On April 2, 2019 Intel Optane Persistent Memory became the first commercially available storage class memory (SCM) product. Like SSD, this memory is persistent, and like DRAM it sits on the memory bus. Long before a commercial release, system architects pondered how exactly SCM fits in the storage hierarchy, and now came an opportunity to perform concrete measurements. One question we wanted to answer is whether a storage device sitting on a memory bus can deliver better throughput than an equivalent storage device sitting on a PCI-e.
There are two ways to access SCM: byte interface and block interface. Byte interface allows using load and store instructions, just like with DRAM. Block interface exposes SCM as a block device, optionally with a file system on top: this way it can be accessed just like a conventional SSD. The load/store API is streamlined, because nothing stands between the application and the hardware, but also tricky to use, because it does not come with features like crash consistency, the way file system API usually does. Accessing SCM via the block or file system API comes with OS overhead, but there is no need to rewrite applications.
WiredTiger, MongoDB’s storage engine that we evaluated in this article, reads and writes data to/from storage using sizeable blocks (typically 4KB or larger). Besides being a necessity on conventional storage hardware today, using block API has other practical advantages. For example, compression and encryption, features that customers covet, are optimized to work with blocks. Similarly, checksums that safeguard from data corruption are computed on blocks of data. Furthermore, WiredTiger caches blocks of data in its DRAM-resident cache, which together with the OS buffer cache is a boon to performance.
Block-orientedness and reliance on caching positioned WiredTiger, like many other storage engines, to effectively hide latency of slow storage devices. As a result, our experiments revealed that a modest latency advantage that SCM provides over a technology-equivalent SSD does not translate into performance advantages for realistic workloads. The storage engine effectively masks these latency differences. SCM will shine when it is used for latency-sensitive operations that cannot be hidden with batching and caching, such as logging. In the rest of the article we detail the results of our experiments that lead us to make this conclusion.
Experimental Platform
We experimented with two storage devices: Intel Optane DC Persistent Memory (PM) and Intel Optane P4800X SSD. Both are built with the Intel Optane 3D XPoint non-volatile memory, but the former is a SCM that sits on the memory bus while the latter is a PCIe-attached SSD.
Microbenchmarks
