By 2029, the value of the big data analytics market is expected to reach over $655 billion — that is double the value of today's (2023) market value!
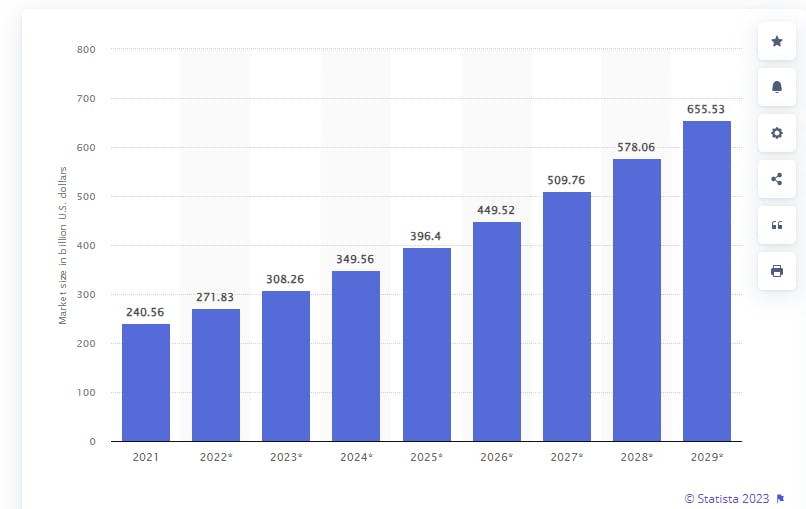 (Source: Statista.com, 2023)
(Source: Statista.com, 2023)
However, in order for organizations to leverage effective big data analytics, they must collect, store, manage, and access vast amounts of structured and unstructured data that far surpass traditional database capacity and architecture. Further, to support the advanced analytics, predictive models, machine learning, and artificial intelligence (AI) processes associated with big data analytics, lightning-fast data processing speeds and operational efficiency are critical.
How can this be accomplished given stockholder demand for greater profits in this inflationary economic climate?
In this big data guide, we'll discuss what big data is, the databases that are able to contain it, its architecture, big data applications, and benefits and challenges, as well as key points executives must consider when leveraging big data to innovate business strategies and fuel profit margins.
Table of contents
What is big data?
In broad terms, big data refers to incredibly large amounts of data (including both structured and unstructured data) that exceeds what traditional data processing software had historically been able to manage through the 1990s and early 2000s (e.g., terabytes vs zettabytes). And even today, with cloud computing, advanced data processing and storage capabilities, and modern resource management to support business users' requirements, big data can still be a heavy lift for many organizations.
The three Vs of big data
Big data has three distinguishing characteristics: volume, velocity, and variety — otherwise known as the "three Vs" of big data.
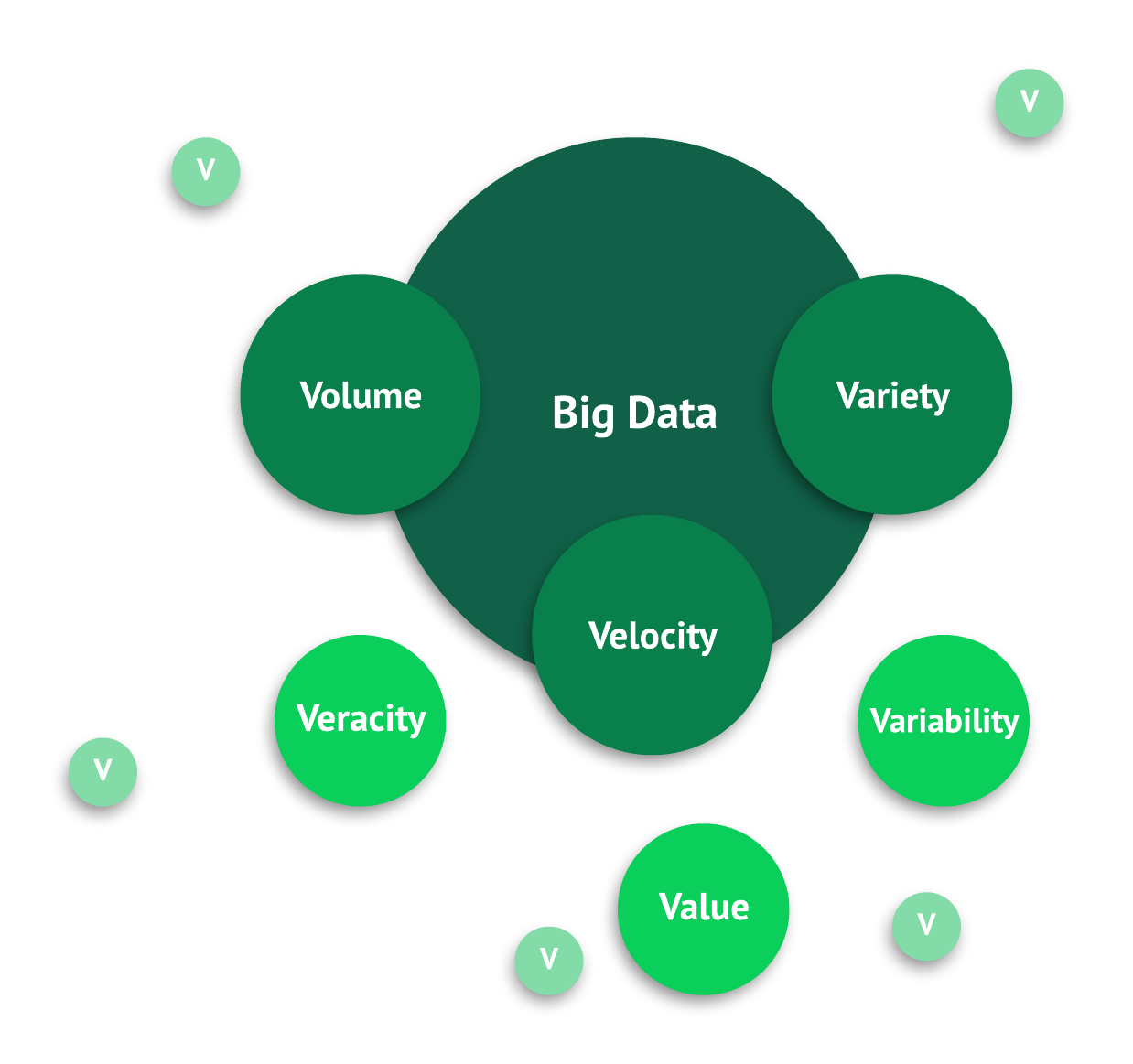
1. Volume
