>> Announcement: Some features mentioned below will be deprecated on Sep. 30, 2025. Learn more.
Omnichannel experiences are increasingly important for customers, yet still hard for many retailers to deliver. In this article, we’ll cover an approach to unlock data from legacy silos and make it easy to operate across the enterprise — perfect for implementing an omnichannel strategy.
Establishing an omnichannel retail strategy
An omnichannel strategy connects multiple, siloed sales channels (web, app, store, phone, etc.) into one cohesive and consistent experience. This strategy allows customers to purchase through multiple channels with a consistent experience (Figure 1).
Most established retailers started with a single point of sale or “channel” — the first store — then moved to multiple stores and introduced new channels like ecommerce, mobile, and B2B. Omnichannel is the next wave in this journey, offering customers the ability to start a journey on one channel and end it on another.
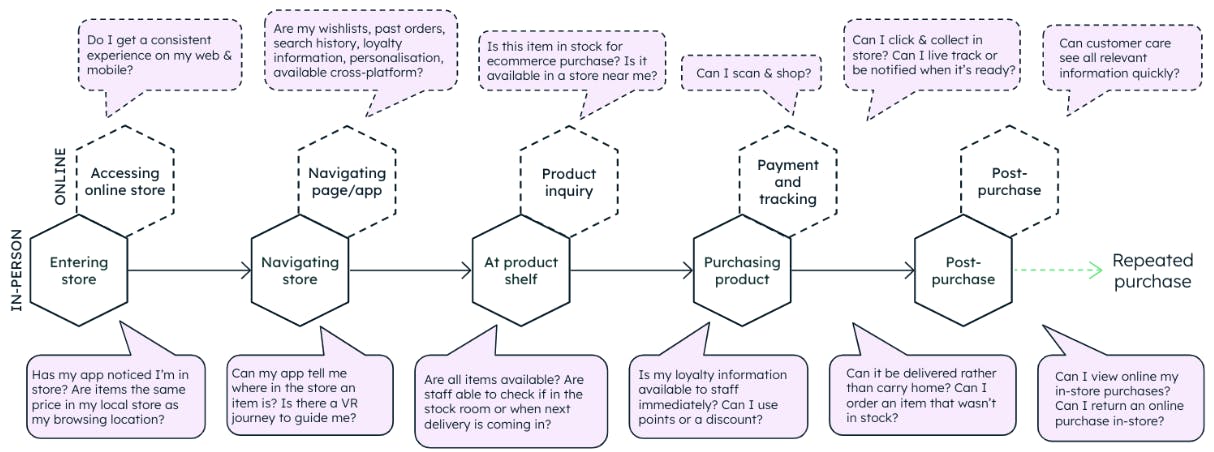
Why are retailers taking this approach? In a super-competitive industry, an omnichannel approach lets retailers maximize great customer experience, with a subsequent effect on spend and retention. Looking at recent stats, Omnisend found that purchase frequency is 250% higher on omnichannel, and Harvard Business Review’s research saw omnichannel customers spend 10% more online and 4% more in-store.
Omnichannel: What's the challenge?
So, if all retailers want to provide these capabilities to their customers, why aren’t they? The answer lies in the complex, siloed data architectures that underpin their application architecture. Established retailers who have built up their business over time traditionally incorporated multiple off-the-shelf products (e.g., ERP, PIMS, CMS, etc.) running on legacy data technologies into their stack (mainframe, RDBMS, file-based). With this approach, each category of data is stored in a different technology, platform, and rigid format — making it impossible to combine this data to serve omnichannel use cases (e.g., in-store stock + ecommerce to offer same-day click and collect). See Figure 2.
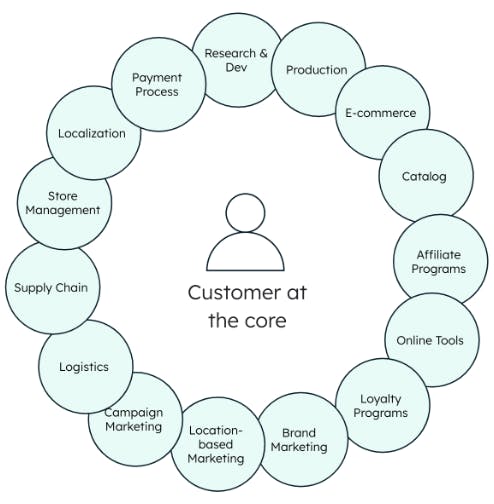
The next challenge is the separation of operational and historical data — older data is moved to archives, data lakes, or warehouses. Perhaps you can see today’s stock in real time, but you can’t compare it to stock on the same day last year because that is held in a different system. Any business comparison occurs after the fact.