To begin with, we gauged raw device bandwidth with microbenchmarks that read or write a 32GB file using 8KB blocks. We vary the number of threads simultaneously accessing the file, each its own chunk. A file can be accessed either via system calls (read/write) or mmap; the latter method usually has less overhead.
SSD drive's raw performance meets the spec.
According to the spec, our P48000X drive is capable of up to 2.5GB/s sequential read bandwidth and up to 2.2GB/s sequential write bandwidth. Here are the numbers we observed via the Ubuntu Linux (5.3 kernel) raw device API, meaning that the data bypasses the OS buffer cache.
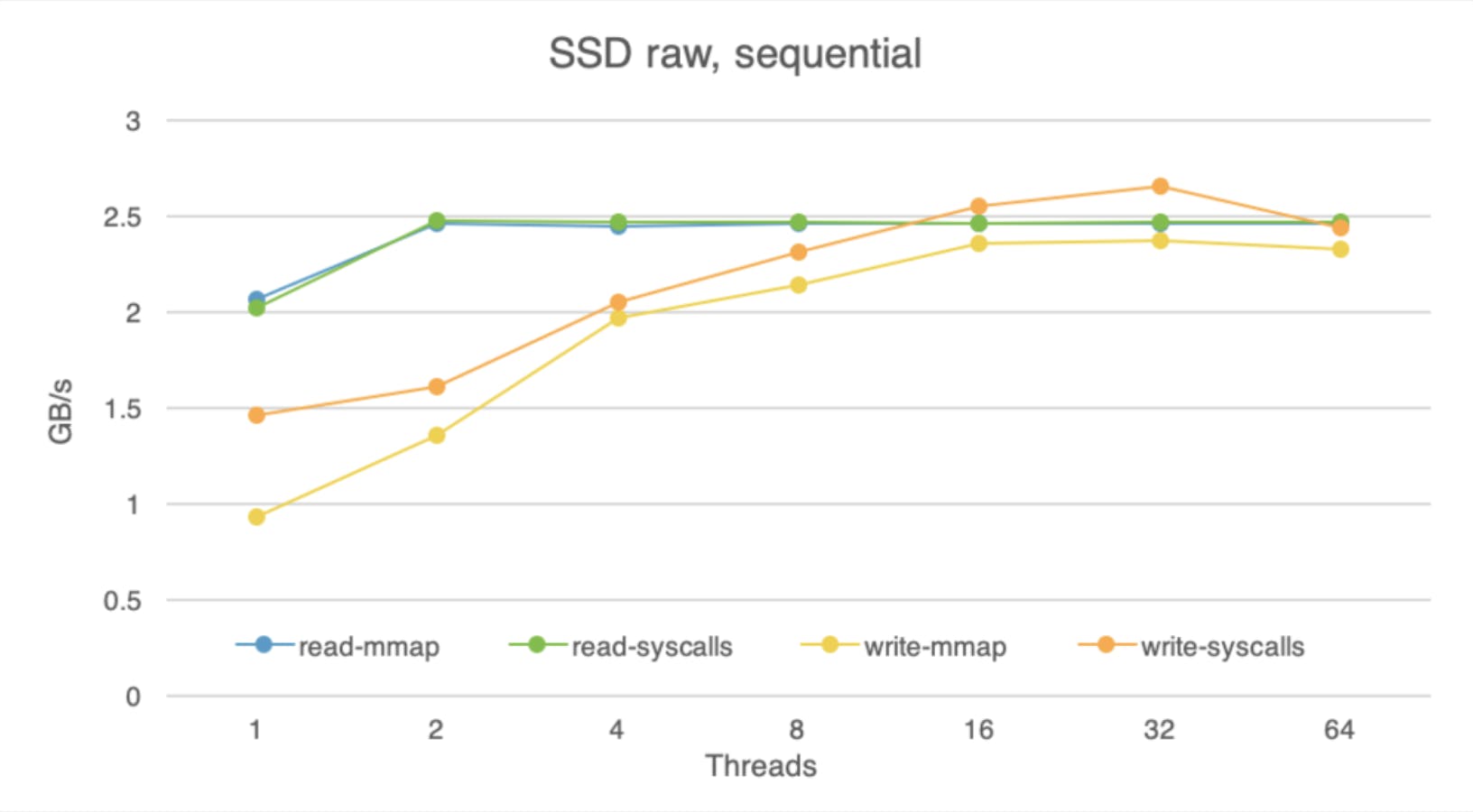
The read bandwidth behaves according to the specification as long as we use at least two threads. The write bandwidth, unexpectedly, exceeds its specified upper bound when using multiple threads. We suspect that this could be due to buffering writes either at the OS or at the device.
The Optane P4800X SSD is faster than a typical SSD at the time of this writing, but not to the point of being incomparable. While the Optane SSD offers up to a 2.5GB/s of sequential read bandwidth, a typical NAND SSD (e.g., Intel SSD Pro 6000p series) offers up to 1.8GB/s. The difference is more noticeable with writes. The Optane drive can deliver up to 2.2 GB/s, while the NAND drive can do no more than 0.56 GB/s.
Random reads and writes on the Optane SSD are not that much worse than sequential ones. We are able to achieve (using mmap) close to peak sequential throughput with reads and only 10% short of peak sequential throughput for writes. Near-identical performance of sequential and random access is a known feature of these drives.
SCM offers high-bandwidth reads, but low-bandwidth writes
Now let us look at the raw performance of SCM. Intel systems supporting Optane PM can fit up to six DIMMs; our experimental system had only two. We measured the throughput on a single DIMM and two DIMMs used together, to extrapolate scaling as the number of DIMMs increases. We also relied on data from other researchers to confirm our extrapolation.
There are two ways to obtain direct access to PM: (1) devdax — a PM module is exposed as a character device and (2) fsdax — in this case we have a file system on top of a PM module masquerading as a block device, but file accesses bypass the buffer cache via the Direct Access (DAX) mode. In our experiments we used the ext4 file system.
The following chart shows the throughput of sequential reads and writes obtained via these access methods. In all cases we use mmap, because that is the only method supported by devdax.
Sequential read bandwidth of a single PM module reaches about 6.4 GB/s; that matches observations of other researchers. Random access behaves almost identically to sequential access, so we omit the charts.