Volume, meaning the amount of data generated, has been increasing exponentially. In fact, it is estimated that 90% of the world's data was generated in the last two years alone! However, that may not be that surprising given that just one cross-country airline trip can generate 240 terabytes of flight data and Internet of Things (IoT) sensors on a single factory shop floor can produce thousands of simultaneous data feeds every day. And, beyond that, just think of all the structured and unstructured data social media generates every second.
2. Velocity
The tremendous volume of big data being generated and collected means data processing has to occur within lightning-fast speed to yield meaningful insights via big data analytics within useful timeframes. In addition, near real-time data processing is required in many aspects of our lives, including:
- Securities trading applications.
- Internet-enabled, multiplayer gaming.
- IoT device streaming.
3. Variety
Big data occupies a variety of formats beyond standard financial or transactional data, including text, audio, video, geospatial, and 3D — none of which can be addressed by highly formatted, traditional relational databases. These older systems were designed for smaller volumes of structured data and to run on just a single server, imposing real limitations on speed and capacity. Modern big data databases, such as MongoDB Atlas, are engineered to readily accommodate multiple data types and wide ranges of enabling infrastructure. This includes scale-out storage architecture and concurrent processing environments.
In addition to the "three Vs," additional "Vs" are becoming more important in describing big data, including:
- Veracity: This term relates to data quality and accuracy which is a key consideration when analyzing data.
- Value: This descriptor refers to the value of the meaningful insights derived from big data.
