>> Announcement: Some features mentioned below will be deprecated on Sep. 30, 2025. Learn more.
Two years ago, we released the first iteration of Atlas Data Lake. Since then, we’ve helped customers combine data from various storage layers to feed downstream systems. But after years spent studying our customers’ experiences, we realized we hadn’t gone far enough. To truly unleash the genius in all our developers, we needed to add an economical cloud object storage solution with a rich MQL query experience to the world of Atlas. Today, we’re thrilled to announce that our new Atlas Data Federation and Atlas Data Lake offerings do just that.
We now offer two complementary services, Atlas Data Federation (our existing query service formerly known as Atlas Data Lake) and our new and improved Atlas Data Lake (a fully managed analytic-oriented storage service). Together, these services (both in preview) provide flexible and versatile options for querying and transforming data across storage services, as well as a MongoDB-native analytic storage solution. With these tools, you can query across multiple clusters, move data into self managed cloud object storage for consumption by downstream services, query a workload-isolated inexpensive copy of cluster data, compare your cluster data across different points in time, and much, much more.
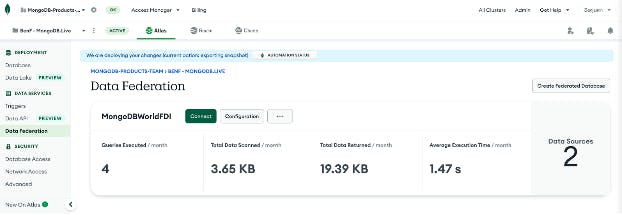
In hearing from our customers about their experiences with Atlas Data Lake, we learned where they have struggled, as well as the features they’ve been looking for us to provide. With this in mind, we decided to shift the name of our current query federation service to Atlas Data Federation to better align with how customers see the service and are getting value. We’ve seen many customers benefit from the flexibility of a federated query engine service, including querying data across multiple clusters, databases, and collections, as well as exporting data to third-party systems.
We also saw where our customers were struggling with data lakes. We heard them ask for a fully managed storage solution so they could achieve all of their analytic goals within Atlas. Specifically, customers wanted scalable storage that would provide high query performance at a low cost. Our new Data Lake provides a high-performance analytic object storage solution, allowing customers to query historical data with no additional formatting or maintenance work needed on their end.
How it works
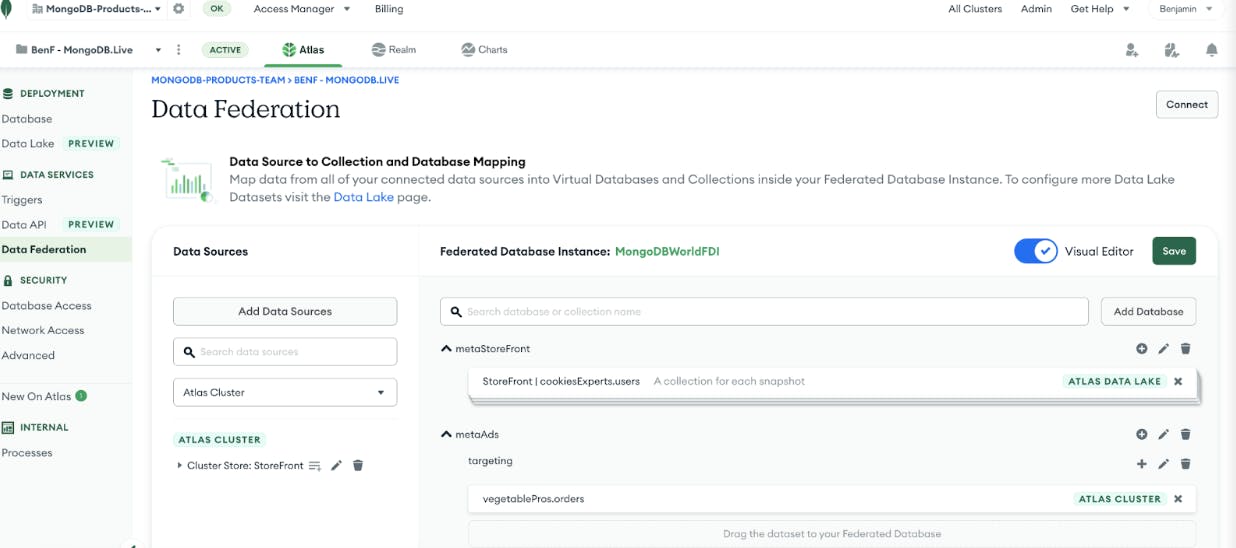
Atlas Data Federation encompasses our existing Data Lake functionality with several new affordances. It continues to deliver the same power that it always has, with increased performance and efficiency. The new Atlas Data Lake will now allow you to create Data Lake pipelines (based on your Atlas Cluster backup schedules) and fields on which you can optimize queries. The service takes the following steps:
On the selected schedule, a copy of your collection will be extracted from your Atlas backup with no impact to your cluster.