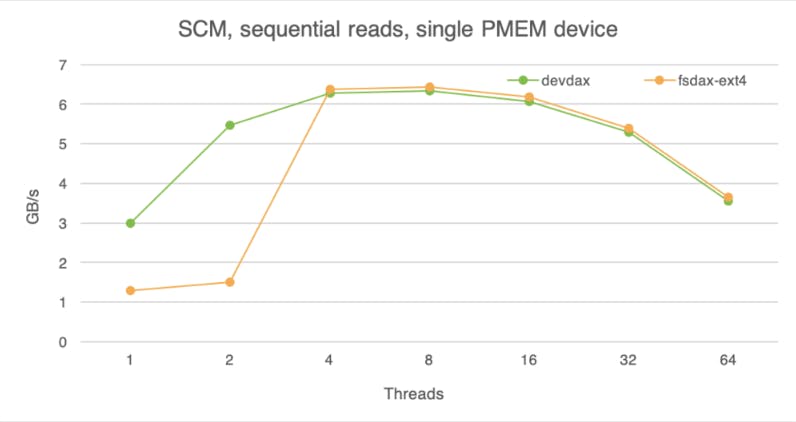
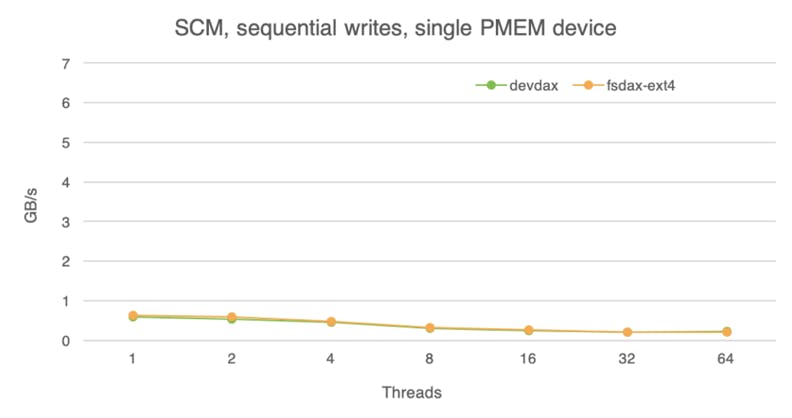
Write experiments tell a different story. The single-module write throughput achieves a mere 0.6 GB/s. This measurement does not agree with the data from the UCSD researchers who observed around 2.3GB/s write bandwidth on a single device. Further investigation led us to believe that this was due to differences in hardware versions. That said, our observations reveal that a single PM module achieves write throughput comparable only to a NAND SSD.
Next, let’s look at scaling across two devices. The following figure shows the measurements for sequential reads and writes, using mmap over fsdax. We used the Linux striped device mapper to spread the load across two DIMMs. For reads, with two DIMMs we can almost double the peak read bandwidth, from 6.4 GB/s with one DIMM to 12.4 GB/s with two. Similarly, researchers at UCSD observed nearly linear scaling across six DIMMs.
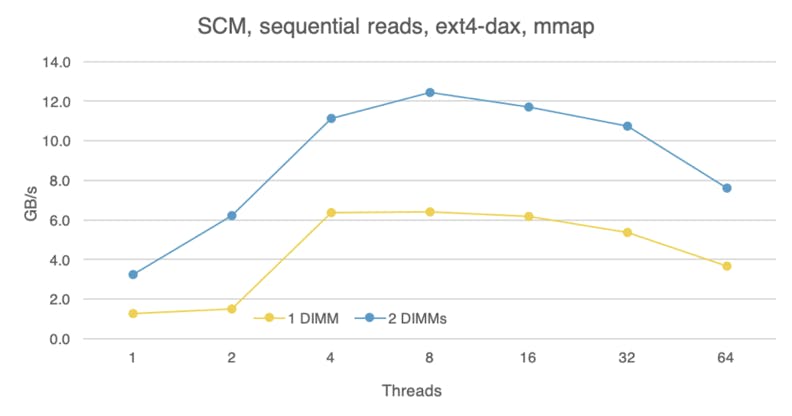
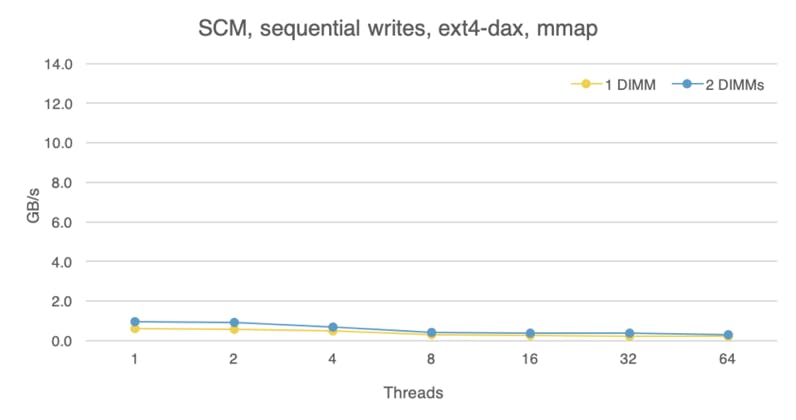
For writes, we achieve nearly 1 GB/s of write throughput with two DIMMs relative to 0.6 GB/s with one, but the scaling is less than linear if we can extrapolate from a single data point. The USCD researchers observed that bandwidth with six DIMMs improved by 5.6x relative to using a single DIMM, which is in line with our observation. Extrapolating from these data points, if our system had six DIMMs, we’d observe around 3.4 GB/s of peak write bandwidth, which is about 50% better than the Optane SSD.
