Hi Team,
I’m trying to create a pipeline in Google Cloud Datafusion to extract data from MongoDB Atlas to load in BigQuery. I’m using the google provided Mongo DB driver (v 2.0.0) in order to achieve this but I haven’t had any luck connecting to Atlas.
I’m trying to connect via standard connection and I’ve enabled the BI connection for our cluster and I’ve whitelisted the necessary IP’s in the network settings with no luck.
The MongoDB pipeline settings looks like this in Datafusion (I’m trying to connect using the host, port and user defined in the BI connection) :
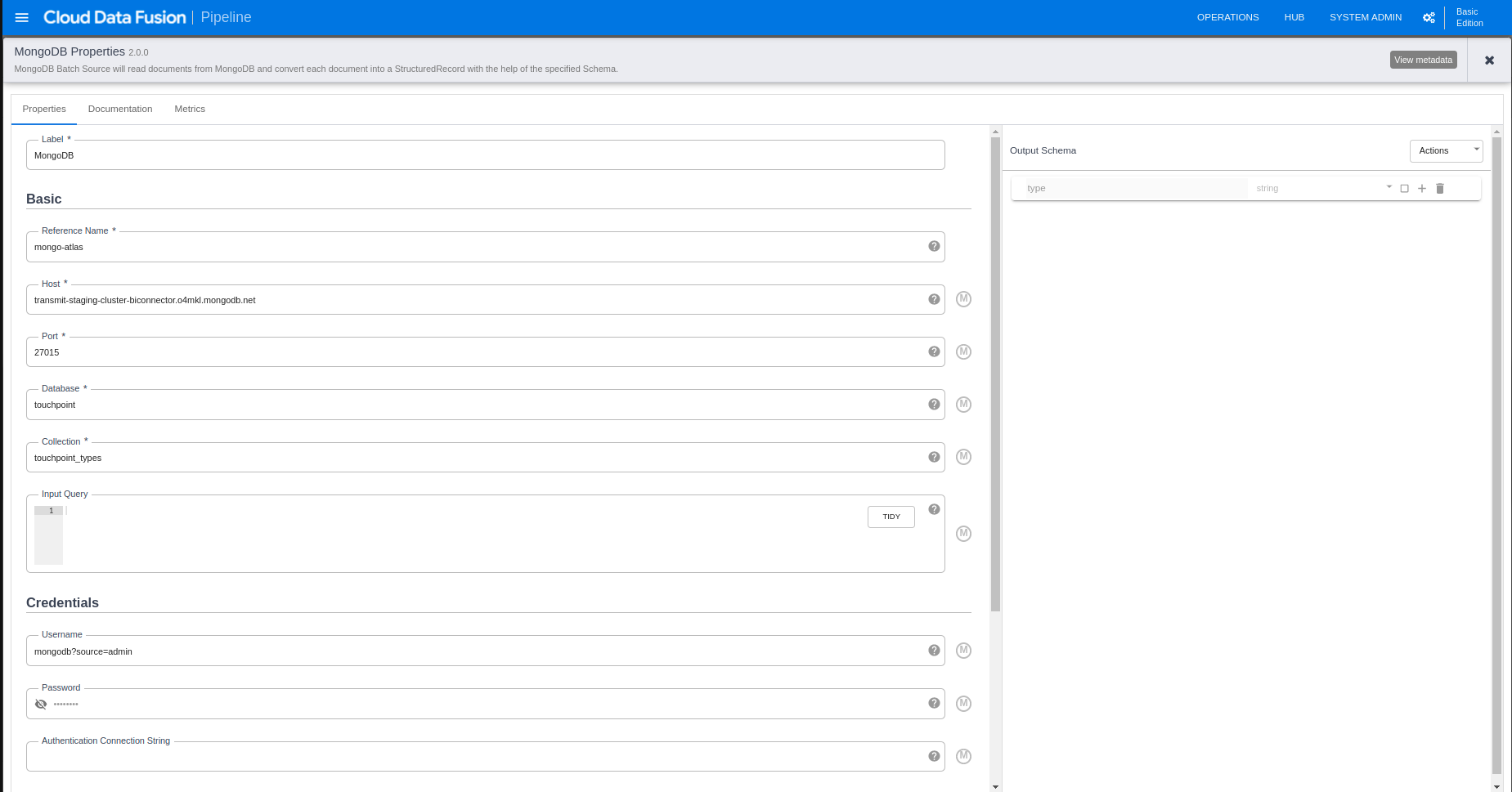
However this is not working and I’m getting the following errors in Datafusion logs:
ERROR
Application diagnostics message: User class threw exception: org.apache.spark.SparkException: Job aborted. at org.apache.spark.internal.io.SparkHadoopWriter$.write(SparkHadoopWriter.scala:105) at org.apache.spark.rdd.PairRDDFunctions.$anonfun$saveAsNewAPIHadoopDataset$1(PairRDDFunctions.scala:1077) at scala.runtime.java8.JFunction0$mcV$sp.apply(JFunction0$mcV$sp.java:23) at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:151) at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:112) at org.apache.spark.rdd.RDD.withScope(RDD.scala:414) at org.apache.spark.rdd.PairRDDFunctions.saveAsNewAPIHadoopDataset(PairRDDFunctions.scala:1075) at org.apache.spark.api.java.JavaPairRDD.saveAsNewAPIHadoopDataset(JavaPairRDD.scala:833) at io.cdap.cdap.etl.spark.batch.RDDUtils.saveHadoopDataset(RDDUtils.java:58) at io.cdap.cdap.etl.spark.batch.RDDUtils.saveUsingOutputFormat(RDDUtils.java:47) at io.cdap.cdap.etl.spark.batch.SparkBatchSinkFactory.writeFromRDD(SparkBatchSinkFactory.java:175) at io.cdap.cdap.etl.spark.batch.BaseRDDCollection$1.run(BaseRDDCollection.java:239) at io.cdap.cdap.etl.spark.SparkPipelineRunner.runPipeline(SparkPipelineRunner.java:383) at io.cdap.cdap.etl.spark.batch.BatchSparkPipelineDriver.run(BatchSparkPipelineDriver.java:227) at io.cdap.cdap.app.runtime.spark.SparkTransactional$2.run(SparkTransactional.java:236) at io.cdap.cdap.app.runtime.spark.SparkTransactional.execute(SparkTransactional.java:208) at