Today, we’re introducing an exciting feature addition for teams using Atlas Charts.
Charts project owners can now schedule dashboard reports to be sent via email to keep team members informed about key data. This feature has been heavily requested by some of our largest users as there are many use cases where dashboards may be valuable to your team, but you don’t necessarily want to require anyone to do extra work to access and view data. Enter scheduled dashboard reports in Atlas Charts!
In any dashboard that your team relies on for regular data review, simply schedule a dashboard report. The new Schedule button can be found at the top right of the dashboard screen:

Once you’ve chosen a dashboard from which to create a report, you will see a variety of options letting you customize the content and frequency of your report before you schedule. A report requires basic fields like a name or subject line, recipient list, and optionally, a message for the body of the email.
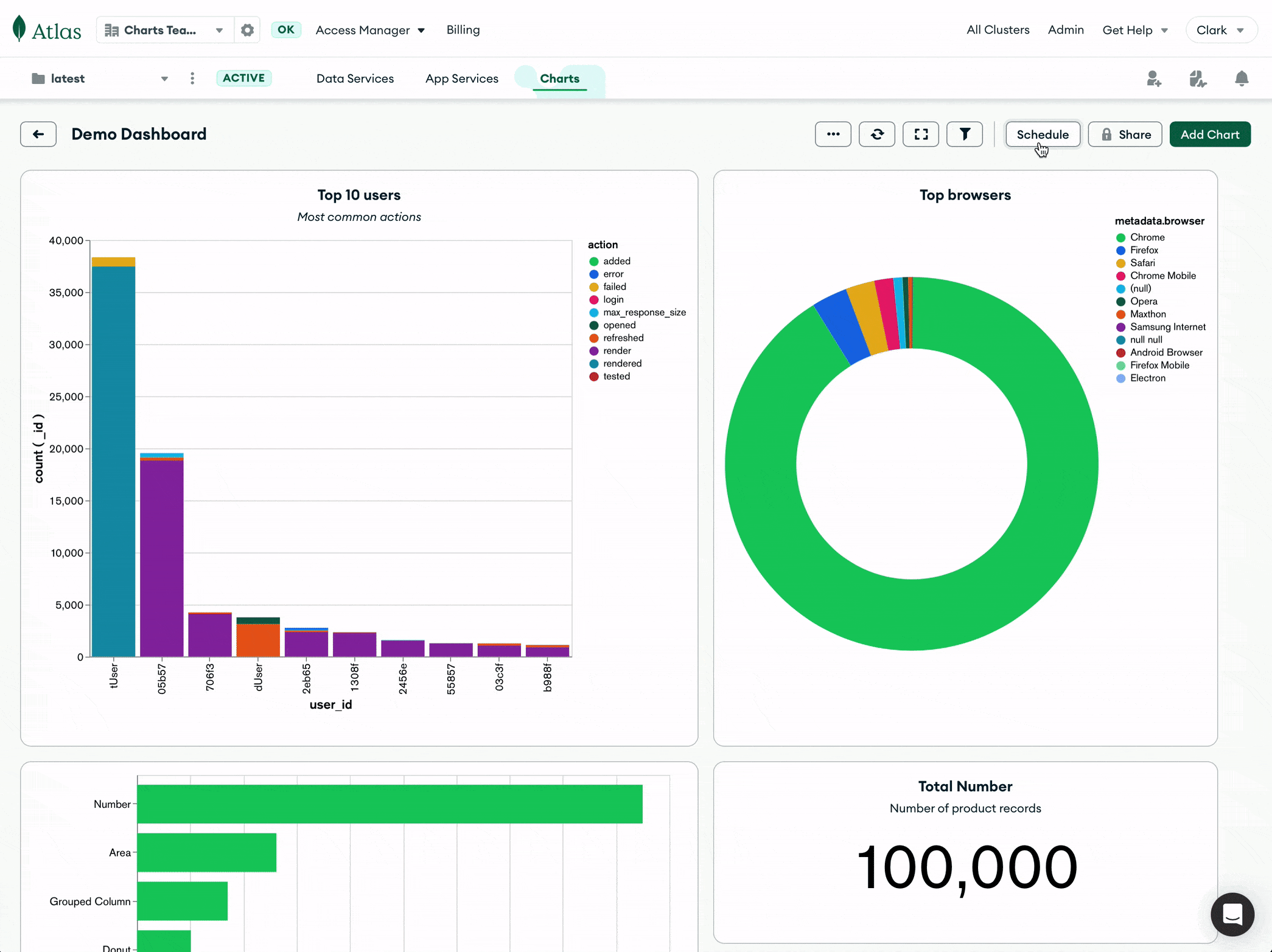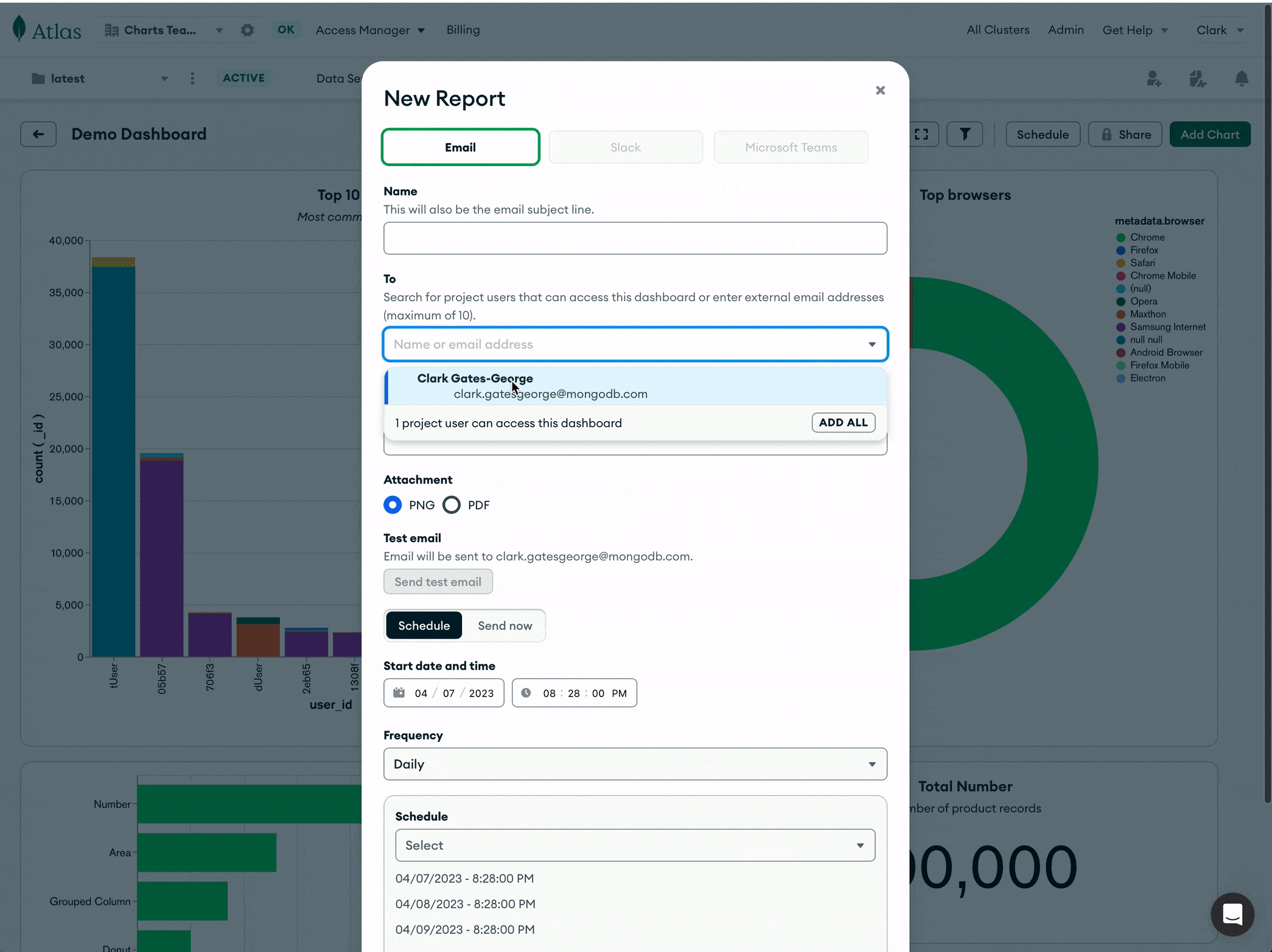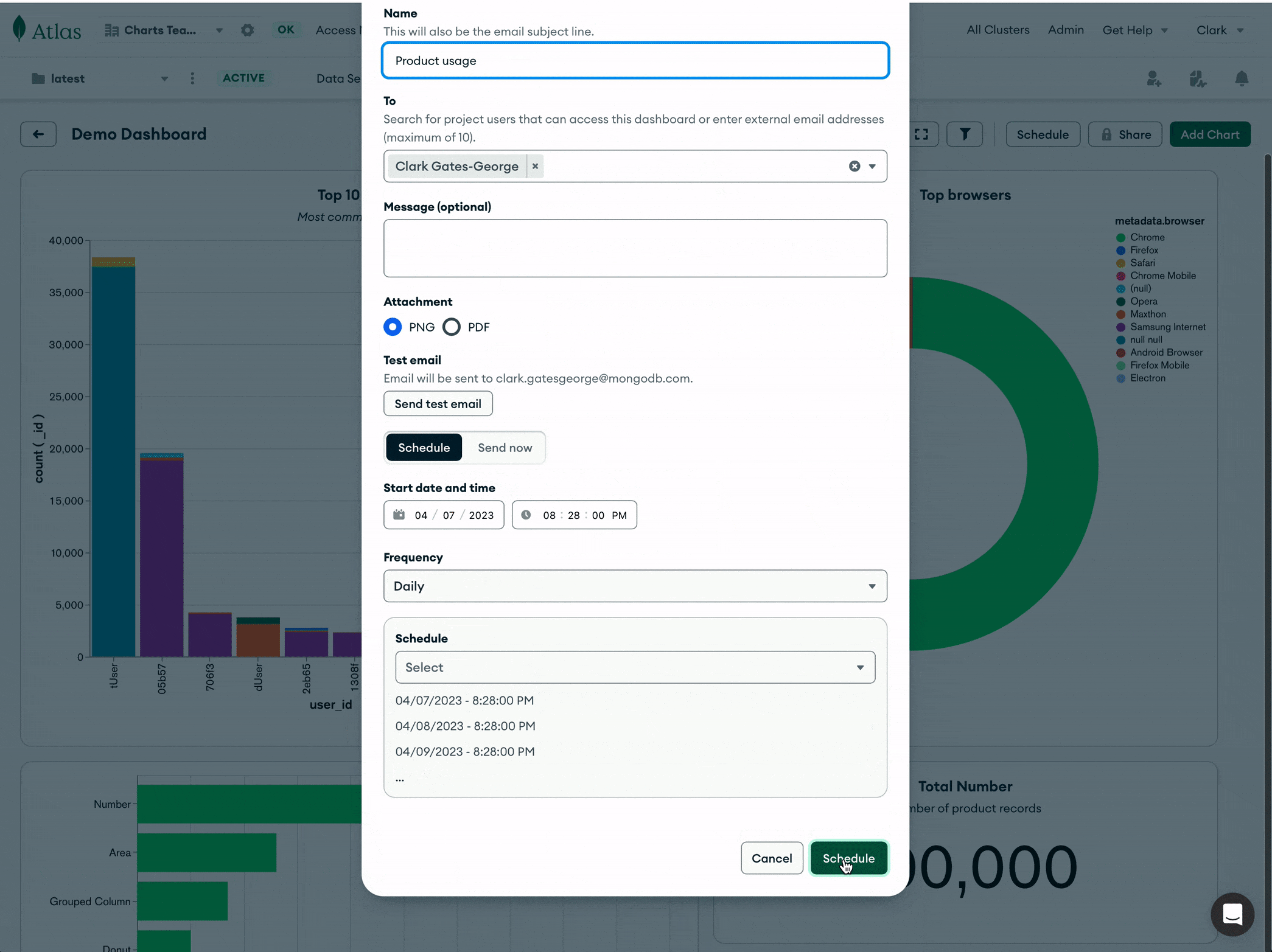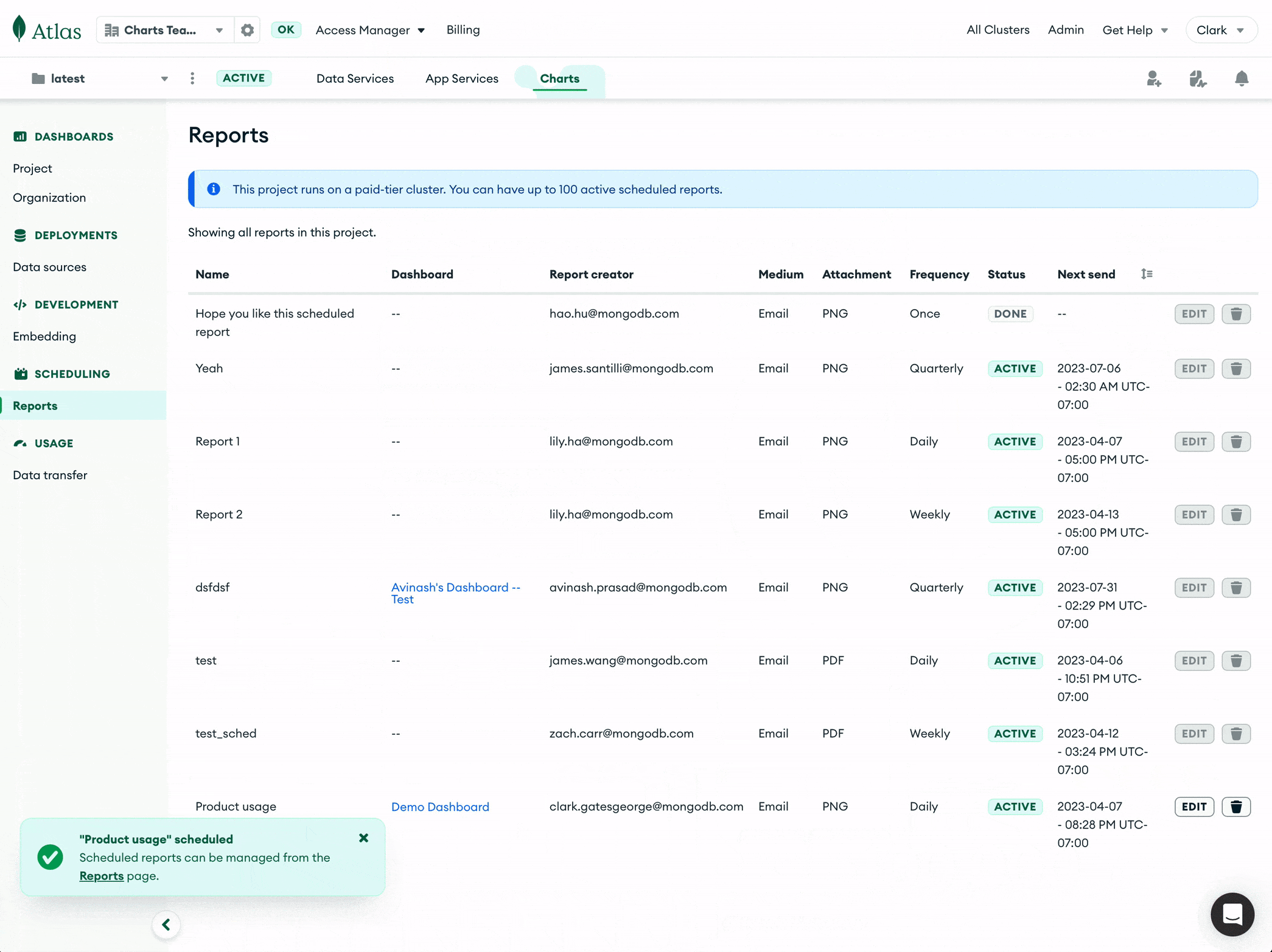
In addition to a link to the dashboard in Charts, you can choose whether to attach an image or PDF for quick reference in the message itself. Finally, you can set a schedule of daily, weekly, monthly, or quarterly delivery. You can also simply send a single email if you have a one-time need to share a report.