To meet the varied volume and variety of requests, retailers must extract, transform, and load (ETL) data into different databases, creating a complex disjointed web of duplicated data.
Figure 3 shows a typical retailer architecture: A document database for key-value lookup, cache added for speed, wide column storage for analytics, graph databases to look up three degrees of separation, time series to track changes over time, etc.
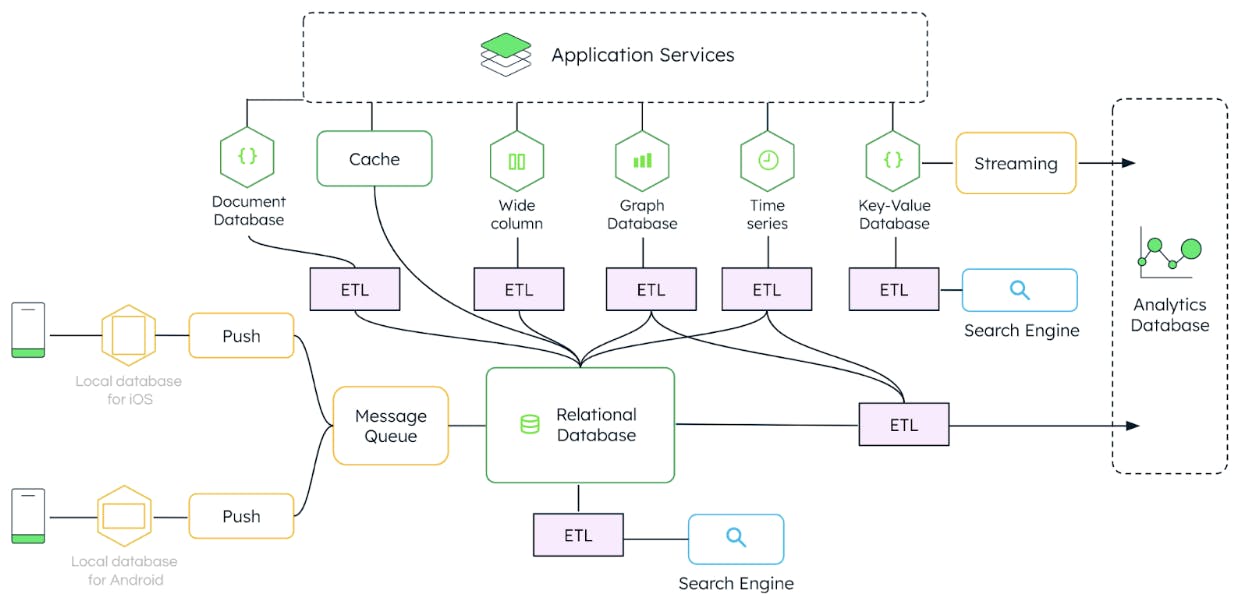
The problem is that ETL’d data becomes stale as it moves between technologies, lagging behind real-time and losing context. This sprawl of technology is complex to manage and difficult to develop against — inhibiting retailers from moving quickly and adapting to new requirements. If retailers want to create experiences that can be used by consumers in real-time — operational or analytical — this architecture does not give them what they need. Additionally, if they want to use AI or machine learning models, they need access to current behavior for accuracy.
Thus, the obstacle to delivering omnichannel experiences is a data problem that requires a data solution. Let's look at a smart approach to fixing it.
Modern retailers are taking a data mesh approach
Retail architectures have gone through many iterations, starting from vendor solutions per use case, moving toward a microservices approach, and landing into domain-driven design (Figure 4).