- Variability: This concept relates not only the different data types within big data, but also the changes in the data types and formats within big data over time.
Types of big data
In the past, much of the data stored in databases and data warehouses was structured data. However, in the era of big data, unstructured data storage needs blossomed. For example, in 2023, 80% to 90% percent of big data is unstructured big data.
To better understand the evolution of big data and big data analytics, it's important to be familiar with the three main types of data: structured data, semi-structured data, and unstructured data.
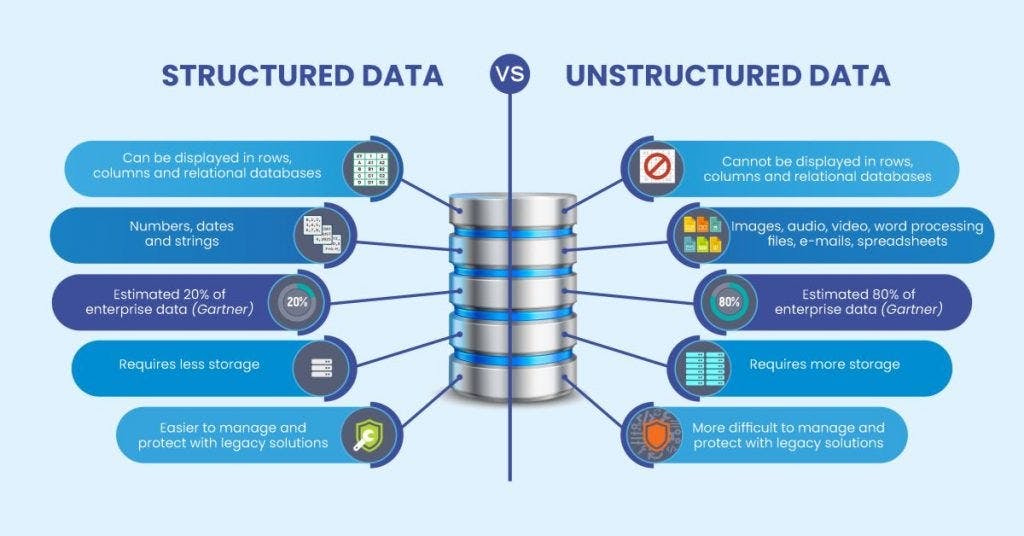 (Source: Medium, 2023)
(Source: Medium, 2023)
Structured data
Structured data is usually composed of alphanumeric characters translated into a predefined format before being fed into a predetermined data model. This data model stores the structured data in cells, rows, and columns. In fact, if you were to picture an Excel spreadsheet with its cells, rows, and columns, this would be very similar to the way structured data is stored at its most basic level. Commonly used structured data includes customer records, financial transactions, inventory records, and retail loyalty program data.
Semi-structured data
Semi-structured data has some level of structure and organization but does not conform to the rigid data schema needed to align with traditional structured data requirements. Key elements of semi-structured data include:
- Schema flexibility: Semi-structured data offers greater flexibility in the data schema. Specifically, this means that, within the same data set, data elements can vary in structure. For example, in JavaScript Object Notation (JSON) documents, one data record may have more or fewer fields than another record. This would not be possible with the strict, predefined schemas of structured data.
- Hierarchical or nested structure: Rather than the strictly row/column format of structured data, semi-structured data is often stored in a hierarchical or nested structure. A good way to visualize this is in the form of a family tree or org chart.
- Data tags and labels: Semi-structured data often contains tags which give additional information about that data (e.g., metadata). For example, eXtensible Markup Language (XML) documents contain metadata that not only creates a data hierarchy, but may also identify keywords associated with the content.
Some common examples of semi-structured data include email, web pages, and zipped files.
Unstructured data
Unstructured data doesn't have consistent structure or schema and can be found in a variety of formats. These formats can include everything from videos, images, and audio files to documents, web logs, sensor data, and binary data. Key hallmarks of unstructured data include:
Natural language: Significant amounts of unstructured data contain natural language text. This means that the text data may include misspellings, abbreviations, grammatical errors, and slang as it isn't standardized before ingestion. For this reason, additional data cleansing and data quality control measures may be required prior to analyzing these data sets which can be a complex process.