io.cdap.cdap.app.runtime.spark.SparkTransactional.execute(SparkTransactional.java:138) at io.cdap.cdap.app.runtime.spark.AbstractSparkExecutionContext.execute(AbstractSparkExecutionContext.scala:229) at io.cdap.cdap.app.runtime.spark.SerializableSparkExecutionContext.execute(SerializableSparkExecutionContext.scala:63) at io.cdap.cdap.app.runtime.spark.DefaultJavaSparkExecutionContext.execute(DefaultJavaSparkExecutionContext.scala:91) at io.cdap.cdap.api.Transactionals.execute(Transactionals.java:63) at io.cdap.cdap.etl.spark.batch.BatchSparkPipelineDriver.run(BatchSparkPipelineDriver.java:158) at io.cdap.cdap.app.runtime.spark.SparkMainWrapper$.main(SparkMainWrapper.scala:87) at io.cdap.cdap.app.runtime.spark.SparkMainWrapper.main(SparkMainWrapper.scala) at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method) at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62) at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) at java.lang.reflect.Method.invoke(Method.java:498) at org.apache.spark.deploy.yarn.ApplicationMaster$$anon$2.run(ApplicationMaster.scala:732) Caused by: com.mongodb.MongoTimeoutException: Timed out after 30000 ms while waiting to connect. Client view of cluster state is {type=UNKNOWN, servers=[{address=transmit-staging-cluster-biconnector.o4mkl.mongodb.net:27015, type=UNKNOWN, state=CONNECTING, exception={com.mongodb.MongoSocketWriteException: Exception sending message}, caused by {javax.net.ssl.SSLException: Unsupported or unrecognized SSL message}}] at com.mongodb.internal.connection.BaseCluster.getDescription(BaseCluster.java:182) at com.mongodb.internal.connection.SingleServerCluster.getDescription(SingleServerCluster.java:41) at com.mongodb.client.internal.MongoClientDelegate.getConnectedClusterDescription(MongoClientDelegate.java:136) at com.mongodb.client.internal.MongoClientDelegate.createClientSession(MongoClientDelegate.java:94) at com.mongodb.client.internal.MongoClientDelegate$DelegateOperationExecutor.getClientSession(MongoClientDelegate.java:249) at com.mongodb.client.internal.MongoClientDelegate$DelegateOperationExecutor.execute(MongoClientDelegate.java:172) at