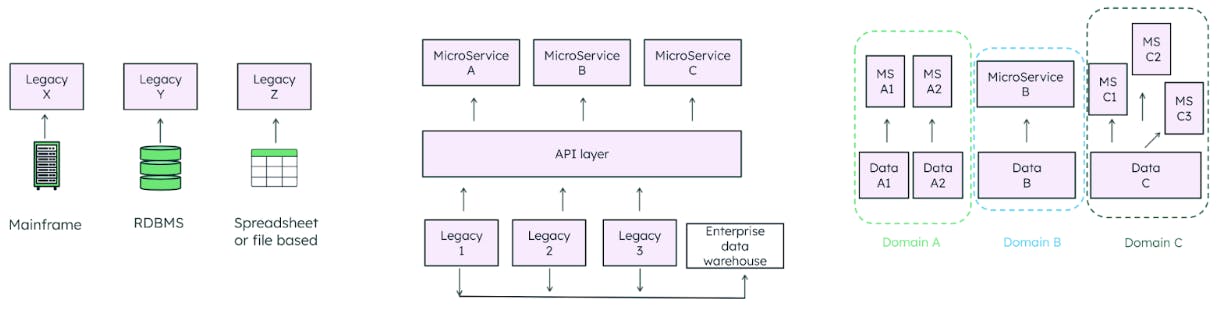
Domain-driven design has emerged through an understanding that the team with domain expertise should have control over the application layer and its associated data — this is the “bounded context” for their business function. This means they can change the data to innovate quickly, without reliance on another team.
Of course, if data remains in its bounded context only, we end up with the same situation as the commercial off-the-shelf (COTS) and legacy architecture model. Where we see value is when the data in each domain can be used as a product throughout the organization. Data as a product is a core data mesh concept — it includes data, metadata, and the code and infrastructure to use it. Data as a product is expected to be discoverable (searchable), addressable, self-identifying, and interoperable (Figure 5).
In a retail example, the product, customer, and store can be thought of as bounded contexts. The product bounded context contains the product data and the microservices/applications that are built for product use cases. But, for a cross-domain use case like personalized product recommendations, the data from both customer and product domains must be available “as a product.”
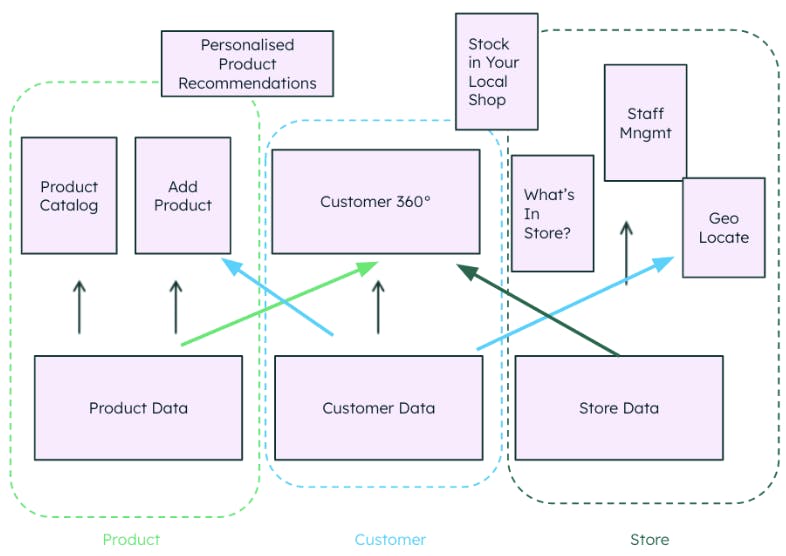
What we’re creating here is a data mesh — an enterprise data architecture that combines intentionally distributed data across distinctly defined, bounded contexts. It is a business domain-oriented, decentralized data ownership and architecture, where each makes its data available as an interoperable “data product.”
The key is that the data layer must serve all real-time workloads that are required of the business — both operational and real-time analytical (Figure 6).