Artificial intelligence (AI) query methods: Because unstructured data contains a variety of formats and data structures, more advanced query techniques are required. One of these techniques is called machine learning (ML) which can help data scientists analyze big data and effectively use big data analytics tools. Examples include:
- Natural language processing (NLP): NLP involves the development of algorithms and data models that help machines (e.g., computers, IoT devices) to understand, interpret, and generate human language.
- Text mining: Text mining is an element of NLP where unstructured data text is transformed into normalized, structured data that can then be analyzed or used for additional AI purposes.
- Image and video analysis: ML modeling is used to interpret unstructured visual data, such as images and videos. Everything from facial recognition to medical image diagnostics and summarizing videos is possible.
- Audio analysis: ML algorithms are able to not only conduct voice recognition analysis but also determine the emotional sentiment being expressed by the speaker (e.g., fear, excitement, anger). In addition, ML can pick up and isolate ambient noise in the background of an audio file, identifying potential locations where the audio file was recorded.
- Recommendations: ML models accessing consumer behavioral databases are able to extract potentially unknown consumer preferences and recommend products or services the consumer might enjoy. Common applications include the "You might like" sections in digital streaming services such as Netflix or your favorite eCommerce site suggesting shoes to go with the outfit you are purchasing.
- Social media analytics: Analyzing data which contains such a variety of formats as those found in social media (e.g., video, audio, text, and behavioral data) would have been impossible without AI due to both the sheer amounts of data involved as well as complex data involved. However, with ML statistical algorithms and the sifting of relevant data from the data collected, social media market trends and advanced analytics can now be derived from these vast, diverse data sets.
- Detecting outliers: ML models and algorithms are excellent at identifying divergence from standard patterns and anomalies in unstructured data. These big data analytics processes can analyze everything from sensor logs monitoring geothermal activity collected from a dormant volcano to mundane network logs that demonstrate stealth cybercrime activities.
Common examples of unstructured big data include text documents, text fields in consumer surveys, video files in social media posts, maps, and contracts.
Resources to learn more:
Big data architecture
Big data architecture refers to the design and organization of the hardware and software used to ingest, process, store, analyze, monitor, and back up extremely large and complex datasets. Big data architecture varies with traditional data architecture not only in terms of the volume of data it can process and store, but also in its arrangement. Big data architecture often uses a distributed database system architecture, meaning the database is run and stored across multiple machines and sites, while traditional databases tend to be centralized. In addition, big data architecture tends to focus on the storage and processing of data greater than 100 gigabytes in size and is often used to capture, process, and analyze streaming data in real-time or near real-time.
Resource to learn more: What is a distributed database
Layers of big data architecture
While big data architecture can vary depending on organizational needs and budgets, there are several common layers and components that most big data architectures contain.
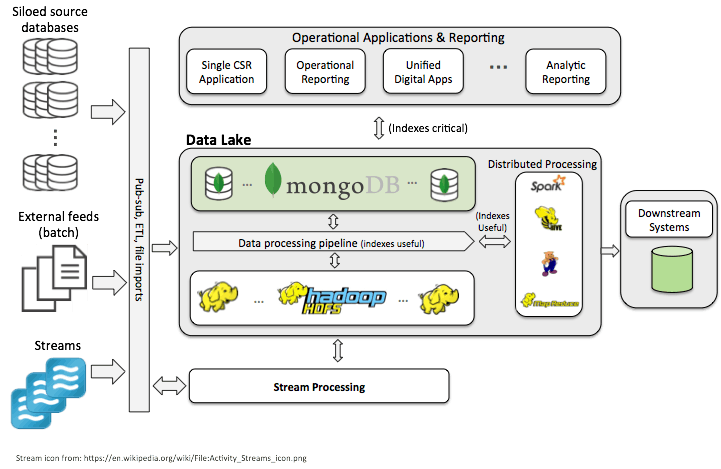
Data sources
Data is sourced from multiple inputs in a variety of formats. Examples include structured data from financial systems and retail databases; semi-structured data from email systems, web logs, and XML/JSON files; and unstructured data from such sources as social media, facial recognition systems, sensors, scanned documents, and real-time streaming data inputs, such as those received from Internet of Things (IoT) devices.
