Hi Mongo community!
I have around 300k docs and I want to run a query aggregation with diff stages.
the query needs 2 to 5s to resolve, depend on the text query, let say if we do “iphone 10” the query will take 1s but if we do “iphone 11 glass screen protectors” will take 3 to 10s, is there any way to improve this pipeline :
[
{
"$search": {
"index": "product_title_en",
"text": {
"query": "iphone 11 glass screen protectors full",
"path": "product_title_en"
}
}
},
{
"$facet": {
"products": [
{
"$skip": 0
},
{
"$limit": 20
}
],
"products_count": [
{
"$count": "totalCount"
}
],
"available_categories": [
{
"$group": {
"_id": "$category_en"
}
}
]
}
},
{
"$project": {
"products_count": "$products_count.totalCount",
"products": "$products",
"available_categories": "$available_categories._id"
}
}
]
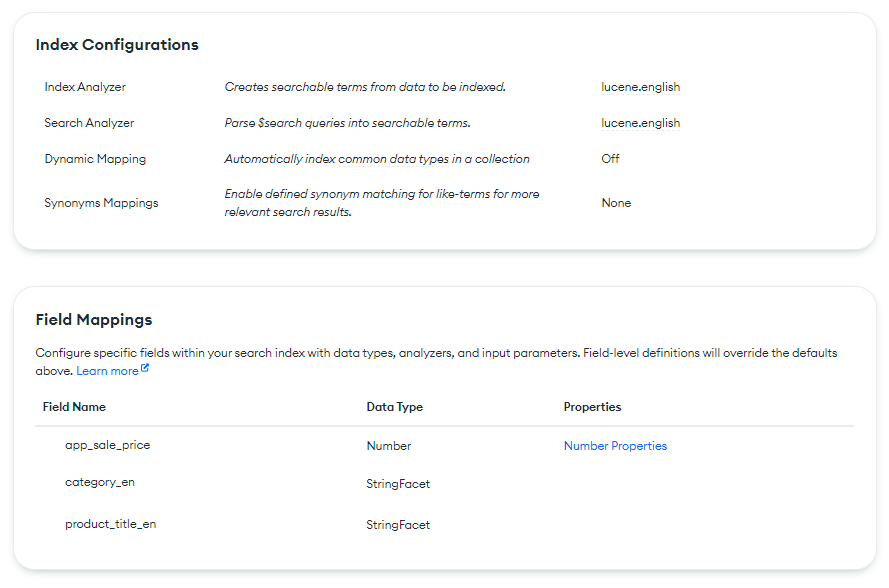
I did build atlas search index named “product_title_en”, can you help with with best practice in such scenario.
I do not understand why the seach take much longer evertime we add new word to the query