Hi Steeve, How I can achieve it using Atlas search, need to get matching of “dodge ram” 1st
Hi @Shopi_Ads,
I’ve moved this to a new post as it is a different topic to the original post in which you replied to.
In saying so, does using phrase work for you?
If you require further assistance, please provide the following details:
- Atlas search index definition
- Search query attampted
- Sample document(s)
- Expected output
Please also provide these in text format so we can copy and paste to test in our test environment if required as opposed to screenshots.
Regards,
Jason
Hi @Jason_Tran ,
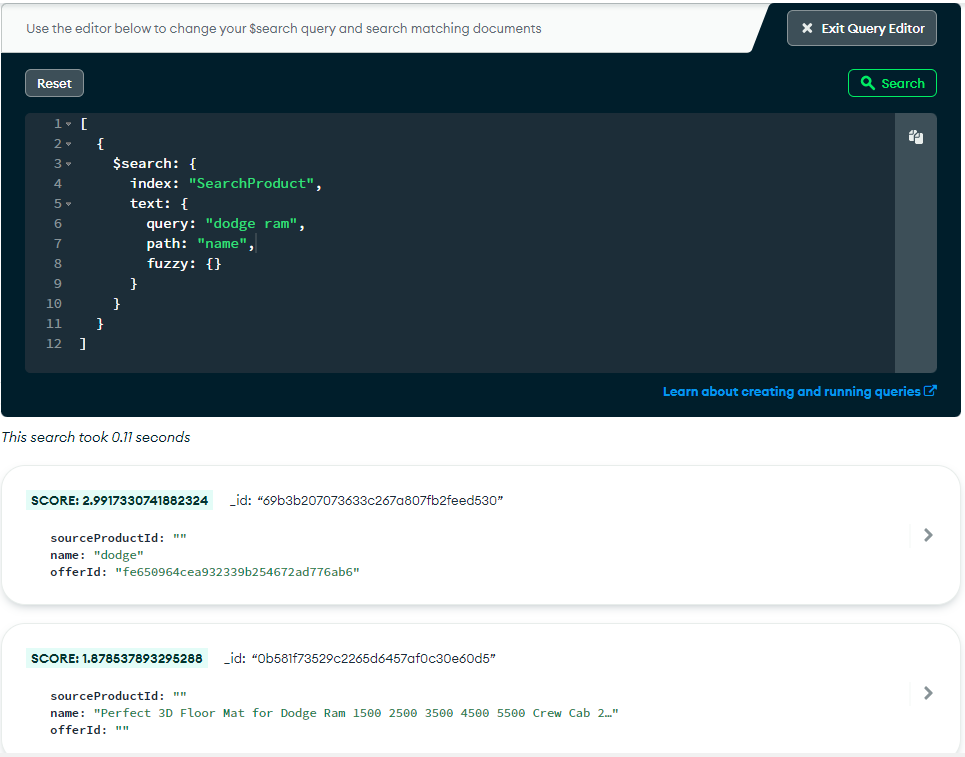
Phrase does not work as it does not operate under OR condition. We want to match if any of the word is matched in query
- Atlas search index definition
Index created on Name - Search query attampted
[
{
$search: {
index: "SearchProduct",
text: {
query: "dodge ram floor mats",
path: "name",
fuzzy: {}
}
}
}
]
- Sample document(s)
Documents with name : dodge, dodge ram, ram dodge 2016, dodge ram 2500, floor mats for dodge ram - Expected output
a) the result should get in descending order for maximum matched words 1st and so on
Example : If search is “dodge ram floor mats” then should get “floor mats for dodge ram” 1st
b) Applying fuzzy so if someone uses mat instead of mats then too it should be considered.
Let me know if you need more info
Thanks
I’ve provided further details below which may help but if not and in future, can you provide the JSON format of the index definition? The behaviour may differ if I use the default index definition in my own environment compared to your environment so testing would not be as effective.