During extraction, we build partition indexes based on the contents of your documents and the fields you’ve selected for optimization. These indexes allow your queries to be optimized by capturing the minimums and maximums (and other stats) of the records in each partition, letting you quickly find the relevant data for your queries.
Finally, the underlying data lands in an analytic-oriented format inside of cloud object storage. This minimizes data scanned when you execute a query.
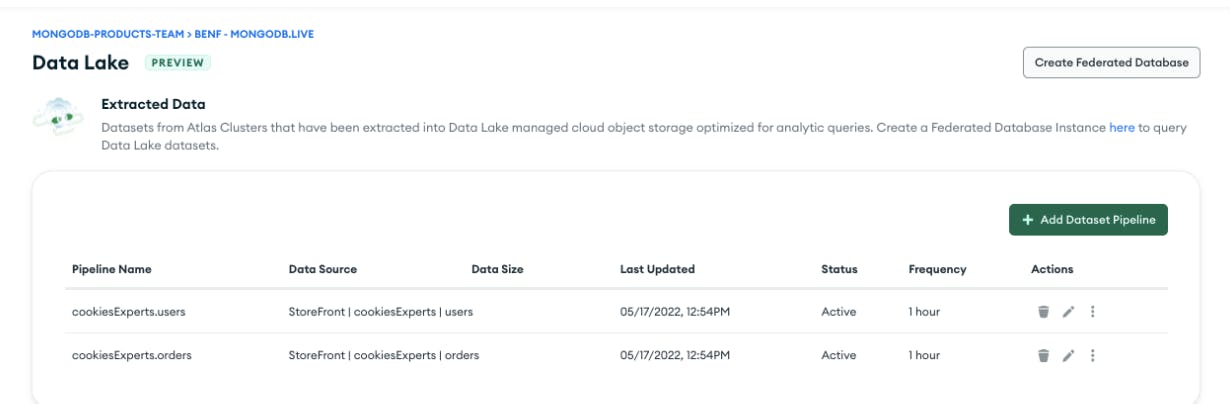
Once a pipeline has run and a Data Lake dataset has been created, you can select it as a data source in our new Data Federation query experience. You can either set it as the source for a specific virtual collection in a Federated Database Instance or you can have your Federated Database Instance generate a collection name for each dataset that your pipeline has created.
Amazingly, no part of this process will consume compute resources from your cluster — neither the export nor the querying of datasets. These datasets provide workload isolation and consistency for long-running analytic queries, a target for ETL jobs using the powerful $out to S3. This makes it easy to compare the state of your data over time.
Advanced though this is, it’s only the beginning of the story. We’re committing to evolving the service, improving performance, adding more sources of data, and building new features. All of this will be based on the feedback you, the user, gives us. We can’t wait to see how you’ll use this powerful new tool and can’t wait to hear what you’d like to see next.