Data collection and ingestion
This is the layer that collects and receives data from diverse data sources. And, as much of the data used in big data is unstructured, big data architecture must be able to accommodate the ingestion of varying data types with varying formats. For this reason, while there are usually some types of data validation in place, data format and data schema requirements are more lax than the hardline ones common in traditional relational databases.
There are two general types of data ingestion — batch and real-time. Batch ingestion is usually a regularly scheduled event to bring new data into the database periodically. Real-time ingestion, required for real-time message ingestion and streaming data, occurs on a continuous basis. While captured in real-time, it is sometimes necessary to hold this data briefly (seconds) for buffering to enable scale-out processing and reliable output delivery.
Data storage
The data storage layer takes the ingested data and stores it in an efficient manner optimized for scalability and performance. Organizational data storage solutions are driven by anticipated data volume, data types, access patterns, and anticipated query requirements.
Data processing
This layer is responsible for filtering, combining, and rendering data into a usable state for further analysis. And, just as with ingestion, processing may occur via a batch or streaming process.
Source files are read and processed, with the output written to new files. These files often include distributed file systems, meaning files are stored on multiple machines in multiple locations. At this point, the output data may be formatted and relayed to a relational data warehouse where it can be queried via traditional business intelligence (BI) tools, or it may be served to NoSQL databases and interactive technologies that specialize in analytics of a variety of unstructured data.
One outlier in this process is the data lake. Data lakes are able store vast amounts of data in its original (raw data) format. This means that data ingestion into a data lake is possible without any type of preformatting required. In addition, data lakes are able to store both structured and unstructured data.
Data analytics
Big data analytics is a broad term relating to this layer. Not only are traditional, search-based, and predictive analytics conducted, but ad-hoc analysis is performed as well. In addition, stream analytics tools (e.g., analysis of vast pools of real-time data through the use of continuous queries) are employed to provide social media analytics and associated consumer data behavior trends.
Further, data science professionals often employ machine learning (ML) to create data models which enable self-service BI dashboards for business users. ML is also employed by data scientists to further explore raw and unstructured data sets through data mining and other advanced analytics practices.
Resources to learn more: Unstructured data analytics tools
Data visualization
Data visualization is the representation of data through graphic means. Data visualization tools and reporting platforms allow users to transform complex data insights into easily understandable graphic representations for business users and stakeholders. Tools such as Tableau, Power BI, and custom dashboards enable this data visualization, exploration, and reporting.
Data security and monitoring
In this layer, security protocols such as access control, user authentication, and encryption are in place to protect data resources. This layer also contains the software necessary to continuously monitor systems for cyberattacks and associated malware or viruses. In addition, data governance operations ensuring compliance with third-party regulations and access (e.g., government, industry standards entities) also reside here.
Finally, the health and performance of the big data architecture is monitored here. This includes logging, backups, system alerts, and the application of management tools to ensure high levels of system availability, access, and data quality.
Big data benefits and challenges of big data architecture
As with any type of data system, there are both benefits and challenges with big data. Summarized below are the top benefits of big data and its challenges.
Benefits of big data architecture
Parallel computing: To process large data sets quickly, big data architectures use parallel computing, in which multiprocessor servers perform numerous calculations at the same time. Sizable problems are broken up into smaller units which can be solved simultaneously.
Elastic scalability: Big data architectures can be scaled horizontally, enabling the environment to be adjusted to the size of each workload. Big data solutions are usually run in the cloud, where you only pay for the storage and computing resources you actually use.
Freedom of choice: The marketplace offers many solutions and platforms for use in big data architectures, such as Azure managed services, MongoDB Atlas, and Apache technologies. You can combine solutions to get the best fit for your various workloads, existing systems, and IT skill sets.
