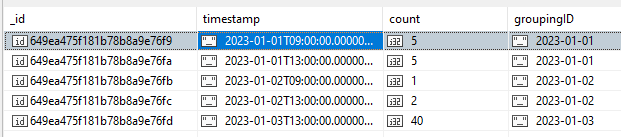
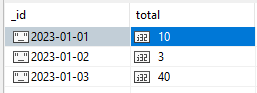
I have two collections A and B. The data in B is aggregated from A and I want to have a field on A which stores which record in B the data was aggregated to e.g. an audit trail
Update A with the _id of which document A has been aggregated in B
Is this possible in a single query? Or would I have to generate the aggregate to update B with, record the A _id’s then update by an array of those _id’s?
No probs @John_Sewell, thanks anwyay. For context there will be ~3k A documents being aggregated into a single B document. So I didn’t feel like an array of that size linking back from B to multiple As was the right way to go (amongst other considerations).
Studio3T. There is a free edition but quite a lot of the good stuff is pay walled. Things like import and export as well as schema analysis etc.
I use the import and export constantly through my day.
The screenshots were the output window which can run in table, tree or json view.
Its not cheap, but its paid for by the company so excellent value for me!