This is a guest post by Data Scientist Nicholas Png.
Over the last four months, I attended an immersive data science program at Galvanize in San Francisco. As a graduation requirement, the last three weeks of the program are reserved for a student-selected project that puts to use the skills learned throughout the course. The project that I chose to tackle utilized natural language processing in tandem with sentiment analysis to parse and classify news articles. With the controversy surrounding our nation’s media and the concept of “fake news” floated around every corner, I decided to take a pragmatic approach to address bias in the media.
My resulting model identified three topics within an article and classified the sentiments towards each topic. Next, for each classified topic, the model returned a new article with the opposite sentiment, resulting in three articles provided to the user for each input article. With this model, I hoped to negate some of the inherent bias within an individual news article by providing counter arguments from other sources. The algorithms used were the following (in training order): TFIDF Vectorizer (text preprocessing), Latent Dirichlet Allocation (topic extraction), Scipy’s Implementation of Hierarchical Clustering (document similarity), and Multinomial Naive Bayes (sentiment classifier).
Initially, I was hesitant to use any database, let alone a non-relational one. However, as I progressed through the experiment, managing the plethora of CSV tables became more and more difficult. I needed the flexibility to add additional features to my data as the model engineered them. This is a major drawback of relational databases. Using SQL, there are two options: generate a new table for each new feature and use a multitude of JOINs to retrieve all the necessary data, or use ALTER TABLE to add a new column for each new feature. However, due the the varied algorithms I used, some features were generated one data point at a time, while others were returned as a single python list. Neither option was well suited to my needs. As a result, I turned to MongoDB to resolve my data storage, processing, and analysis issues.
To begin with, I used MongoDB to store the training data scraped from the web. I stored raw text data as individual documents on an AWS EC2 instance running a MongoDB database. Running a simple Python script on my EC2 instance, I generated a list of public news articles URLs to scrape and stored the scraped data (such as the article title and body) into my MongoDB database. I appreciated that, with MongoDB, I could employ indexes to ensure that duplicate URLs, and their associated text data, were not added to the database.
Next, the entire dataset needed to be parsed using NLP and passed in as training data for the TFIDF Vectorizer (in the scikit-learn toolkit) and the Latent Dirichlet Allocation (LDA) model. Since both TFIDF and LDA require training on the entire dataset (represented by a matrix of ~70k rows x ~250k columns), I needed to store a lot of information in memory. LDA requires training on non-reduced data in order to identify correlations between all features in their original space. Scikit Learn’s implementations of TFIDF and LDA are trained iteratively, from the first data point to the last. I was able to reduce the total load on memory and allocate more to actual training, by passing a Python generator function to the model that called my MongoDB database for each new data point. This also enabled me to use a smaller EC2 instance, thereby optimizing costs.
Once the vectorizer and LDA model were trained, I utilized the LDA model to extract 3 topics from each document, storing the top 50 words pertaining to each topic back in MongoDB. These top 50 words were used as the features to train my hierarchical clustering algorithm. The clustering algorithm functions much like a decision tree, and I generated pseudo-labels for each document by determining which leaf the document fell into.Since I could use dimensionally reduced data at this point, memory was not an issue, but all these labels needed to be referenced later in other parts of the pipeline. Rather than assigning several variables and allowing the labels to remain indefinitely in memory, I inserted new key-value pairs for the top words associated with each topic, topic labels according the clustering algorithm, and sentiment labels into each corresponding document in the collection. As each article was analyzed, the resulting labels and topic information were stored in the article’s document in MongoDB. As a result, there was no chance of data loss and any method could query the database for needed information regardless of whether other processes running in parallel were complete.
Sentiment analysis was the most difficult part of the project. There is currently no valuable labeled data related to politics and news so I initially tried to train the base models on a data set of Amazon product reviews. Unsurprisingly, this proved to be a poor choice of training data because the resulting models consistently graded sentences such as “The governor's speech reeked of subtle racism and blatant lack of political savvy” as having positive sentiment with a ~90% probability, which is questionable at best. As a result I had to manually label ~100k data points, which was time-intensive, but resulted in a much more reliable training set. The model trained on manual labels significantly outperformed the base model, trained on the Amazon product reviews data. No changes were made to the sentiment analysis algorithm itself; the only difference was the training set. This highlights the importance of accurate and relevant data for training ML models – and the necessity, more often than not, of human intervention in machine learning. Finally, by code freeze, the model was successfully extracting topics from each article and clustering the topics based on similarity to the topics in other articles.
Conclusion
In conclusion, MongoDB provides several different capabilities such as: flexible data model, indexing and high-speed querying, that make training and using machine learning algorithms much easier than with traditional, relational databases. Running MongoDB as the backend database to store and enrich ML training data allows for persistence and increased efficiency.
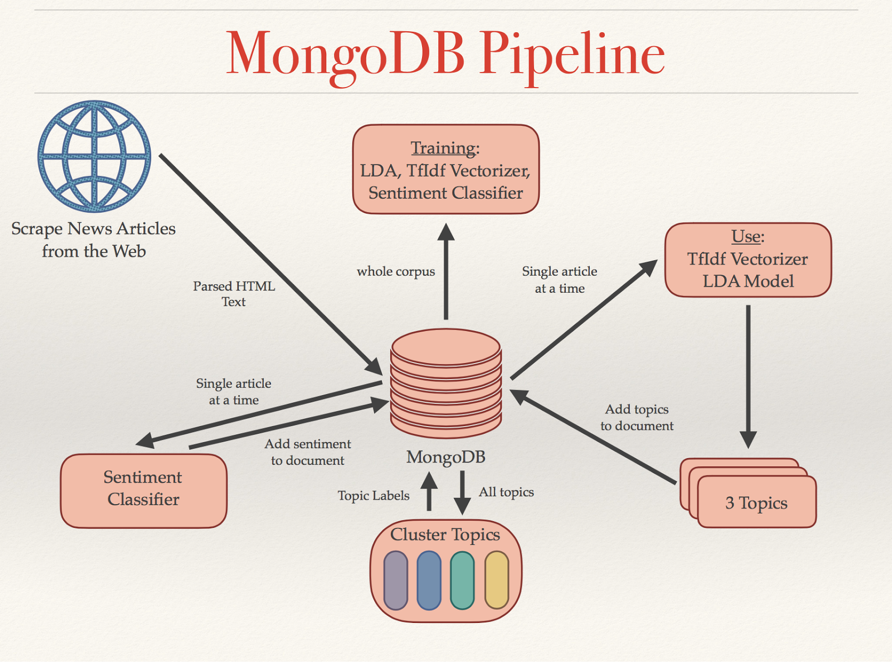
A final look at the MongoDB pipeline used for this project
If you are interested in this project, feel free to take a look at the code on GitHub, or feel free to contact me via LinkedIn or email.
About the author - Nicholas Png
Nicholas Png is a Data Scientist recently graduated from the Data Science Immersive Program at Galvanize in San Francisco. He is a passionate practitioner of Machine Learning and Artificial Intelligence, focused on Natural Language Processing, Image Recognition, and Unsupervised Learning. He is familiar with several open source databases including MongoDB, Redis, and HDFS. He has a Bachelors of Science in Mechanical Engineering as well as multiple years experience in both software and business development.