Interoperability: You can create integrated platforms across different types of workloads, leveraging big data architecture components for IoT processing and BI as well as analytics workflows.
Challenges with big data
Security: Big data of the static variety is usually stored in a centralized data lake. Robust security is required to ensure your data stays protected from intrusion and theft. But secure access can be difficult to set up, as other applications need to consume the data as well.
Complexity: A big data architecture typically contains many interlocking moving parts. These include multiple data sources with separate data-ingestion components and numerous cross-component configuration settings to optimize performance. Building, testing, and troubleshooting big data processes are challenges that take high levels of knowledge and skill.
Evolving technologies: It’s important to choose the right solutions and components to meet the business objectives of your big data initiatives. This can be daunting, as many big data technologies, practices, and standards are relatively new and still in a process of evolution. Core Hadoop components such as Hive and Pig have attained a level of stability, but other technologies and services remain immature and are likely to change over time.
Specialized skill sets: Big data APIs built on mainstream languages are gradually coming into use. Nevertheless, big data architectures and solutions do generally employ atypical, highly specialized languages and frameworks that impose a considerable learning curve for developers and data analysts alike.
Applications of big data
Clearly, there is an ever-expanding range of big data applications given the increasing rate of daily data generation and organizational reliance upon actionable data insights across most industries, governmental agencies, educational institutions, healthcare, and non-profit organizations. Below is a summary of a few of the key organizational functions fueled by big data.
Productivity and cost optimization: To hone their edge in low-margin competitive markets, manufacturers utilize big data to improve quality and output while minimizing scrap. Government agencies can employ social media to identify and monitor outbreaks of infectious diseases. Retailers routinely fine-tune campaigns, inventory SKUs, and price points by monitoring web click rates that reveal otherwise hidden changes in consumer behavior.
Product development: Companies analyze and model a range of big data inputs to forecast customer demand and make predictions as to what kinds of new products and product features will be most valuable to users.
Smart technologies: Big data plays a crucial role in collecting and analyzing data from sensors, cameras, and IoT devices used every day. Whether it be for an individual's smart home system (e.g., Ring, Alexa, Blink) or smart cities for security (e.g., CCTV), traffic management, or urban planning, this technology is only just beginning in its applications to our lives.
Predictive maintenance: Using sophisticated algorithms, manufacturers assess IoT sensor inputs and other large datasets to track machine performance and uncover clues that hint at imminent technical issues. The goal is to determine the ideal intervals for preventive maintenance, optimizing equipment operation and maximize uptime while avoiding unnecessary costs.
Compliance: The ability to parse through large quantities of information much faster, speeding up and simplifying regulatory reporting, is a key benefit of big data usage in compliance. In addition, given the ability of distributed database systems to provide real-time access to governmental or industry standards regulatory agencies, fulfilling compliance requirements and audits are fast-tracked.
Cybersecurity: Big data is used for real-time threat detection, log analysis, and network monitoring. Anomalies in user access, levels of resource usage related to role-based credentials, and data usage patterns are just a few of the ways AI uses big data to safeguard organizational data assets.
Big data usage examples
Big data technologies are able to identify patterns and correlations hidden in massive collections of data. Revealed by powerful big data analytics, these technologies inform planning and decision making across most industries on a global scale. In fact, just within just the last decade, big data usage has grown to the point where it touches nearly every aspect of our work, home lives, shopping habits, and recreation.
Here are some examples of big data applications that affect people every day.
Transportation
Big data powers the GPS smartphone applications most of us depend on to get from place to place in the least amount of time. These GPS systems rely on satellite images, law enforcement and civil updates, real-time traffic data from camera systems, and even crowd-sourced information (e.g., Waze).
Airplanes also generate enormous volumes of data (e.g., 1,000 gigabytes for transatlantic flights). Aviation analytics systems ingest all of this data for every flight in the air to analyze fuel efficiency, passenger and cargo weights, and weather conditions, to optimize passenger safety and energy consumption.
Advertising and marketing
In the past, marketers employed TV and radio preferences, survey responses, and focus groups to better target ad campaigns. However, these efforts were far from precise.