In future could, you provide documents in JSON format so we can easily copy and paste them into our test environment if we need to test? This makes it easier for the people assisting so that it would be easier for them to help you.
In saying so, i’ve used the default index definition for my test environment. Please see sample documents below:
dodge> db.collection.find({},{_id:0})
[
{ name: 'dodge' },
{ name: 'dodge ram' },
{ name: 'ram dodge 2016' },
{ name: 'dodge ram 2500' },
{ name: 'floor mats for dodge ram' }
]
I then utilised the compound operator with the should clause (my index is called nameindex for this test):
db.collection.aggregate([
{
$search: {
index: 'nameindex',
compound: {
should: [{
text: {
query : 'dodge ram floor mats',
path: 'name'
}
}]
}
}
},
{
$project: {
_id: 0,
'name': 1,
'score': {$meta: 'searchScore'}
}
}
])
I’ve projected the score for your reference as well. The output is below:
[
{ name: 'floor mats for dodge ram', score: 1.082603096961975 },
{ name: 'dodge ram', score: 0.19285692274570465 },
{ name: 'ram dodge 2016', score: 0.16547974944114685 },
{ name: 'dodge ram 2500', score: 0.16547974944114685 },
{ name: 'dodge', score: 0.05366339907050133 }
]
You might also be able to use queryString to achieve what you’re after.
With any of these examples, please test thoroughly in a test environment to ensure it suits all your use case(s) and requirement(s).
Regards,
Jason
Index definition
{
"analyzer": "lucene.english",
"searchAnalyzer": "lucene.english",
"mappings": {
"dynamic": false,
"fields": {
"name": {
"type": "string"
}
}
},
"storedSource": {
"include": [
"name"
]
}
}
Results:
I am getting right output for “dodge ram floor mats” but not for “dodge ram” and “dodge ram 2500”.
We are looking to get the high score for maximum number of matching words first.
In “dodge ram 2500” the output of “dodge” should be last as there are other data with more then 1 matches
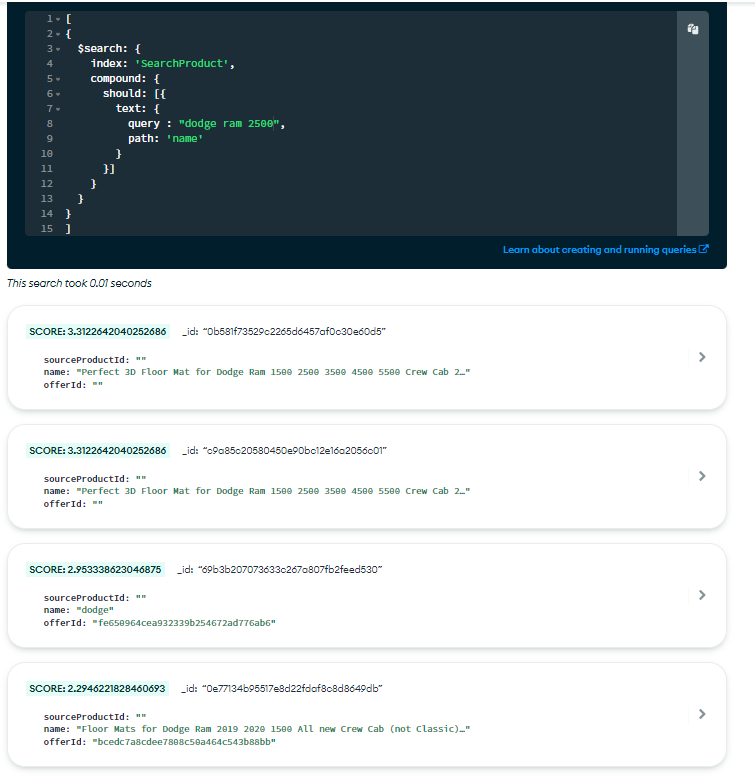
It works as expected when we have records only which belongs to “dodge…” which are 5 records. But its not working on full set of data which contain non-dodge data as well
Please find the full collection attached
search_prod.json (1.4 MB)
You can try using search score details to explain the results you’re seeing but I believe one factor that may be dl (length of the field in the document) - I did some brief testing off a smaller data set from the JSON file you provided which appeared to also show that dl was a factor that caused the scoring to be how it was amongst the last two documents shown in your screenshot. In short, it does appear like the behaviour you’ve mentioned is expected based off your index definition, search query and test documents.
