Suppose I have one collection called test which has a below doc. Just for simplicity, it has one doc.
{
"_id": "63d771990ba1354fef3577c2",
"project": "63a2f3537844f79dd4fe7234",
"email": "user1@example.com"
}
Below is the doc schema
{
"_id": ObjectId,
"project": ObjectId,
"email": String
}
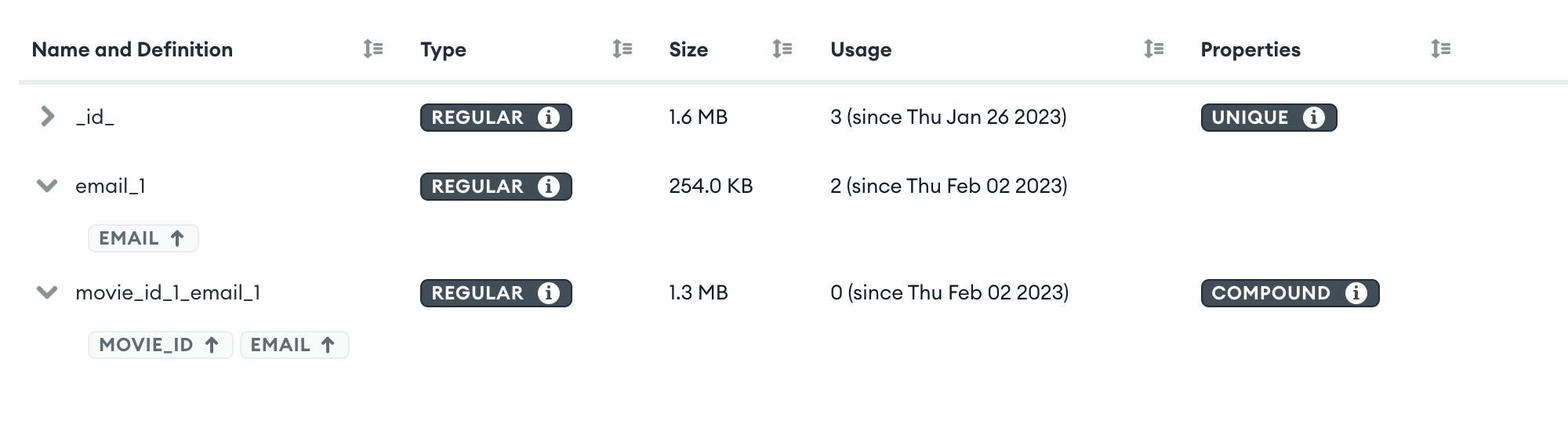
Below are the indexes that I have created in test collection.
- _id (default)
{ "email": 1 }-
{ "project": 1, "email": 1 }(this one is compound index)
Now if I run the below query it uses 3rd index (compound index) and that is correct because we have project field in the query and that belongs to the 3rd index.
{
project: ObjectId('63a2f3537844f79dd4fe7234')
}
Now if I run the below query why it uses the 2nd index ({ "email": 1 }) why not the 3rd compound index? why it is not using the 3rd compound index even though the query contains the compound index prefix project and also the email field?
{
project: ObjectId('63a2f3537844f79dd4fe7234'),
email: 'user1@example.com'
}
Now if I remove the 2nd index { "email": 1 } then we have only two indexes in test collection as below.
- _id (default)
-
{ "project": 1, "email": 1 }(a compound index)
Now if I create the same index { "email": 1 } again then we have the below indexes.
- _id (default)
-
{ "project": 1, "email": 1 }(a compound index) { "email": 1 }
Now if I run the same below query again then it will use the 2nd compound index { "project": 1, "email": 1 }.
{
project: ObjectId('63a2f3537844f79dd4fe7234'),
email: 'user1@example.com'
}
Why for the same above query if we have indexes as below
- _id (default)
{ "email": 1 }-
{ "project": 1, "email": 1 }(a compound index)
then it will use { "email": 1 } index to find documents
and if we have the below indexes
- _id (default)
-
{ "project": 1, "email": 1 }(a compound index) { "email": 1 }
then it will use { "project": 1, "email": 1 } index to find documents?