In summary, with bare device access we see about 2.5 GB/s of peak read bandwidth on the Optane SSD and about 6.4 GB/s on a single Optane PM module. With six modules, the throughput would be ~38GB/s. Write throughput was only 0.6 GB/s on a single PM module, projected to reach 3.4 GB/s with six, while the Optane SSD reached 2.2 GB/s write bandwidth.
Optane SCM has a significant edge over the SSD with respect to reads, and a small advantage in writes, provided you can afford six PM modules; otherwise, an SSD will deliver a higher write throughput.
Software caching attenuates SCM performance advantage
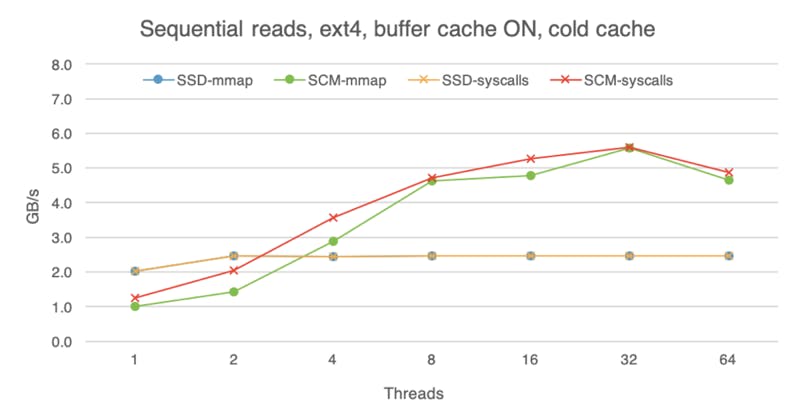
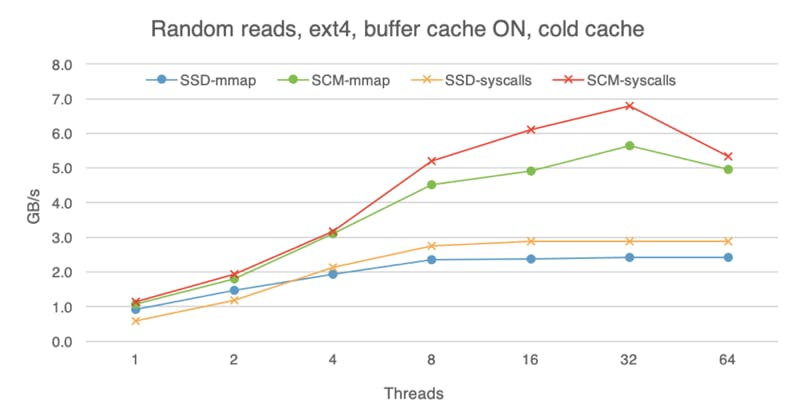
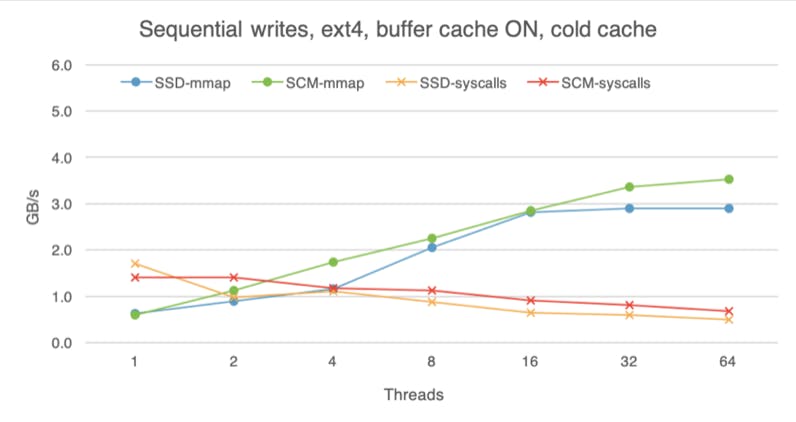
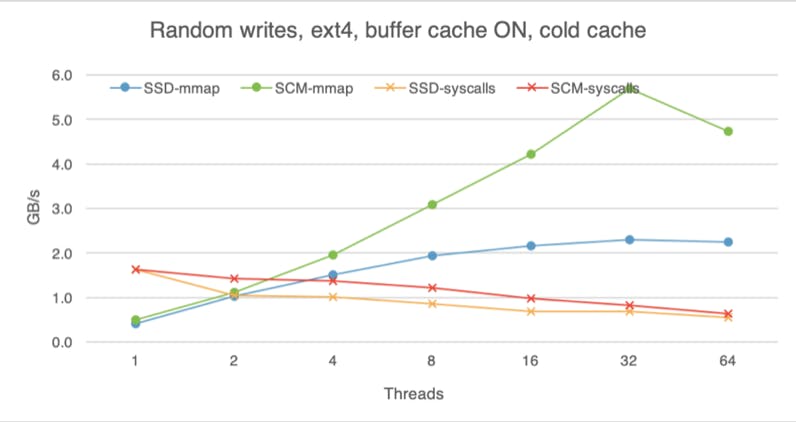
While SCM is closer to the speed of DRAM than traditional storage media, DRAM is still faster, so advantages of DRAM caching are difficult to overlook. The