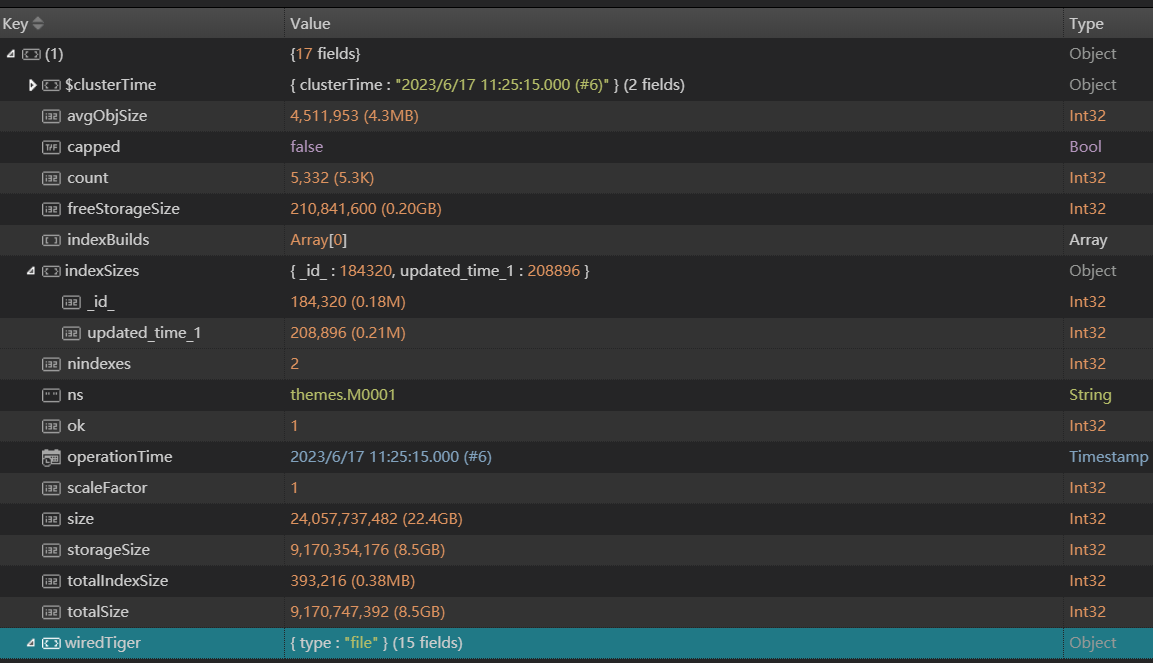
One of my collection is large, and the size about 8.4G , about 5600 items.
And I use the aggregate pipelines to make a api for pagination, but the query is so slow.
The query command is below:
db.M0001.aggregate([
{
"$match" : {
"updated_time": {"$gt": ISODate("2010-05-01T00:00:00.000Z")}
}
},
{
"$sort": {
"updated_time": -1
}
},
{
"$project": {
"GC0004440E_Y0Y2021010120211231": 1,
"_id": 0
}
},
{
"$facet": {
"data": [
{
"$skip": 300
},
{
"$limit": 1000
}
],
"pagination": [
{
"$count": "total"
}
]
}
}
], {explain: true})
And the explain is shown in the jpg, it takes about 62 seconds:
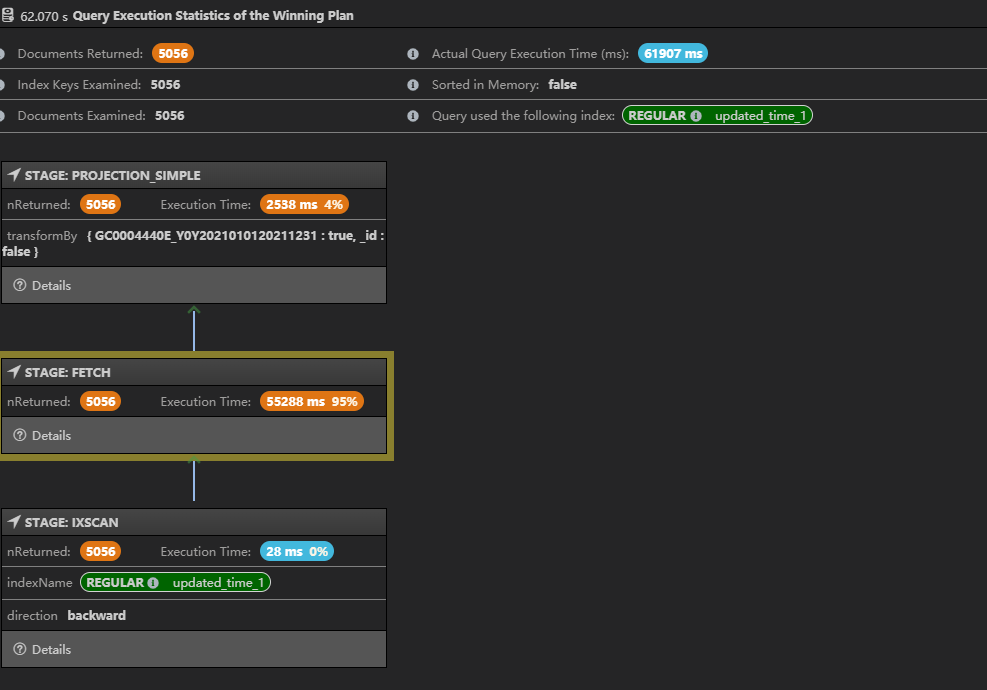
But I can not know, why it’s so different from the simple find command shown below:
db.M0001.find({}, {"GC0004440E_Y0Y2021010120211231" : 1}) \
.sort({updated_time:-1}).skip(300).limit(1000).explain('executionStats')
it takes about 10 seconds.
Can anyone give me some suggestions, thanks!
Plus:
the version of mongo is: 4.4.10