I want to ask a question, I use aggregation to fetch data from one document to reference document. this is my code, it is correct, just this code is not suitable for large data. here the comment “the way you followed might not be scalable, which might cause problems in the future, such as overkilled, eating up the storage CPU & RAM”, can you teach me another query?
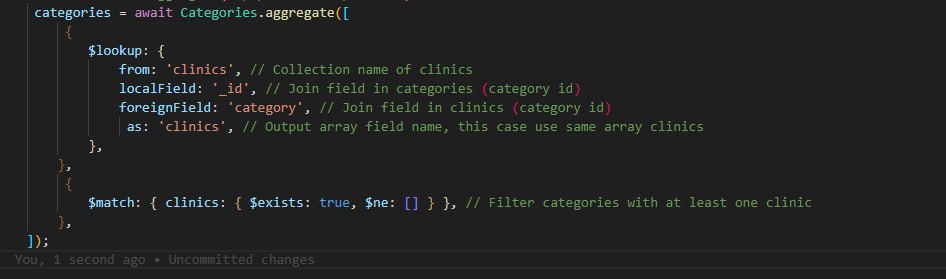
I would say you should do 2 things:
- Index
clinicsproperty. - Replace the order of the
$matchand$lookupin youraggregatequery.$matchcan leverage the index only if it’s the first stage of the aggregation pipeline.
By doing that, your query should be performant even on large datasets.
3 Likes
thank you so much @NeNaD i wll try it
1 Like
My 2 cents.
I do not think that the following is possible.
The $match query the field critics which is the result of the $lookup. So it cannot be done before.
You use case seems overly simplistic. It looks like you want to somehow process the clinics on an ordered way using the category. I would implement a use-case like that by aggregation on the clinics and $lookup on categories.
pipeline = [
{ "$sort" : {
"category" : 1
} } ,
{ "$lookup" : {
"from" : "categories" ,
"localField" : "category" ,
"foreignField" : "_id" ,
"as" : "category"
} }
] ;
db.clinics.aggregate( pipe ) ;
It is kind of a $group but without the risking the 16MB limit due to a massive array.
One caveat is that the category data is duplicated in the output. A $project could be used in the $lookup pipeline to reduce this.
Please read Formatting code and log snippets in posts before posting new code or documents. We cannot cut-n-paste code or documents from an image so it makes experimenting and replying slower than it could.
2 Likes
thanks a lot @steevej