>> Announcement: Some features mentioned below will be deprecated on Sep. 30, 2025. Learn more.
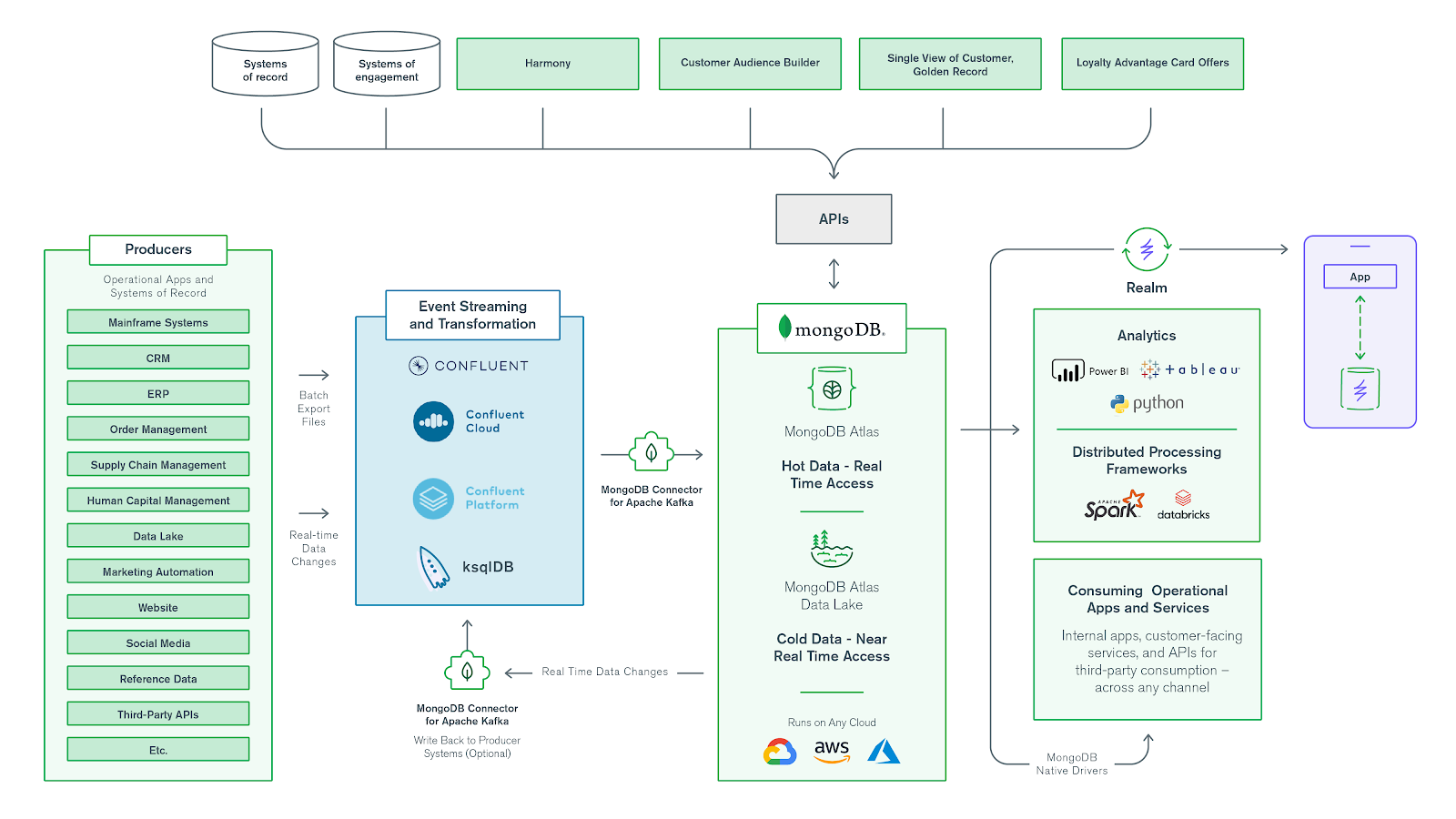
An operational data layer (ODL) is an architectural pattern that centrally integrates and organizes siloed enterprise data, making it available to consuming applications. It enables a range of board-level strategic initiatives such as legacy modernization and data as a service (DaaS), and use cases such as single view, real-time analytics, and mainframe offload. The simplest representation of this pattern is something like the diagram shown in Figure 1. An ODL is an intermediary between existing data sources and consumers that need to access that data.
