depending on your constraints and High Availability, you could also choose to run 5 nodes instead of 3. But the minimum is 3. 5 gives you more HA during maintenance operations for instance. It also depends how you implement the backups, etc.
Atlas automates and solves all these problems for you. I can’t recommend it enough ![]() .
.
Cheers,
Maxime.
Hi Maxime,
Thanks for the detailed information. Here 20 to 30% is year growth.
Ha that’s more manageable  !
!
But still, if you keep all the data in the same cluster, every couple of years you should consider an upgrade so the performances don’t deteriorate over time as the data grows.
Thanks a lot Maxime for the detailed response.
Hi Maxime,
May I know is it possible to store 60TB data in a single Replicate set? If yes, how about the performance issue? And how about the OS requirement?
Yours,
Manhing
Hi @Man_Hing_Chan,
Sorry for the very long delay for my answer, I was on extended paternity leave.
It would be nice to have this discussion in a dedicated thread (feel free to tag me @MaBeuLux88_xxx in there).
But my short answer is absolutely not. The cost of this Replica Set (RS) would be astronomic compared to a Sharded Cluster with “standard” & less pricey hardware.
To manage 60TB in a RS, you would need at least
The cost of these machines (if it’s even possible to build them) would be a lot more expensive that a sharded cluster with 4TB SSDs and 256GB RAM each and they would be full of scalability issues.
Divide & conquer. There is no other way to sustain that much data without sharding.
Also, let’s say one day you have a big crash and you have to restore from a backup. How long is this going to take to copy 60TB 3 times and restart mongod? See RPO & RTO.
Cheers,
Maxime.