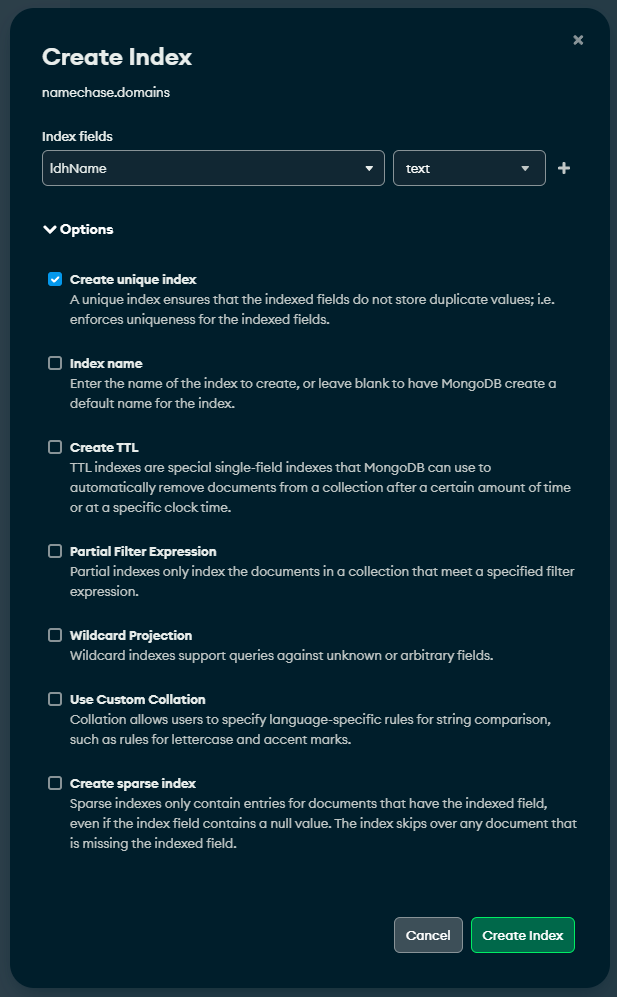
I am trying to insert some documents into a collection and I get a duplicate key error, I have checked the documents that I am inserting multiple times, and removing the key seems to enable the insert to happen.
Here is two examples of the document I am trying to insert, with the unique key index on ldhName unless I’m mistaking somthing, the key would be unique.
{
"ldhName": "exampleone.org.uk",
"unicodeName": "storyinstone.org.uk",
"tld": "org.uk",
"lastUpdated": "2024-08-23T01:33:12"
}
{
"ldhName": "exampletwo.co.uk",
"unicodeName": "eurovision2023.co.uk",
"tld": "co.uk",
"lastUpdated": "2024-08-23T01:38:47"
}
The error it’s throwing up is:
Exception('Unable to insert document', DuplicateKeyError('E11000 duplicate key error collection: namechase.domains index: ldhName_text dup key: { _fts: "uk", _ftsx: 0.6666666666666666 }, full error:
{\'index\': 0, \'code\': 11000, \'errmsg\': \'E11000 duplicate key error collection: namechase.domains index: ldhName_text dup key: { _fts: "uk", _ftsx: 0.6666666666666666 }\', \'keyPattern\': {\'_fts\': \'text\', \'_ftsx\': 1}, \'keyValue\': {\'_fts\': \'uk\', \'_ftsx\': 0.6666666666666666}}'))))
From what I can see, it creates the index on the last part of the , and not the entire string as I would expect, and removing the periods seems to solve the issue too, is this a missunderstanding of how the unique key works, or am I missing somthing?