Leaf in the Wild: Leading Soccer Streaming Service fuboTV Scales its Business with MongoDB, Docker Containers and Kubernetes
February 4, 2016 | Updated: December 1, 2025
Leaf in the Wild posts highlight real world MongoDB deployments. Read other stories about how companies are using MongoDB for their mission-critical projects.
You would be hard pressed to find any 2016 IT industry predictions that fail to identify containers and non-relational databases as “hot market technologies,” used by the next generation of market leaders to out-innovate their legacy competitors. New York-based fuboTV is a prime example. To keep pace with business growth and an unrelenting software release schedule, fuboTV has migrated its MongoDB database to Docker containers managed by the Kubernetes orchestration system on the Google Cloud Platform.

I sat down with Dan Worth, Director of Engineering at fuboTV, and Brian McNamara, lead consultant at CloudyOps to learn more about the project.
Can you start by telling us a little bit about your company?
fuboTV aims to bring the best of live soccer to any device, at any time. We provide a streaming service to our subscribing customers here in North America that bundles live matches, entertainment channels, documentaries, news and more from soccer leagues around the world.
What role does MongoDB play in fuboTV?
MongoDB is the core database supporting our business. We use it to manage our customer data; it stores the program guide and metadata for our content catalog; and all of the API calls to our service that handle authentication, subscription management, match and channel schedules, and user device data.
Did you start out with MongoDB?
Our CTO has always been a big fan of MongoDB, and so we’ve used it from the very start of the company.
The speed of development and operational simplicity we get from MongoDB enables us to focus on building functionality for our rapidly expanding customer base, rather than be slowed down by the underlying database.
We initially used MongoDB on the Compose.io platform, but are now in the process of migrating to our own managed clusters on Google Container Engine (part of the Google Cloud Platform), which is built on the Kubernetes orchestration system and Docker containers.
There are several drivers for the migration to Google Container Engine:
- We’ve moved the rest of our stack to Docker and Kubernetes, and wanted our MongoDB database to take advantage of all of the same benefits.
- We are scaling the service out across geographic regions, and wanted the deployment flexibility that comes from Google’s cloud, and portability to other public cloud platforms in the future.
- We wanted more control over the day-to-day operations and management of MongoDB to better support our rapidly evolving business requirements.
Why Docker and Kubernetes?
They bring unparalleled levels of flexibility, efficiency and uptime to our service. In previous companies, we had seen a lot of wasted resources. Using containers managed by Kubernetes, we can provision all of our environments – development, test, QA and production – to a single cluster of physical hosts. We take advantage of the Kubernetes scheduler to precisely control resource allocation across all of our apps, enabling us to maximize utilization and reduce costs.
MongoDB seamlessly integrates with Docker containers and Kubernetes to support our devops workflows.
We run a continuous integration and delivery pipeline, so we can develop, test, rollout, and if necessary, rollback with maximum speed and minimal effort.
We get zero downtime as we deploy and upgrade our applications. We can automatically reschedule containers if instances fail, with the Kubernetes replication controller ensuring that the requested number of instances are always running – enabling fault resilience for continuous availability. Data redundancy is provided by MongoDB replication within the replica set.
How is MongoDB deployed on Google Container Engine?
We provision MongoDB replica sets across Kubernetes pods in each of our Google cloud regions. Each instance is configured with 32 CPUs, 28 GB of RAM, and SSDs.
The replica sets are configured with four members for complete resilience: three are dedicated to handling operational traffic and one is configured as a hidden replica set member against which we snapshot volumes for backups.
