Docs Home → Launch & Manage MongoDB → MongoDB Atlas
Atlas Data Federation Overview
On this page
About Atlas Data Federation
Atlas Data Federation is a distributed query engine that allows you to natively query, transform, and move data across various sources inside & outside of MongoDB Atlas.
Key Concepts
Federated Database InstanceA federated database instance is a deployment of Atlas Data Federation. Each federated database instance contains virtual databases and collections that map to data in your data stores.
Data StoreData store refers to the location of your data. Atlas Data Federation supports the following data stores:
Atlas cluster
Atlas online archive
Atlas Data Lake datasets
AWS S3 buckets
Azure Blob Storage
HTTP and HTTPS endpoints
Storage ConfigurationStorage configuration contains mappings between your virtual databases and collections and data sources in JSON format. You can define these mappings in the storage configuration to access and run queries against your data.
Atlas Data Federation Architecture

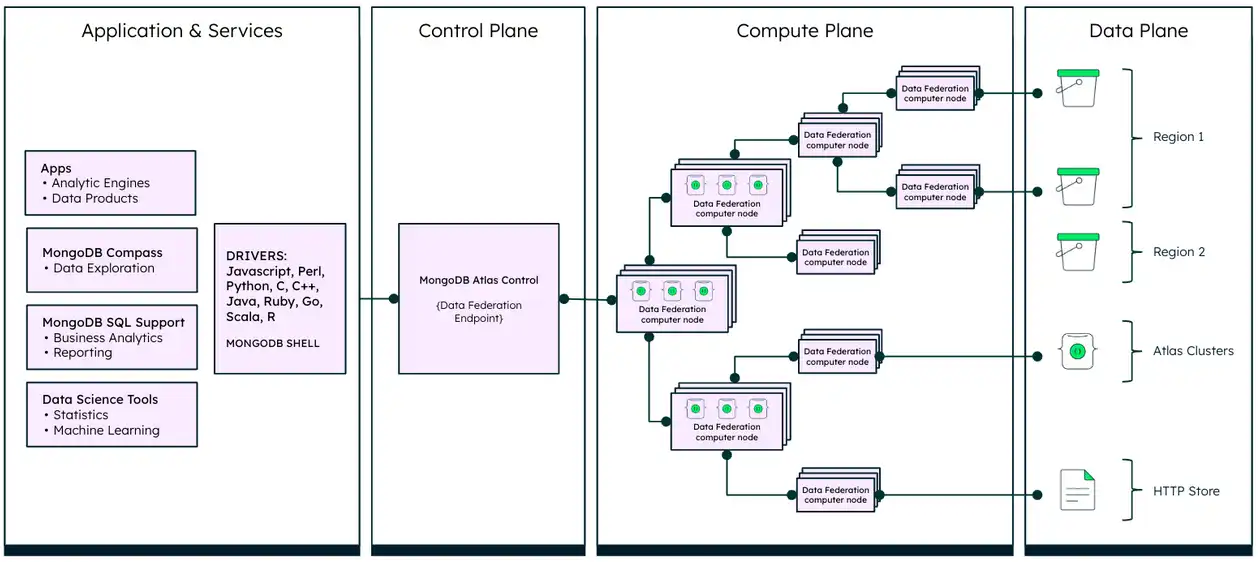
The Data Plane in the preceding diagram is where your data resides. You can configure Atlas Data Federation to access data in a variety of storage services. Specifically, you can configure Atlas Data Federation to access data in your AWS S3 buckets across AWS regions, Azure Blob Storage containers, Atlas clusters, HTTP and HTTPS URLs, Atlas Online Archives, and Atlas Data Lake datasets. To learn more about configuring Atlas Data Federation to access your data stores, see Define Data Stores for a Federated Database Instance.
You can then set up role-based access control for your federated database instances. You can control how your client connects to your federated database instance, either through a global connection option or by pinning it to a specific region. To learn more, see Configure Connection for Your Federated Database Instance.
Atlas Data Federation preserves data locality and maximizes local computation, where possible, to minimize data transfer and optimize performance. The Compute Plane in the preceding diagram shows where Atlas Data Federation processes all requests. Atlas Data Federation provides an elastic pool of agents in the region that is nearest to your data where Atlas Data Federation can process the data for your queries. To learn more about supported regions, see Atlas Data Federation Regions.
Atlas Data Federation doesn't persist data inside the system and once your query is processed, it only stores the metadata in your federated database instance. This allows you to comply with data sovereignty regulations and ensures that your data is stored and processed in compliance with legal requirements.
The Control Plane in the preceding diagram, which is the same as the Atlas Control Plane, is where Atlas Data Federation balances user requests and aggregates final results.
Atlas Data Federation executes certain parts of a query directly on the underlying storage service, rather than transfer all of the data to the compute nodes for processing. Additionally, when you execute a query, it is first processed by a Data Federation front-end component, which plans the query and then distributes it to the nodes in the backend. The backend nodes then access your data store directly to execute the query logic and return the results back to the front-end. This process reduces the amount of data to move around, thereby making the whole process faster and cheaper. To learn more, see Query a Federated Database Instance.
To optimize the performance of your queries, Atlas Data Federation does the following:
For Cloud Object Storage, it uses data partitioning to select the files that it needs to process based on query parameters. To learn more, see Define Path for S3 Data and Use Partition Attribute Types. Additionally, it uses Parquet metadata to reduce the amount of data it scans from parquet files using row group selection or column projection. To learn more, see Parquet Data Format.
For Atlas clusters, it tries to "push down" as much of the query to the cluster as possible. For example, if your aggregation pipeline has a
$matchstage and if it can be processed locally, Atlas Data Federation tries to process that stage in the Atlas cluster and only returns the resulting documents back to the federated layer for processing subsequent stages. To learn more, see Querying Data in Your Atlas Cluster.For Atlas Data Lake datasets, it uses partition indexes to speed up queries against datasets. Atlas Data Lake partition indexes contain counts that it returns, rather than scan the underlying file storage to satisfy queries. To learn more, see Atlas Data Lake Dataset or Online Archive.
To learn more, see Optimize Query Performance.
You can connect to Atlas Data Federation using MongoDB language-specific
drivers, mongosh, and Atlas SQL. To learn more, see Connect to Your Federated Database Instance.
Sample Uses
You can use Atlas Data Federation to:
Copy Atlas cluster data into Parquet or CSV files written to AWS S3 buckets.
Query across multiple Atlas clusters and online archives to get a holistic view of your Atlas data.
Materialize data from aggregations across Atlas clusters and AWS S3 buckets.
Read and import data from your AWS S3 buckets into an Atlas cluster.
Atlas Data Federation Regions
Note
To prevent excessive charges on your bill, create your Atlas Data Federation in the same AWS or Azure region as your S3 or Azure Blob Storage data source. You can query AWS S3 only using federated database instances created in AWS and you can query Azure Blob Storage only using federated database instances created in Azure.
Atlas Data Federation routes your federated database requests through one of the following regions:
Note
You will incur charges when running federated queries. For more information, see Data Federation Costs.