An ODL deployed in front of legacy systems can enable new business initiatives and meet new requirements that the existing architecture can't handle -- without the difficulty and risk of a full rip and replace of legacy systems. It can reduce the workload on source systems, improve availability, reduce end-user response times, combine data from multiple systems into a single repository, serve as a foundation for re-architecting a monolithic application into a suite of microservices, and more. The ODL becomes a system of innovation, allowing the business to take an iterative approach to digital transformation.

Architecture
Source Systems and Data Producers
Source systems and data producers are usually databases, but sometimes they are systems or other data stores. Generally, they are systems of record for one or more applications, either off-the -shelf packages apps (ERP, CRM, and so forth) or internally developed custom apps.
In some cases, there may be only one source system feeding the ODL. Usually, this is the case if the main goal of implementing an ODL is to add an abstraction layer on top of that single system. This could be for the purpose of caching or offloading queries from the source system, or it could be to create an opportunity to revise the data model for modernization or new uses that don't fit with the structure of the existing source system. An ODL with a single source system is most useful when the source is a highly used system of record and/or is unable to handle new demands being placed on it; often, this is a mainframe. More often, there are multiple source systems. In this case, the ODL can unify disparate datasets, providing a complete picture of data that otherwise would not be available.
Consuming Systems
An ODL can support any consuming systems that require access to data. These can be either internal or customer-facing. Existing applications can be updated to access the ODL instead of the source systems, while new applications (often delivered as domains of microservices) typically will use the ODL first and foremost. The requirements of a single application may drive the initial implementation of an ODL, but usage usually expands to additional applications once the ODL’s value has been demonstrated to the business. An ODL can also feed analytics, providing insights that were not possible without a unified data system. Ad hoc analytical tools can connect to an ODL for an up-to-the-minute view of the company — without interfering with operational workloads — while the data can also support programmatic real-time analytics to drive richer user experiences with dashboards and aggregations embedded directly into applications.
Data Loading
For a successful ODL implementation, the data must be kept in sync with the source systems. Once the source systems’ producers have been identified, it’s important to understand the frequency and quantity of data changes in producer systems. Similarly, consuming systems should have clear requirements for data currency. Once you understand these, it’s much easier to develop an appropriate data loading strategy.
1. Batch extract and load. This typically is used for an initial one-time operation to load data from source systems. Batch operations extract all required records from the source systems and load them into the ODL for subsequent merging. If none of the consuming systems requires up-to-the-second level data currency and overall data volumes are low, it may also suffice to refresh the entire dataset with periodic (daily/weekly) data refreshes. Batch operations are also good for loading data from producers that are reference data sources, where data changes are typically less frequent — for example, country codes, office locations, tax codes, and similar data. Commercial extract, transform, and load (ETL) tools or custom implementations with Confluent (built on Apache Kafka) are used for carrying out batch operations: extracting data from producers, transforming the data as needed, and then loading it into the ODL. If after the initial load the development team discovers that additional refinements are needed to the transformation logic, then the related data from the ODL may need to be dropped, and the initial load repeated.
2. Delta extract and load. This is an ongoing operation that propagates incremental updates committed to the source systems into the ODL, in real time. To maintain synchronization between the source systems and the ODL, it’s important that the delta load starts immediately following the initial batch load. The frequency of delta operations can vary drastically. In some cases, they may be captured and propagated at regular intervals, for example every few hours. In other cases, they are event-based, propagated to the ODL as soon as new data is committed to the source systems. To keep the ODL current, most implementations use change data capture (CDC) mechanisms to catch the changes to source systems as they happen. Confluent is often used to store these real-time changes captured by the CDC mechanism, thanks to the multiple connectors available from various technologies. After the changes are safely stored in Kafka, you can use a streaming application, an ETL process, or custom handlers to transform the data into the required format for the ODL. Once the data is in the right format, you can leverage the MongoDB Connector for Apache Kafka sink to stream the new delta changes into the ODL. Increasingly, the message queue itself transforms the data, removing the need for a separate ETL mechanism.
Why MongoDB for DaaS?