following charts shows that with the buffer cache on (here I am using ext4 without the DAX option), all devices perform roughly the same, regardless of whether we are doing reads or writes, random or sequential access. These experiments were done with the warm buffer cache, i.e., the file was already in the buffer cache before I began the experiment, so here we are measuring pure DRAM performance. With access to data taking less time, software overheads become more evident, which is why mmap is much faster than system calls if we use eight or more threads.
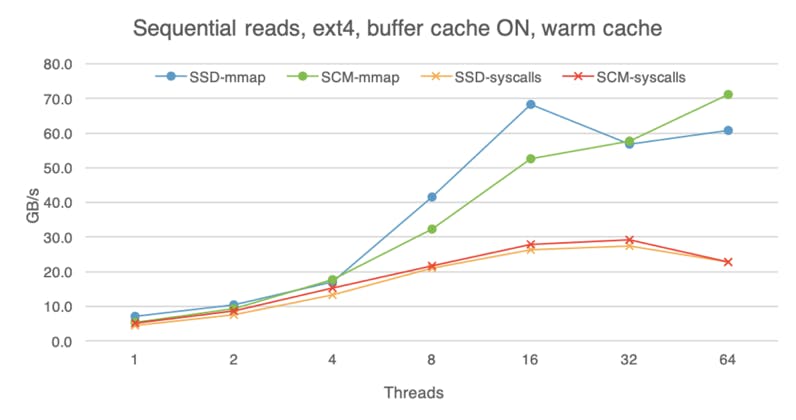
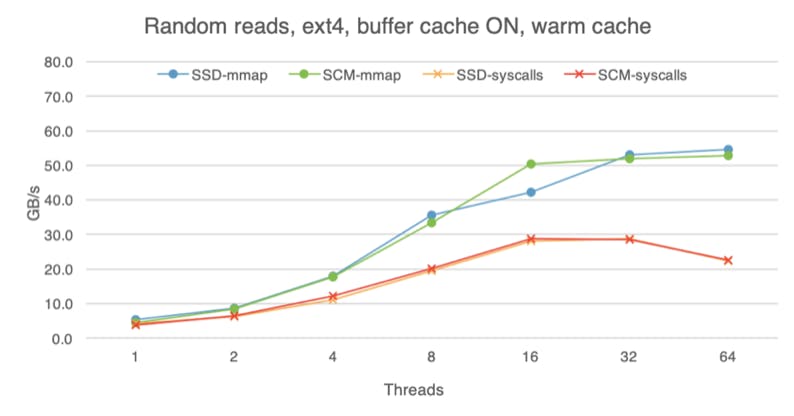
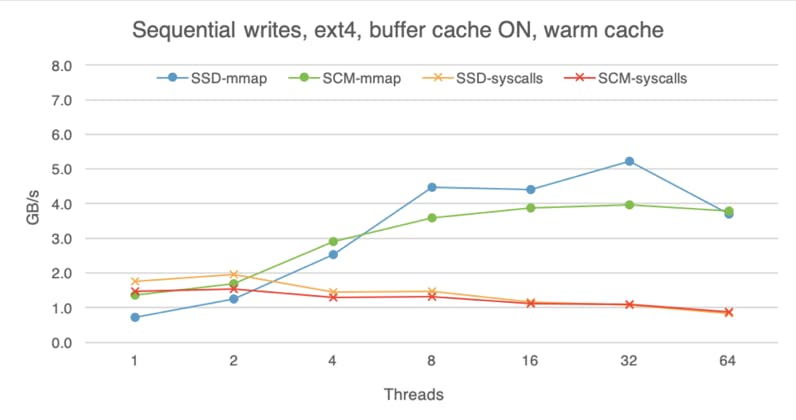
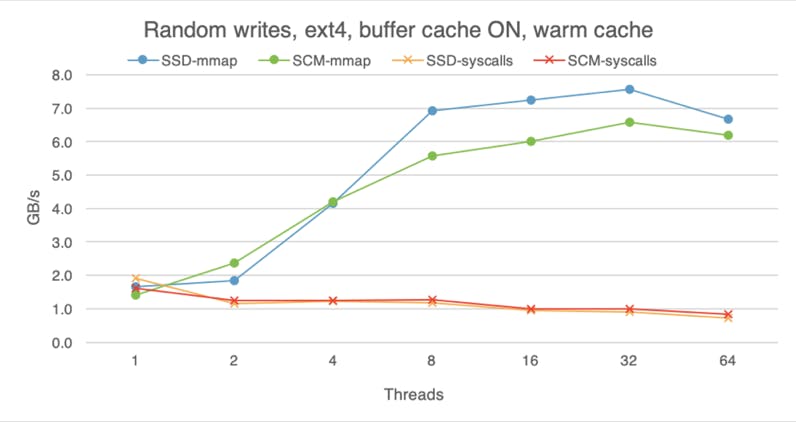
If we begin each experiment with a cold buffer cache, the difference between the devices is still visible, but less apparent than if we bypass the buffer cache altogether. With cold buffer cache, on the read path the OS has to copy the data from the storage device into the buffer cache before making it available to the application (hence extra software overhead). Furthermore, with buffer cache on, the OS is not using huge pages. These factors dampen the raw read advantage of SCM.
For writes, whereas SCM used to deliver lower bandwidth than SSD with raw access, now SCM outpaces SSD, likely because the buffer cache absorbs and batches some of them, instead of flushing each write to the device immediately.
Experiments with the storage engine
Like most storage engines, WiredTiger was designed and tuned to leverage a DRAM cache. Both WiredTiger internal cache and the OS buffer cache are crucial for performance in all workloads we measured. Running WiredTiger without the OS buffer cache (fsdax mode) reduced its performance by up to 30x in our experiments; hence, we did not use the direct-access mode.
