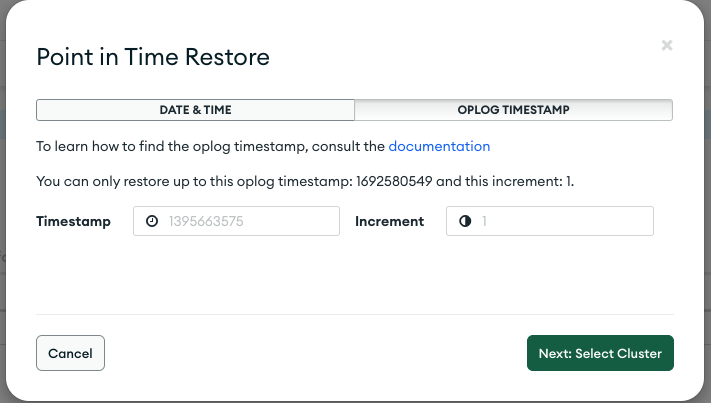
Hi there. My goal is to successfully use the continuous cloud backup feature, when doing automatic db migrations. (so a script can automatically recover the database, if migrations failed for some reason). The script runs this MongoDB Atlas CLI command, as described here:
atlas backup restore start pointInTime --clusterName ${clusterName} --pointInTimeUTCMillis ${pointInTimeMillis} --targetClusterName ${clusterName} --targetProjectId ${projectIdProduction} --output json
And sometimes if fails with:
Error: https://cloud.mongodb.com/api/atlas/v2/groups/<groupId>/clusters/<cluster-name>/backup/restoreJobs POST: HTTP 400 (Error code: "BACKUP_PIT_RESTORE_TIME_INVALID")
Detail: Chosen Point in time timestamp invalid: Given point in time is too far ahead of latest oplog..
Reason: Bad Request. Params: [Given point in time is too far ahead of latest oplog.]
What does “Given point in time is too far ahead of latest oplog” means - and how can I mitigate this?