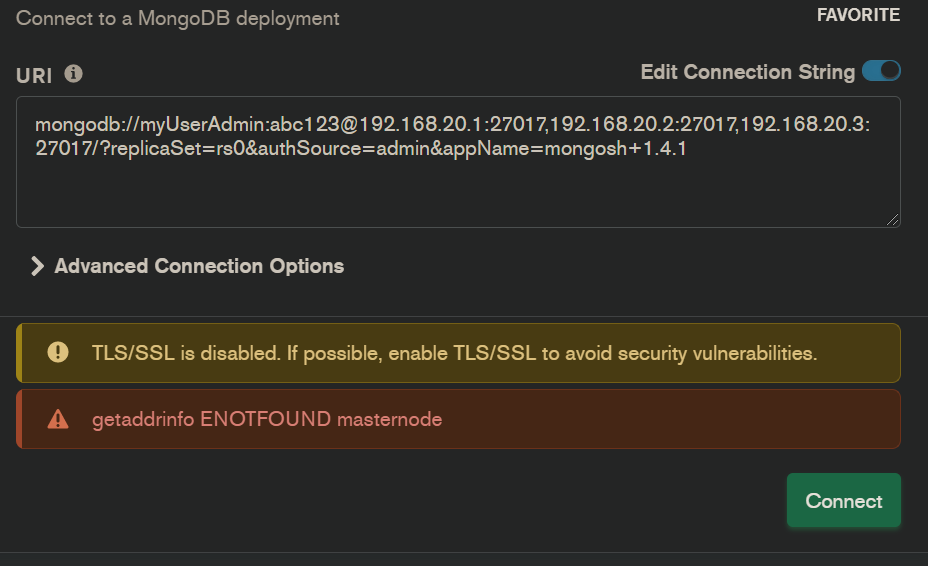
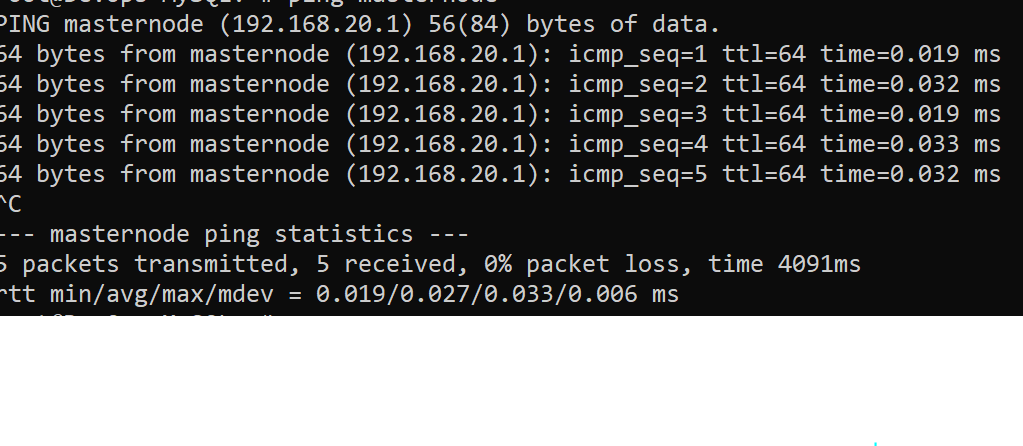
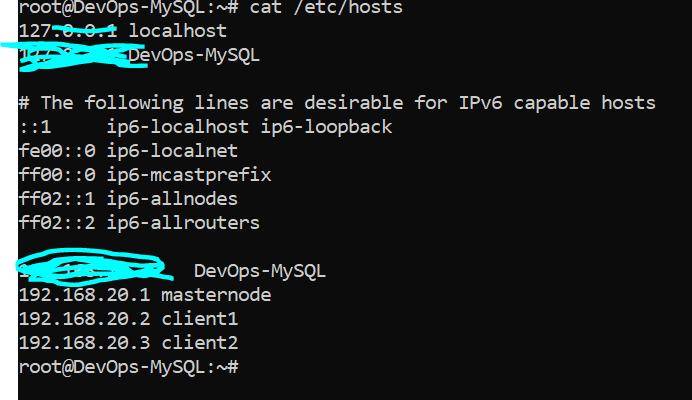
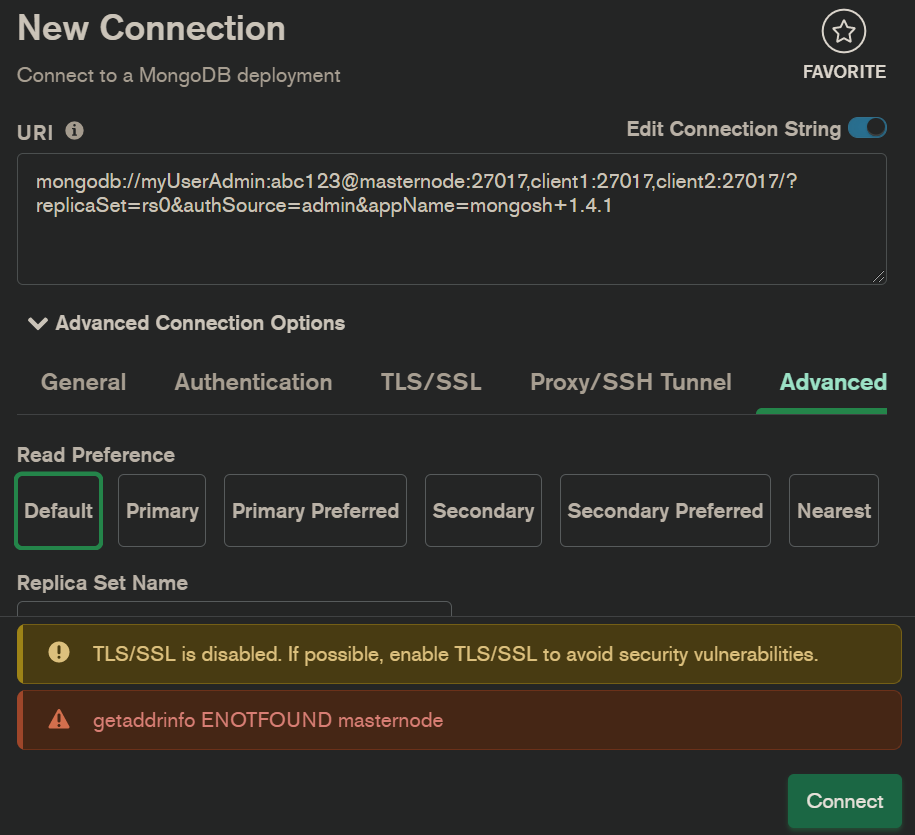
I have a mongodb cluster on 3 different VMs. When I try to access to the replicaset via compass using this GUI :
mongodb://at192.168.20.1:27017,192.168.20.2:27017,192.168.20.3:27017/?replicaSet=rs0&authSource=admin&appName=mongosh+1.4.1
It says getaddrinfo ENOTFOUND masternode or sometimes it says getaddrinfo ENOTFOUND client1
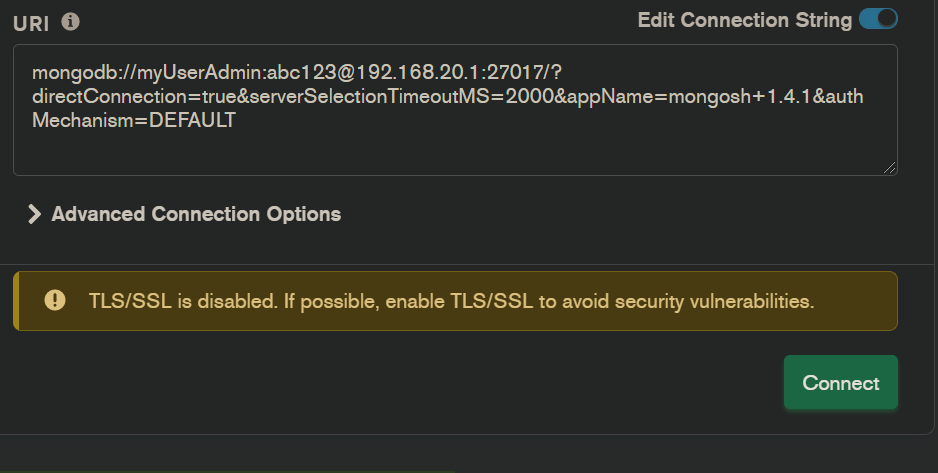
However, if I try to connect separately to each one using :
mongodb://at192.168.20.1:27017/?directConnection=true&serverSelectionTimeoutMS=2000&appName=mongosh+1.4.1&authMechanism=DEFAULT
<mongodb://at192.168.20.2:27017/?directConnection=true&serverSelectionTimeoutMS=2000&appName=mongosh+1.4.1&authMechanism=DEFAULT/>
mongodb://at192.168.20.3:27017/?directConnection=true&serverSelectionTimeoutMS=2000&appName=mongosh+1.4.1&authMechanism=DEFAULT
It works just fine.
Is there anything wrong with my replicaset GUI and how can I fix this?
FYI, 192.168.20.1, 192.168.20.2 and 192.168.20.3 is associated with masternode, client1 and client2 respectively as well as I use at instead of @ due to new user tag thingy
Your reply is very appreciated.