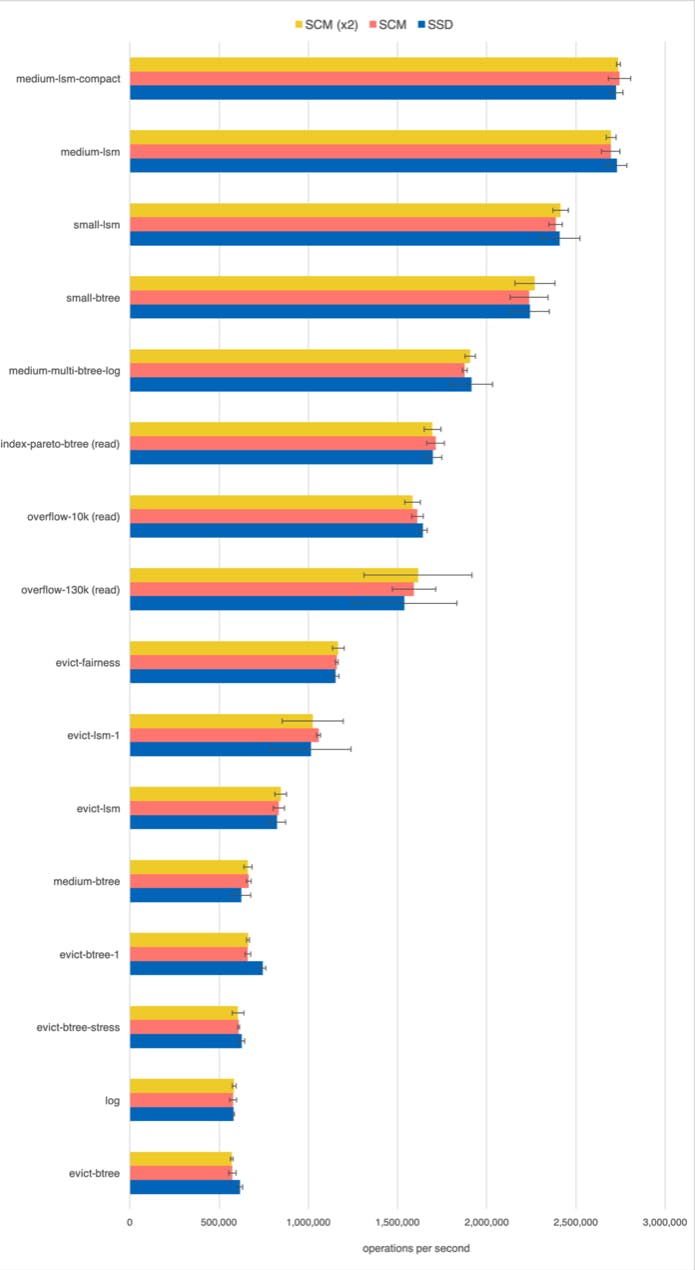
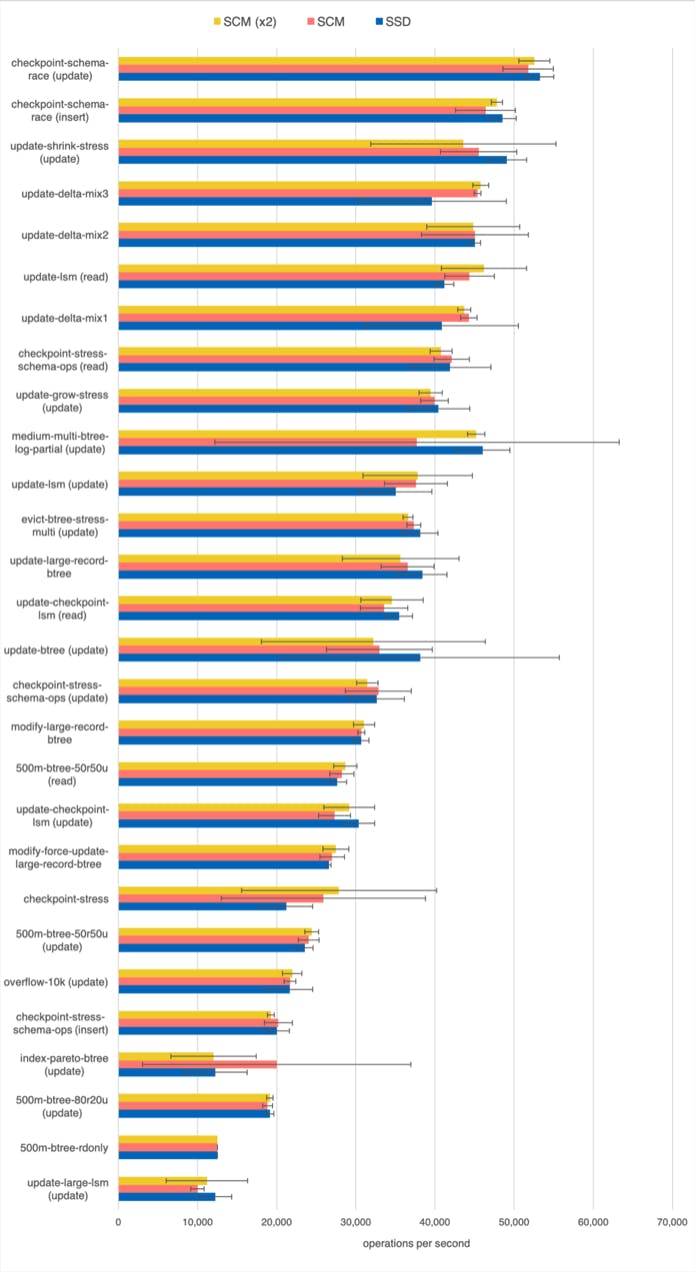
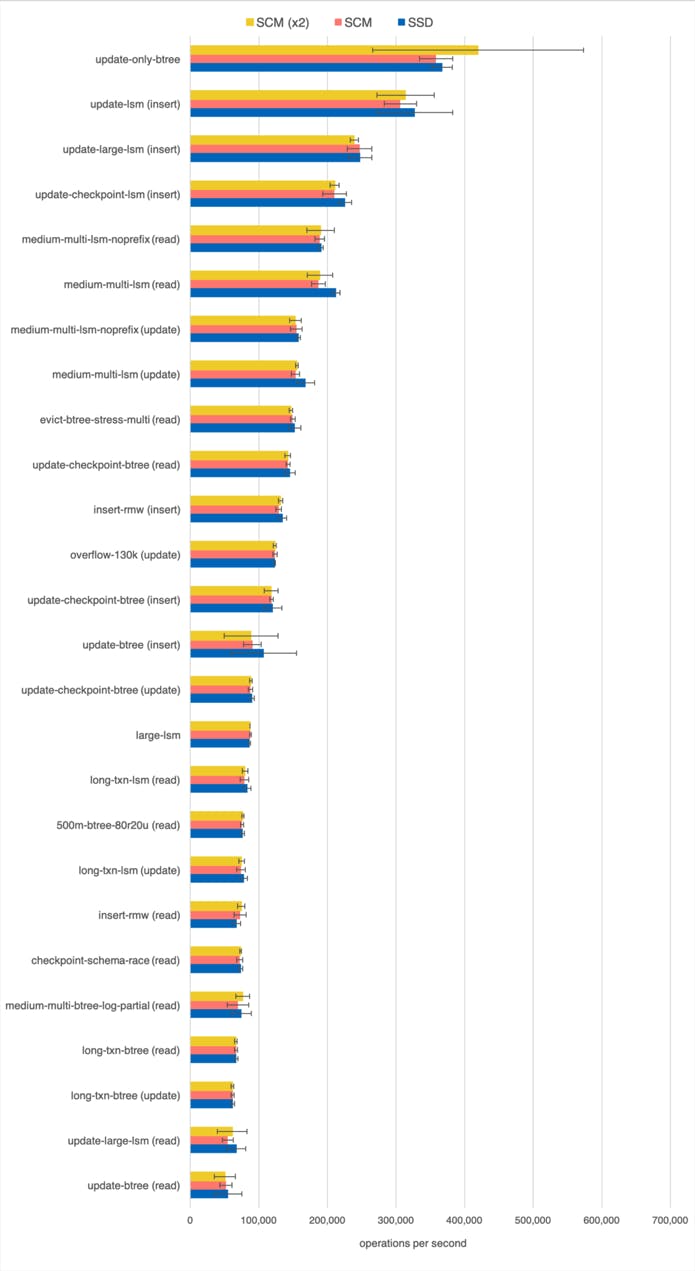
We run the WiredTiger’s wtperf benchmark suite, which was designed to stress various parts of the system and emulate typical workloads observed in practice. WiredTiger internal cache size varies between a few to a hundred gigabytes across the benchmarks, and most benchmarks use at least a dozen threads. (Detailed configuration parameters for all benchmarks can be viewed here.) There is no locking in WiredTiger on the common path, so thread-level concurrency usually translates into high CPU utilization and concurrent I/O. As described in our previous blog post we added a feature to WiredTiger to use mmap for I/O instead of system calls.
The following chart shows the performance of the wtperf suite on Intel Optane SCM (one and two modules) and on the Optane SSD. We see no significant performance difference between SCM and SSD. Apart from one write-intensive benchmark evict-btree-1, which is faster on SSD, there are no statistically significant differences between the two. Using a dual-module SCM over a single-module SCM gives no performance advantage either.
While SCM has a higher bandwidth than a technology-equivalent SSD, the advantage is within an order of magnitude, and, turns out, that effective DRAM caching hides that difference.
Latency, and not bandwidth, is where SCM can shine. In contrast to bandwidth, the latency of reading a block of data from an Optane PM is two orders of magnitude shorter than reading it from an Optane SSD: 1 microsecond vs 100-200 microseconds. The most obvious place in a storage engine where latency could be the bottleneck is logging, and academic literature is ripe with successful examples of using Optane PM for logging. In the meantime, stay tuned for our next report on exploring persistent memory.