Unified Data Infrastructure
The move to the cloud has brought forth efficiency and a self-service mindset by addressing the operational and administrative blockers in traditional on-premises environments. However, developer workflows have remained relatively unchanged as cloud lift-and-shift initiatives often replicate pre-existing data infrastructure complexities, including technology sprawl. MongoDB Atlas unifies transactional, operational, and real-time analytics into a single cloud-native platform and API for MongoDB users. This delivers a far better developer experience, because it makes data easier to manipulate, find, and analyze by eliminating the need for migrations across fragmented data services.
- Atlas Online Archive:Gives the users the ability to age out older data into cost-effective storage while still giving them the ability to easily query both warm and cold data from a single query.
- Atlas Data Lake: Query heterogeneous data stored in Amazon S3 and MongoDB Atlas in place and in its native format by using the MongoDB Query Language (MQL).
- Atlas Search: Build fast, Apache Lucene-based search capabilities on top of data in Atlas without the need to migrate it to a separate search platform.
Seamless Application Development
MongoDB Realm Mobile Database allows developers to store data locally on iOS and Android devices as well as IoT edge gateways by using a rich data model that’s intuitive to them. Combined with the MongoDB Realm sync to Atlas, Realm makes it simple to build reactive, reliable apps that work even when users are offline.
MongoDB Realm allows developers to validate and build key features quickly. Application development services such as Realm Sync provide out-of-the box bidirectional synchronization between the cloud and your devices. Realm offers other services, including its GraphQL service, which can query data using any GraphQL client. Realm also provides many other services and features such as functions, triggers, and data access rules — ultimately simplifying the code required and enabling you to focus on adding business value to your applications instead of wasting time writing boilerplate code.
MongoDB is the Best Way for an ODL to Work with Data
Ease. MongoDB’s document model makes it simple to model — or remodel — data in a way that fits the needs of your applications. Documents are a natural way to describe data.
Flexibility With MongoDB, there’s no need to predefine a schema. Documents are polymorphic: fields can vary from document to document within a single collection.
Speed.Using MongoDB for an ODL means you can get better performance when accessing data, and write less code to do so. In most legacy systems, accessing data for an entity, such as a customer, typically requires JOINing multiple tables together. JOINs entail a performance penalty, even when optimized — which takes time, effort, and advanced SQL skills.
Versatility Building on the ease, flexibility, and speed of the document model, MongoDB enables developers to satisfy a range of application requirements, both in the way data is modeled and in how it is queried.
Data access and APIs. Consuming systems require powerful and secure access methods to the data in the ODL. If the ODL is writing back to source systems, this channel also needs to be handled. MongoDB’s drivers provide access to a MongoDB-based ODL from the language of your choice.
MongoDB lets you intelligently distribute and ODL. Consuming systems depend on an ODL. It needs to be reliable and scalable and to offer a high degree of control over data distribution to meet latency and data sovereignty requirements.
Availability. MongoDB maintains multiple copies of data by using replica sets. Replica sets are self-healing, because failover and recovery are fully automated, so it is not necessary to manually intervene to restore a system in the event of a failure, or to add the additional clustering frameworks and agents that are needed for many legacy relational databases.
Scalability. To meet the needs of an ODL with large datasets and high throughput requirements, MongoDB provides horizontal scale-out on low-cost, commodity hardware or cloud infrastructure by using sharding.
Workload isolation. MongoDB’s replication provides a foundation for combining different classes of workload on the same MongoDB cluster, each workload operating against its own copy of the data.
Data locality. MongoDB allows precise control over where data is physically stored in a single logical cluster. For example, data placement can be controlled by geographic region for latency and governance requirements, or by hardware configuration and application features to meet specific classes of service for different consuming systems.
MongoDB Gives You the Freedom to Run Anywhere
Portability. MongoDB runs the same everywhere: on premises in your data centers, on developers’ laptops, in the cloud, or as an on-demand fully managed DaaS: MongoDB Atlas.
Global coverage. MongoDB’s distributed architecture allows a single logical cluster to be distributed around the world, situating data close to users. When you use MongoDB Atlas, global coverage is even easier; Atlas supports more than 70 regions across all the major cloud providers.
No lock-in. With MongoDB, you can reap the benefits of a multi-cloud strategy. Since Atlas clusters can be deployed on all major cloud providers, you get the advantage of an elastic, fully managed service without being locked into a single cloud provider.
