Welcome to the first in a series of blog posts covering performance best practices for MongoDB. In this series, we will cover key considerations for achieving performance at scale across a number of important dimensions, including:
- Data modeling and sizing memory (the working set)
- Query patterns and profiling
- Indexing
- Sharding
- Transactions and read/write concerns
- Hardware and OS configuration
- Benchmarking
Who is this series for?
While the best practices we are going to cover are not exhaustive, there will be recommendations in this series that will be useful to you whether you are:
- Starting your first project or are a seasoned MongoDB developer.
- Running MongoDB on Atlas, our fully-managed and global cloud database service, or managing MongoDB yourself.
What are we covering in this post?
We’re going to start with two key considerations that will set up all of the performance best practices we discuss through the rest of this blog series. Firstly we’ll discuss schema design and the key resources to get you started, before then moving onto RAM sizing for your application’s most frequently accessed data and indexes. This is something we call the “working set”.
Data Modeling Matters
The first step in performance optimization is to understand your application’s query patterns so that you design your data model and select the appropriate indexes accordingly. Tailoring your data model to the application’s query patterns produces more efficient queries, increases the throughput of insert and update operations, and more effectively distributes your workload across a sharded cluster.
Just because MongoDB has a flexible schema does not mean you can ignore schema design! While you can modify your schema at any time, applying schema design best practices at the outset of your project will save potential refactoring later on.
A major advantage of JSON documents is that you have the flexibility to model your data any way your application needs. The nesting of arrays and subdocuments makes documents very powerful at modeling complex relationships between data. But you can also model flat, tabular and columnar structures, simple key-value pairs, text, geospatial and time-series data, or the nodes and edges of connected graph data structures. The optimal schema design will be determined by your application’s query patterns.
Key Considerations and Resources for Data Modeling
As you design your data model, one of the first decisions you need to make is how to model relationships between data. Deciding when to embed a document or instead create a reference between separate documents in different collections is an application-specific consideration. There are, however, some general considerations to guide the decision during schema design.
Embedding
Data with a 1:1 relationship is an obvious and natural candidate for embedding within a single document. Data with a 1:many relationship where the "many" objects always appear with or are viewed in the context of their parent documents are also best served by embedding. Because this data is always accessed together, storing it together in the same document is optimal.
As a result of this data locality, embedding generally provides better performance for read operations due to the ability to request and retrieve related data in a single internal database operation, rather than looking up documents stored in different collections. Embedded data models also make it possible to update related data in a single atomic write operation because single document writes are transactional.
However, not all 1:1 and 1:many relationships are suitable for embedding in a single document. Referencing between documents in different collections should be used when:
- A document is frequently read but contains data that is rarely accessed. Embedding this data only increases the in-memory requirements (the working set) of the collection.
- One part of a document is frequently updated and constantly growing in size, while the remainder of the document is relatively static.
- The combined document size would exceed MongoDB’s 16MB document limit, for example when modeling many:1 relationships, such as product reviews to product.
Referencing
Referencing can help address the challenges cited above and is also typically used when modeling many:many relationships. However, the application will need to issue follow-up queries to resolve the reference, requiring additional round-trips to the server, or require a “joining” operation using MongoDB’s $lookup aggregation pipeline stage.
Digging Deeper
Data modeling is an expansive topic and has filled previous blog series on its own. To help you make the right decisions, here is a summary of the key resources you should review:
- The MongoDB documentation provides an extensive section on data modeling, starting from high-level concepts of the document data model before progressing to practical examples and design patterns, including more detail on referencing and embedding.
- You should also review our Building with Patterns blog series to learn more about specific schema design best practices for different use cases, including catalog and content management, IoT, mobile apps, analytics, and single view (i.e. customer 360). It overlays these use cases with specific schema design patterns such as versioning, bucketing, referencing, and graphs.
- MongoDB University offers a no-cost, web-based training course on data modeling. This is a great way to kick-start your learning on schema design with the document data model.
Review your Data Model
Once you have developed an initial data model and began populating it with sample application data, it is helpful to be able to review it.
MongoDB Compass is the free GUI for MongoDB. You can do a lot with Compass, so it’s a tool we’ll come back to regularly during this blog series. One of its most useful features is schema visualization, enabling you to explore your schema with histograms that show your documents’ fields, data types, and values. As you’ll see later in the series, you can also visualize query explain plans and index coverage straight from the Compass UI.
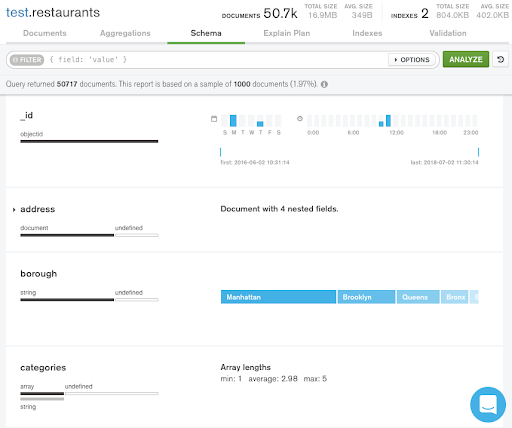
In Figure 1, we are reviewing the schema for documents stored in the restaurants collection. For the documents sampled, Compass displays how frequently fields appear in each document, the range of values they contain along with the data types, and the number of elements in the categories array. The Compass documentation has more detail on how to analyze your schema.
Compass can connect to MongoDB instances you are managing yourself or your cloud databases on MongoDB Atlas. You can also view document structures directly from the Atlas UI using the Data Explorer, or “Collections” view.
Getting Started with Documents
The best way to explore and experiment with data modeling is to spin up MongoDB on the fully-managed Atlas cloud service.
Our documentation steps you through how to create a free MongoDB database cluster in the region and on the cloud provider of your choice. You can also load our sample datasets, providing you with a simple way of getting started with documents.
Memory Sizing: Ensure your working set fits in RAM
Beyond data modeling, the second major consideration in performance optimization in sizing your working set.
As with most databases, MongoDB performs best when the application’s working set (indexes and most frequently accessed data) fits in memory. RAM size is the most important factor for instance sizing; other optimizations may not significantly improve the performance of the database if there is insufficient RAM. If price/performance is more of a priority over performance alone, then using fast SSDs to complement smaller amounts of RAM is a viable design choice. You should test the optimum balance for your workload and SLAs.
When the application’s working set fits in RAM, read activity from disk will be low. You can analyze this with the tools we will cover in the Query Profiling blog post, which is next up in this series.
If your working set exceeds the RAM of your chosen instance size or server, consider moving to a larger instance with more memory or partition (shard) your database across multiple servers.
Properly sizing the working set holds true whether you run MongoDB on Atlas or manage MongoDB yourself.
- Review the Atlas sizing and tier selection documentation for guidance on calculating your working set size.
- We will dig deeper into hardware sizing for self-managed MongoDB later in this series.
In MongoDB Atlas scaling compute and storage is straightforward. You can opt into cluster tier auto-scaling, which adjusts compute capacity for you in response to changes in application demand.
Cluster tier auto-scaling in Atlas monitors both CPU and memory utilization over defined periods and scales your instance sizes up or down within the limits you configure. All scaling events are performed in a rolling fashion, so there is no impact on your applications. At the time of writing, auto-scaling is a beta feature. If you want to control scaling events yourself, then you can do that in just a few clicks in the Atlas UI, or via an API call.
What’s Next
That wraps up our first post in this performance best practices series. Next up: query patterns and profiling.