Today, advertisers use huge quantities of data to identify specific consumer targets for their products and services by determining what consumers actually click on, search for, and “like.” Marketing campaigns are also monitored for effectiveness using click-through rates, views, and other precise metrics.
Banking and financial services
The financial industry uses big data for crucial activities such as:
Fraud detection: Banks monitor credit cardholders’ purchasing patterns and other activity to flag anomalies that may signal fraudulent transactions.
Risk management: Big data analytics enable banks to monitor and report on operational processes, KPIs, and employee activities which may incur organizational liability or data security risks.
Customer relationship optimization: Financial institutions analyze website usage and transactional data to better convert prospects to customers, as well as incentivize greater use of their financial products by existing customers.
Government
Government agencies collect voluminous quantities of data, but many don’t employ modern data mining and analytics techniques to extract real value from it. However, some government agencies do employ modern AI and analyze big data effectively. A few examples include:
Internal Revenue Service (IRS): The IRS uses big data analytics to identify tax fraud and money laundering.
Federal Bureau of Investigation (FBI): The FBI employs big data strategies to monitor large purchases of potential bomb-making materials (e.g., commercial fertilizers), the social media activities of domestic terrorist groups, and dark websites used in human trafficking.
Central Intelligence Agency (CIA): Among the many big-data-centric activities of the CIA are the active monitoring of audio, video, images, and text files collected by field assets in order to deter international terrorism, hostile-state cyberattacks, and more.
Meteorology
Weather satellites and sensors all over the world collect large amounts of semi-structured and unstructured data to track environmental conditions. Meteorologists use big data to:
- Study natural disaster patterns.
- Prepare weather forecasts.
- Understand the impact of global warming.
- Predict the availability of drinking water in various world regions.
- Provide early warning of impending crises such as hurricanes and tsunamis.
Healthcare
Big data is making a major impact in the huge healthcare industry. Wearable devices and sensors collect real-time patient data which is served to healthcare providers and charted into electronic health records. This wearable tech helps those in remote regions to see healthcare specialists when none are available locally, as well as to expedite treatment when abnormal test results are detected.
In addition, through the use of AI, more accurate reviews of images (e.g., mammograms, MRIs) are able to detect health issues far earlier than those reviewed by the human eye alone.
Education
Through the use of AI and machine learning, teachers are able to quickly review student results via dashboards which highlight students who are falling behind or are exhibiting behaviors known to precede dropping out. This allows educators to target specific students with the right resources at the right time to enhance successful outcomes.
Big data considerations
When contemplating next steps in your organization's big data journey, be sure to think about the following big data considerations.
Managing accelerated data volume growth
Data quantities continue to expand, much of it in unstructured data formats such as audio, video, social media, photos, and IoT-device inputs. These can be difficult to search and analyze, requiring sophisticated technologies like AI and machine learning.
For storage and management, companies are making increasing use of NoSQL databases such as MongoDB and MongoDB Atlas, its database-as-a-service (DBaaS) version, which runs on all of the three most popular cloud services and can be moved among them with no changes required. MongoDB is a preferred big data option thanks to its ability to easily handle a wide variety of data formats, support for real-time analysis, high-speed data ingestion, low-latency performance, flexible data model, easy horizontal scale-out, and powerful query language. Other helpful technologies are Spark, business intelligence (BI) applications, and the Hadoop distributed computing system for batch analytics.
Integrating data from dissimilar sources
Big data comes in diverse formats, originating from a multitude of sources including:
- Website logs.
- Call centers.
- Enterprise apps.
- Social media streams.
- Email systems.
- Webinars.
Ingesting all this data into a single repository and transforming it into a usable format for analysis tools is a complex process. Any company that is serious about mining the potential of big data needs to make correspondingly serious investments in extract, transform, load (ETL) technology and data integration tools. Consider how your organization will approach ETL and integration, both from an operational and functional standpoint, as well as an institutional knowledge perspective before finalizing next steps in your big data journey.