What Role Does Confluent Play?
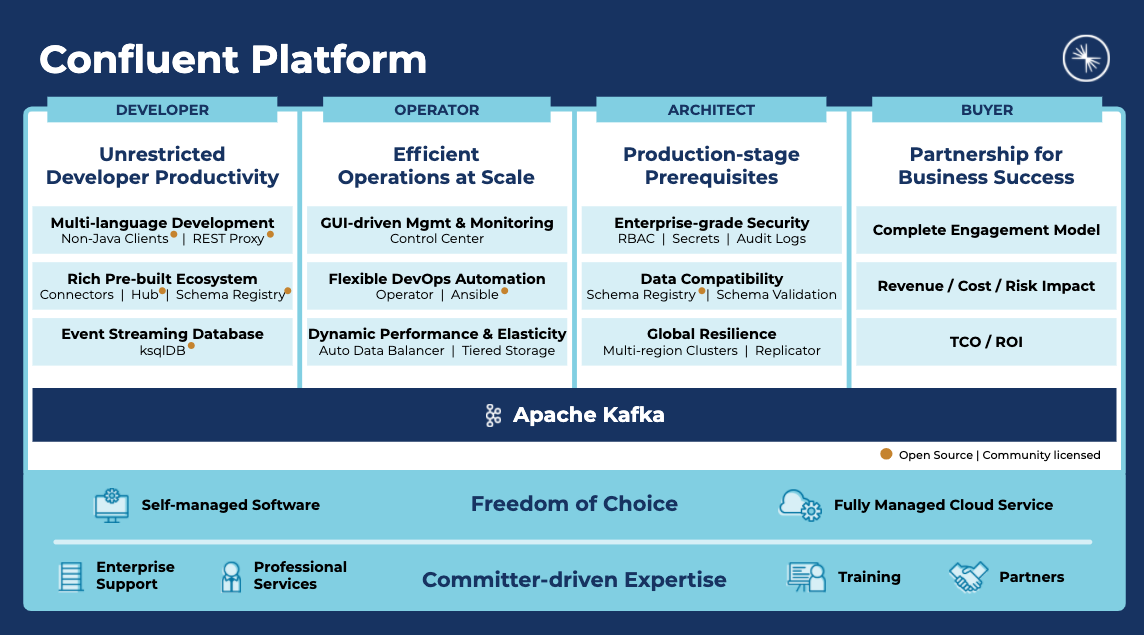
What Confluent builds is an enterprise-ready platform that complements Apache Kafka with advanced capabilities designed to help accelerate application development and connectivity, enable event transformations via stream processing, simplify enterprise operations at scale, and meet stringent architectural and security requirements.
One of Confluent’s goals is to democratize Kafka for a wider range of developers and accelerate how quickly they can build event streaming applications. Confluent enables this via a set of features, including the ability to leverage Kafka in languages other than Java, a rich prebuilt ecosystem including more than 100 connectors so developers don’t have to spend time building connectors themselves, and enabling stream processing with the ease and familiarity of SQL.
Kafka can sometimes be complex and difficult to operate at scale. Confluent makes it easier via GUI-based management and monitoring, DevOps automation including with Kubernetes Operator, and enabling dynamic performance and elasticity in deploying Kafka.
Also, Confluent offers a set of features many organizations consider prerequisites when deploying mission-critical apps on Kafka. These include security features that control who has access to what, the ability to investigate potential security incidents via audit logs, the ability to ensure via schema validation that there is no “dirty” data in Kafka and that only “clean” data is in the system, and resilience features (if your data center goes down, for example, your customer-facing applications stay running).
Confluent offers all of this with freedom of choice, meaning you can choose self-managed software you can deploy anywhere, including on premises or in a public cloud, private cloud, containers, or Kubernetes. Or, you can choose MongoDB’s fully managed cloud service, available on all three major cloud providers.
And underpinning all of this is the Confluent committer-led expertise. Confluent has more than 1 million hours of Kafka expertise and offers support, professional services, training, and a full partner ecosystem. Simply put, there is no other organization in the world better suited to be an enterprise partner, and no organization in the world that is more capable of ensuring your success. This means everything to the organizations Confluent works with.