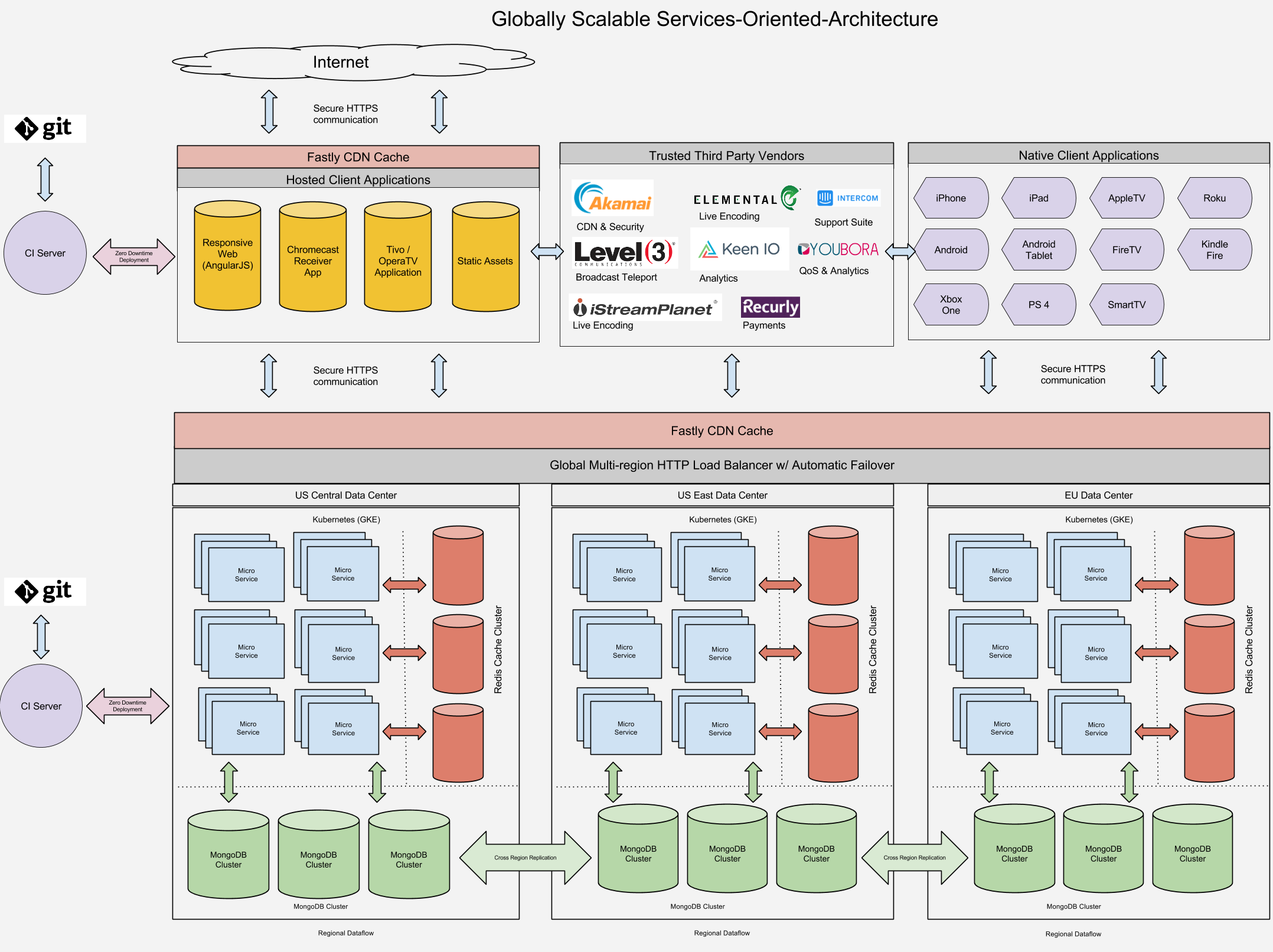
How have you integrated MongoDB with Kubernetes?
Running MongoDB on Kubernetes introduces some additional considerations over many other applications:
- MongoDB database nodes are stateful. In the event that a container fails and is rescheduled, it's undesirable for the data to be lost (it could be recovered from other nodes in the replica set but that would reduce the recovery speed of the fully-resilient replica set). To solve this, we make use of the Kubernetes volume abstraction to map what would otherwise be an ephemeral MongoDB data directory in the container to persistent network attached storage where the data survives container failure and rescheduling.
- MongoDB database nodes within a replica set must be able to communicate with each other at all times. All of the nodes within a replica set must know the addresses of all of their peers, but when a container is rescheduled, it is likely to be restarted in a Kubernetes Pod which has a different IP Address, and so the MongoDB node would not be able to re-join the replica set. We handle this by associating a Kubernetes Service with each MongoDB node – where the Kubernetes DNS service is used to provide a
hostnamefor the service that remains constant through rescheduling. - Once each of the individual MongoDB nodes is running (each within its own container), the replica set must be initialized and each node added. We have implemented a continuous delivery workflow using CircleCi that integrates with Kubernetes and Docker to retrieve the required configuration, and then execute the MongoDB initialization steps.
How do you scale the fuboTV Service?
The traffic profile of our streaming service is extremely “bursty”. The site handles 100x normal traffic volumes 10 minutes before the start of a big match. To handle the load, we distribute database operations across all of the replica set members. Our users are spread across North America, so to deliver a low latency experience for everyone, we use the nearest read preference to route subscribers to the closest geographic replica. MongoDB’s data center awareness is critical to ensuring the quality of our service.
Which release of MongoDB are you using?
We were very impressed with MongoDB 3.0 and the WiredTiger storage engine. Document level concurrency control and compression delivers the levels of performance and storage efficiency we need as our service has grown. For example, we achieved 20x storage reduction for one specific collection.
We upgraded to MongoDB 3.2 as soon as it was declared production ready in December last year to ensure we stay current with the latest innovations.
How are you measuring the impact of MongoDB and Kubernetes on your business?
The main benefits are development agility and speed of deployment. We can launch new services, collect feedback from users, fix problems, and iterate on features more quickly.
What advice would you give someone who is considering using MongoDB, Docker and Kubernetes for their next project?
MongoDB has a lot of nice features for resilience. To take advantage of these, make sure you fully characterize application behavior under different failure scenarios.
Docker is great to work with, but make sure your development workflows, tools and harnesses are adapted to build and run apps with it.
Kubernetes is still relatively young, but maturing quickly. You need to carefully evaluate whether you want to roll your own platform with it, or instead rely on a hosted service, as we have done with the Google Container Engine.
Brian and Dan, thanks for taking the time to share your experience with the community.
Register for MongoDB World to hear Brian and Dan share more of their experiences on MongoDB, Docker and Kubernetes.
To learn more about containers and orchestration, download our new white paper.
About the Author - Mat Keep
Mat is a director within the MongoDB product marketing team, responsible for building the vision, positioning and content for MongoDB’s products and services, including the analysis of market trends and customer requirements. Prior to MongoDB, Mat was director of product management at Oracle Corp. with responsibility for the MySQL database in web, telecoms, cloud and big data workloads. This followed a series of sales, business development and analyst / programmer positions with both technology vendors and end-user companies.