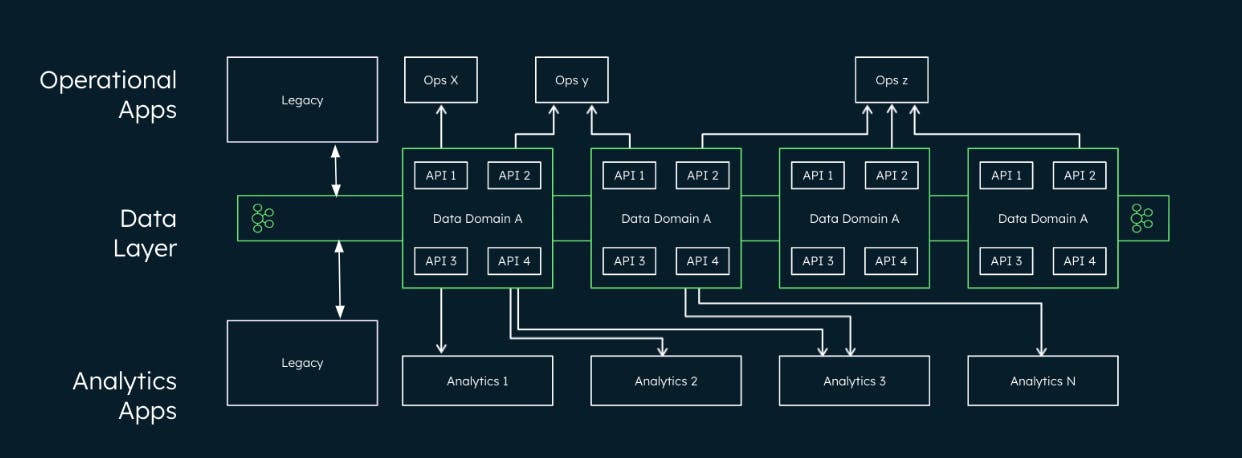
Why use MongoDB for omnichannel data mesh
Let’s look at data layer requirements needed for a data mesh move to be successful and how MongoDB can meet those requirements.
Capable of handling all operational workloads:
Expressive query language, including joining data, ACID transactions, and IoT collections make it great for multiple workloads.
MongoDB is known for its performance and speed. The ability to use secondary indexes means that several workloads can run performantly.
Search is key for retail applications — MongoDB Atlas has Lucene search engine built-in for full-text search with no data movement.
Omnichannel experiences often involve mobile interaction. MongoDB Realm and Flexible Device Sync can seamlessly ensure consistency between mobile and backend.
Capable of handling analytical workloads:
MongoDB’s distributed architecture means analytical workloads can run on a real-time data set, without ETL or additional technology and without disturbing operational workloads.
For real-time analytical use cases, the aggregation framework can be used to perform powerful data transformations and run ad hoc exploratory queries.
For business intelligence or reporting workloads, data can be queried by Atlas SQL or piped through the BI Connector to other data tools (e.g., Tableau and PowerBI).
Capable of serving data as a product:
When serving data as a product, it is often by API: MongoDB’s BSON-based document model maps well to JSON-based API payloads for speed and ease. MongoDB Atlas provides a fully hosted HTTPS Endpoints service.
Depending on the performance needed, direct access may also be required. MongoDB has drivers for all common programming languages, meaning that other teams using different languages can easily interact with it. Rules for access of course must be defined, and one option is to use MongoDB App Services.
Real-time data can also be published to Apache Kafka topics using the MongoDB Kafka Connector, which can act as a sync and a source for data. For example, one bounded context could publish data in real-time to a named Kafka topic, allowing another context to consume this and store it locally to serve latency-sensitive use cases. The tunable schema allows for flexibility in non-product fields, while schema validation capabilities enforce specific fields and data types in a collection to provide consistent datasets.
Resilient, secure, and scalable:
MongoDB Atlas has a 99.995% uptime guarantee and provides auto-healing capability, with multi-region and multi-cloud resiliency options.
MongoDB provides the ability to scale up or down to meet your application requirements — vertically and horizontally.
MongoDB follows a best-in-class security protocol.
Choose the flexible data mesh approach
Providing customers with omnichannel experiences isn’t easy, especially with legacy siloed data architectures. Omnichannel requires a way of making your data work easily across the organization in real-time, giving access to data to those who need it while also giving the power to innovate to the domain experts in each field. A data mesh approach provides the capability and flexibility to continuously innovate.
Thank you to Ainhoa Múgica and Karolina Ruiz Rogelj for their contributions to this post.
Ready to build deeper business insights with in-app analytics and real-time business visibility? Read our new white paper: Application-Driven Analytics: In-App and Real-Time Insights for Retailers.