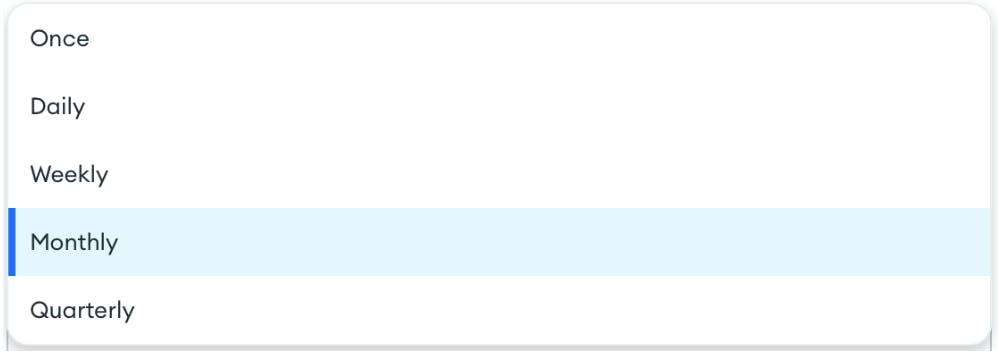
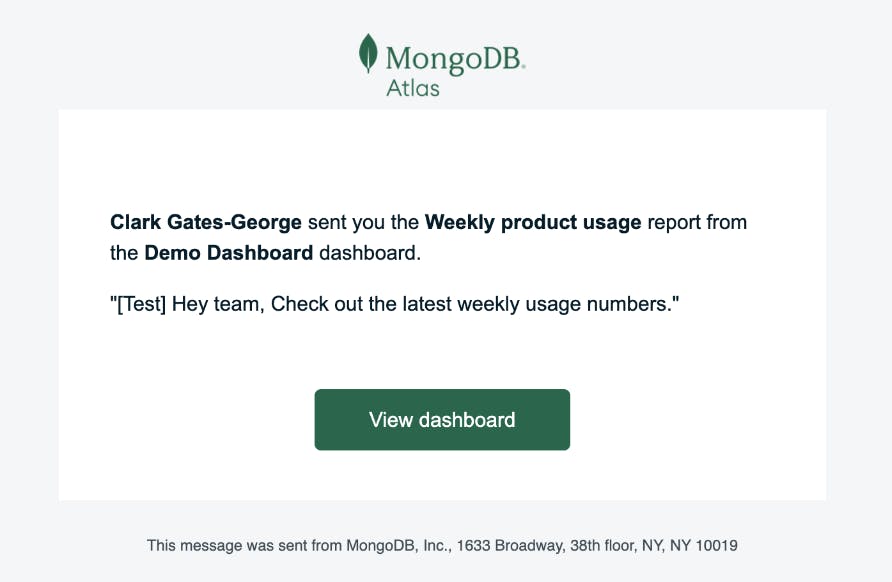
And once you’ve set everything up, your email will be sent on your defined schedule.
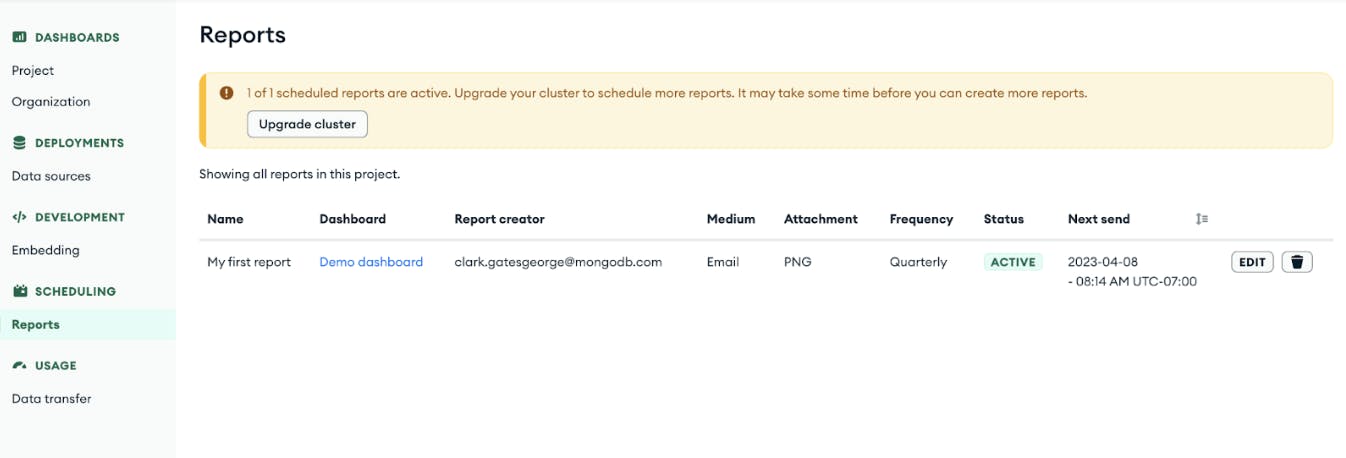
As you use scheduled dashboard reports more and more, we created a Reports page where you can manage all reports in your project. Note that if you’re on an free tier, you can try one scheduled report. If you’re on an M2 cluster or higher, you can create up to 100 reports per project.
To learn more, please check out our documentation. We’re always listening to feature requests that will enhance using Charts across teams, so if you have any requests or feedback, please share them with us here.
Log in to Atlas Charts today to schedule your first report! If you’re new to Atlas Charts, get started today by logging into or signing up for MongoDB Atlas.