com.mongodb.client.internal.MongoClientDelegate$DelegateOperationExecutor.execute(MongoClientDelegate.java:161) at com.mongodb.DB.executeCommand(DB.java:774) at com.mongodb.DBCollection.getStats(DBCollection.java:2282) at com.mongodb.hadoop.splitter.MongoSplitterFactory.getSplitterByStats(MongoSplitterFactory.java:76) at com.mongodb.hadoop.splitter.MongoSplitterFactory.getSplitter(MongoSplitterFactory.java:127) at com.mongodb.hadoop.MongoInputFormat.getSplits(MongoInputFormat.java:56) at io.cdap.cdap.etl.batch.DelegatingInputFormat.getSplits(DelegatingInputFormat.java:45) at org.apache.spark.rdd.NewHadoopRDD.getPartitions(NewHadoopRDD.scala:131) at org.apache.spark.rdd.RDD.$anonfun$partitions$2(RDD.scala:300) at scala.Option.getOrElse(Option.scala:189) at org.apache.spark.rdd.RDD.partitions(RDD.scala:296) at io.cdap.cdap.app.runtime.spark.data.DatasetRDD.getPartitions(DatasetRDD.scala:61) at org.apache.spark.rdd.RDD.$anonfun$partitions$2(RDD.scala:300) at scala.Option.getOrElse(Option.scala:189) at org.apache.spark.rdd.RDD.partitions(RDD.scala:296) at org.apache.spark.rdd.MapPartitionsRDD.getPartitions(MapPartitionsRDD.scala:49) at org.apache.spark.rdd.RDD.$anonfun$partitions$2(RDD.scala:300) at scala.Option.getOrElse(Option.scala:189) at org.apache.spark.rdd.RDD.partitions(RDD.scala:296) at org.apache.spark.rdd.MapPartitionsRDD.getPartitions(MapPartitionsRDD.scala:49) at org.apache.spark.rdd.RDD.$anonfun$partitions$2(RDD.scala:300) at scala.Option.getOrElse(Option.scala:189) at org.apache.spark.rdd.RDD.partitions(RDD.scala:296) at org.apache.spark.rdd.MapPartitionsRDD.getPartitions(MapPartitionsRDD.scala:49) at org.apache.spark.rdd.RDD.$anonfun$partitions$2(RDD.scala:300) at scala.Option.getOrElse(Option.scala:189) at org.apache.spark.rdd.RDD.partitions(RDD.scala:296) at org.apache.spark.SparkContext.runJob(SparkContext.scala:2257) at org.apache.spark.internal.io.SparkHadoopWriter$.write(SparkHadoopWriter.scala:83) ... 28 more
The connection seems to be timing out. I’ve tested connecting using MySQL Workbench (using the B.I connection and I could connect fine.
Does anyone here have experience with Datafusion and MongoDB Atlas and can help?
Thank you