Which came first, the database or the data? When you are starting with a new cluster on MongoDB Atlas, the database is just a couple of clicks to create, but unless you already have data you can upload, that database can sit empty until you learn how to import data or build an application to fill it. We know this happens often to people who create MongoDB Atlas M0 "free tier" clusters so we looked for a way to help people learn faster.
What we came up with was the new “Load Sample Data” feature. It has just been added to Atlas and enables you to quickly load six datasets into your database instance ready for you to explore. In all, there’s 350MB of data, ready for you to index, query or aggregate using any of MongoDB’s tools such as MongoDB Charts or MongoDB Compass. It’s all there to help you master the power of MongoDB.
On creating a new cluster you may be invited to automatically load sample data into your database. If not, then the “Load Sample Data” button can be found on the Clusters view of MongoDB Atlas under the ellipsis … button in the information panel.
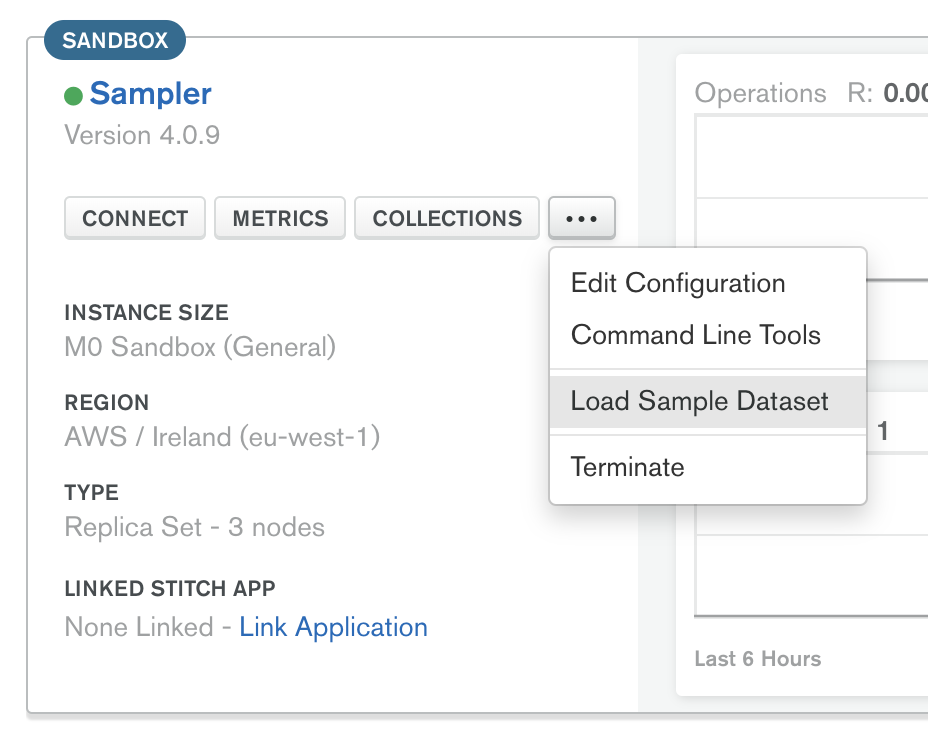
It’ll then ask you if you are sure you want to do that and go off loading the sample data in the background. Give it a few minutes while it loads; if you try and view collections, you’ll see this:

When the loading is done, diving into your collections view will bring up a list for the six databases and their associated collections.
- sample_airbnb has one collection of AirBnB reviews and listings, already indexed by property type, room type, and bed, name and location.
- sample_geospatial is a collection of shipwrecks and their locations, indexed for searching.
- sample_mflix is a database with five collections all about movies, movie theatres and the metadata like users, comments and sessions. Get visualizing that data with a MongoDB Charts tutorial which already uses the mflix dataset.
- sample_supplies is a typical sales data collection from a mock office supplies company. There’s a MongoDB Charts tutorial which shows how to visualize it.
- sample_training is a database with nine collections used in MongoDB’s private training. It’s based on a range of well known data sources such as Openflights, NYC’s OpenData and Twitter’s Decahose.
- sample_weatherdata is another collection loaded with geodata, this time for the locations of weather reports on temperature, wind and visibility.
And don't forget MongoDB Compass Community, your desktop companion for exploring these datasets, is freely available so you can start building aggregation pipelines to turn the mass of data into insightful results. Find out how to install it for your desktop or laptop system in the MongoDB Compass documentation.
With this set of data to hand — and with the tutorials and MongoDB University courses free and ready for you — we hope you'll have an even smoother learning experience with MongoDB.