As per the Score documentation:
Every document returned by an Atlas Search query is assigned a score based on relevance, and the documents included in a result set are returned in order from highest score to lowest.
Many factors can influence a document’s score, including:
In this particular case here,the document only containing dodge was scored higher due to the significantly longer length of the other document(s) containing more terms. Please also consider that those documents contained more words that did not match the search criteria.
You can try again with the following index definition:
{
"analyzer": "lucene.english",
"searchAnalyzer": "lucene.english",
"mappings": {
"dynamic": false,
"fields": {
"name": {
"indexOptions": "docs",
"norms": "omit",
"type": "string"
}
}
},
"storedSource": {
"include": [
"name"
]
}
}
The main changes performed above were setting:
normsvalue to"omit"indexOptionsvalue to"docs"
The following is the output I get (you can see the document only containing "dodge" is at the end):
dodge>db.collection.aggregate([
{
$search: {
index: 'nameindex',
text: {
query: 'dodge ram 2500',
path: 'name'
}
}
},
{$project:{_id:0,name:1,score:{$meta:'searchScore'}}}
])
[
{ name: 'dodge ram 2500', score: 3.8390729427337646 },
{
name: 'Floor Mats for Dodge Ram 2019 2020 1500 All new Crew Cab (not Classic) weather guard Front & Rear Row TPE Slush Liner Mats',
score: 1.9325730800628662
},
{ name: 'dodge ram', score: 1.9325730800628662 },
{ name: 'ram dodge 2016', score: 1.9325730800628662 },
{ name: 'floor mats for dodge ram', score: 1.9325730800628662 },
{ name: 'Floor Mats for Dodge Ram 2019', score: 1.9325730800628662 },
{
name: 'Floor Mats for Dodge Ram 2019 2020 1500 All new Crew Cab (not classic)...',
score: 1.9325730800628662
},
{
name: 'Floor Mats for Dodge Ram 2019 2020 1500 All new Crew Cab (not classic) random text random stuff randomly random testing test',
score: 1.9325730800628662
},
{
name: 'Floor Mats for Dodge Ram 2019 2020 1500 All new Crew Cab (not classic)...',
score: 1.9325730800628662
},
{
name: 'Floor Mats for Dodge Ram 2019 2020 1500 All new Crew Cab (not classic)...',
score: 1.9325730800628662
},
{
name: 'Floor Mats for Dodge Ram 2019 2020 1500 All new Crew Cab (not classic)...',
score: 1.9325730800628662
},
{
name: 'Floor Mats for Dodge Ram 2019 2020 1500 All new Crew Cab (not classic)...',
score: 1.9325730800628662
},
{
name: 'Floor Mats for 2014-2018 Chevrolet Silverado/GMC Sierra 1500 Crew Cab, 2015-2019 Silverado/Sierra 2500/3500 HD Crew Cab All Weather Guard 1st and 2nd Row Mat TPE Slush Liners',
score: 1.906499981880188
},
{ name: '2500', score: 1.906499981880188 },
{ name: 'dodge', score: 0.9386987090110779 }
]
Regards,
Jason
2 Likes
Check the string type properties documentation for more information regarding the above index definition example I gave. As always, it’s recommended to alter your index / search accordingly and then test thoroughly to ensure it suits all your use case(s) and requirement(s).
A post was split to a new topic: Atlas search - autocomplete scoring