Uncovering insights rapidly
Unearthing actionable insights for better decision making is the key driver for big data analytics. Some of the benefits include:
- Boosting operational efficiencies that can lower expenses.
- Reducing time to market for innovative product features.
- Identifying promising new market segments.
- Guiding the development of new products and services.
- Creating a culture of evidence-based decision making.
Achieving these goals depends on ingesting as much data as possible and uncovering insights quickly. For those organizations just beginning their journey, or undergoing rapid expansion, it may make sense to consider alternatives to internally built and managed big data environments. Cloud computing service providers are a way for organizations to leap-frog ahead into the benefits of big data without the significant outlay of resources needed to develop internally.
Examples include:
Infrastructure as a service (IaaS): Storage, servers, virtualization, and networking services can be provided by third parties, quickly moving big data projects forward.
Platform as a service (PaaS): In PaaS, a cloud-based platform is provided by a third party to deploy and manage big data applications. Including all the features of IaaS, PaaS also includes operating systems and middleware, leaving organizations responsible only for the application and the data.
Software as a service (SaaS): SaaS is the most commonly used of the cloud technology stack. It provides all the features of IaaS and PaaS as well as the management of applications and data. Organizational users then just access the big data user interface as required.
Learn more about the cloud computing stack.
Big data security
Security challenges are as diverse as the sources of big data. As a result, there are some cybersecurity considerations relating to big data.
Cybersecurity strategy: With its large quantity of valuable, confidential information, big data environments are especially attractive for hackers and cybercriminals. With that in mind, it's important to build in cybersecurity at an early stage of architecture planning that touches all aspects of the big data system as comprehensive protection is extremely difficult and expensive when organizations try to “bolt it on” to an existing system at a later date.
Multisource data ingestion: While traditional databases may have multiple data sources to ingest, big data may have hundreds or even thousands. However, it's still important to carry out thorough vetting and cybersecurity protocols on each one. This can be daunting for organizations to tackle on their own so it's important to consider internal resources and skill sets as you progress on your organizations big data journey. Alternatively, outsourcing this function to a third party is a viable option that many organizations choose, paying on a subscription service model.
Big data governance
Governance is about validating data: making sure records reconcile and that they are usable, accurate, and secure. However, the integration of multiple sources can make this process complex, and reconciling data from different systems that should agree is a necessary but potentially difficult task. For example, sales figures from a company’s CRM (customer relationship management) system may be different than those recorded on their eCommerce platform, or a hospital may have differing addresses for a patient in different systems.
Typically, organizations form an internal group tasked with writing governance policies and procedures. They also invest in data management tools with the advanced big data technology required for data cleansing, integration, quality assurance, and integrity management. For this reason, it's important to consider where your organization is in its big data journey and how aligned its data governance process is with best practices for your industry.
FAQs
What is big data?
Big data refers to incredibly large amounts of data (including both structured and unstructured data) that exceeds what traditional data processing software had historically been able to manage through the 1990s and early 2000s (e.g., terabytes vs zettabytes).
What are the "three Vs" of big data?
Volume: This refers to the amount of data being collected.
Velocity: This refers to the speed at which the data is ingested into the system, as well as the speed at which the data changes/updates over time.
Variety: This refers to the various formats the data takes, as well as the different data sources ingested.
What are the different types of big data?
Structured data: Structured data is usually composed of alphanumeric characters translated into a predefined format before being fed into a predetermined data model.
Semi-structured data: Semi-structured data has some level of structure and organization but does not conform to the rigid data schema needed to align with traditional structured data requirements.
Unstructured data: Unstructured data doesn't have consistent structure or schema and can be found in a variety of formats. These formats can include everything from videos, images, and audio files to documents, web logs, sensor data, and binary data.
What are the architecture layers in big data?
- Data sources
- Data collection and ingestion
- Data storage
- Data processing
- Data analytics
- Data visualization
- Data security and monitoring
What are the benefits of big data?
- Parallel computing
- Elastic scalability
- Freedom of choice
- Interoperability
What are the challenges with big data?
- Security
- Complexity
- Evolving technologies
- Specialized skill sets