Docs Home → Atlas App Services
Partition-Based Sync
On this page
- Overview
- Key Terms
- Partition
- Partition Key
- Change a Partition Key
- Partition Value
- Enable Partition-Based Sync
- Before You Begin
- Procedure
- Navigate to the Sync Configuration Screen
- Select Development Details
- Choose a Partition Key
- Define Read & Write Permissions
- Check Default Advanced Configuration Behaviors
- Turn On Sync
- Authenticate a MongoDB Atlas User
- Pull the Latest Version of Your App
- Add a Sync Configuration
- Choose a Partition Key
- Define Read & Write Permissions
- Specify Values for Sync Optimization
- Deploy the Sync Configuration
- Select a Cluster to Sync
- Choose a Partition Key
- Define Read & Write Permissions
- Specify Values for Sync Optimization
- Deploy the Sync Configuration
- Partition-Based Rules and Permissions
- Partition-Based Sync Rule Behavior
- Partition-Based Sync Permissions
- Key Concepts
- Read Permissions
- Write Permissions
- Permission Strategies
- Global Permissions
- Permissions for Specific Partitions
- Permissions for Specific Users
- Permissions Based on User Data
- Function Rules
- Migrate Partition-Based Sync Rules to App Services Rules
- Partition Strategies
- Firehose Strategy
- User Strategy
- Team Strategy
- Channel Strategy
- Region Strategy
- Bucket Strategy
- Data Ingest
- Partition-Based Sync Configuration
- Alter Your Partition-Based Sync Configuration
- Partition-Based Sync Errors
- Backend Compaction
Overview
Atlas Device Sync has two sync modes: Flexible Sync and the older Partition-Based Sync. We recommend using Flexible Sync for all new apps. The information on this page is for users who are still using Partition-Based Sync.
In Partition-Based Sync, documents in a synced cluster form a "partition" by having the same value for a field designated as "partition key". All documents in a partition have the same read/write permissions for a given user.
In Partition-Based Sync, you define a partition key whose value determines
whether the user can read or write a document. App Services evaluates a set of
rules to determine whether users can read or write to a given partition. App
Services directly maps a partition to individual synced .realm files. Each
object in a synced realm has a corresponding document in the partition.
Example
Consider an inventory management application using Partition-Based Sync. If
you use store_number as the partition key, each store can read and write
documents pertaining to its inventory.
An example of the permissions for this type of app might be:
{ "%%partition": "Store 42" }
Store employees could have read and write access to documents whose store number is Store 42.
Customers, meanwhile, could have read-only access to store inventory.
In the client, you pass a value for the partition key when opening a synced realm. App Services then syncs objects whose partition key value matches the value passed in from the client application.
Example
Based on the store inventory example above, the SDK might pass in
store42 as the partitionValue in the sync configuration.
This would sync any InventoryItem whose partitionValue was
store42.
You can use custom user data to indicate
whether a logged-in user is a store employee or a customer. Store
employees would have read and write permission for the store42
data set, while customers would have only read permission for the
same data set.
const config = { schema: [InventoryItem], // predefined schema sync: { user: app.currentUser, // already logged in user partitionValue: "store42", }, }; try { const realm = await Realm.open(config); realm.close(); } catch (err) { console.error("failed to open realm", err.message); }
Device Sync requires MongoDB Atlas clusters to run specific versions of MongoDB. Partition-Based Sync requires MongoDB 4.4.0 or greater.
Key Terms
Partition
A partition is a collection of objects that share the same partition key value.
A MongoDB Atlas cluster consists of several remote servers. These servers provide the storage for your synced data. The Atlas cluster stores documents in collections. Each MongoDB collection maps to a different Realm object type. Each document in a collection represents a specific Realm object.
A synced realm is a local file on a device. A synced realm may contain some or all the objects relevant to the end user. A client app may use more than one synced realm to access all the objects that the application needs.
Partitions link objects in Realm Database to documents in MongoDB. When you initialize a synced realm file, one of its parameters is a partition value. Your client app creates objects in the synced realm. When those objects sync, the partition value becomes a field in the MongoDB documents. The value of this field determines which MongoDB documents the client can access.
At a high level:
A partition maps to a subset of the documents in a synced cluster.
All documents in a partition have the same read/write permissions for a given user.
Atlas App Services maps each partition to an individual synced
.realmfile.Each object in a synced realm has a corresponding document in the partition.

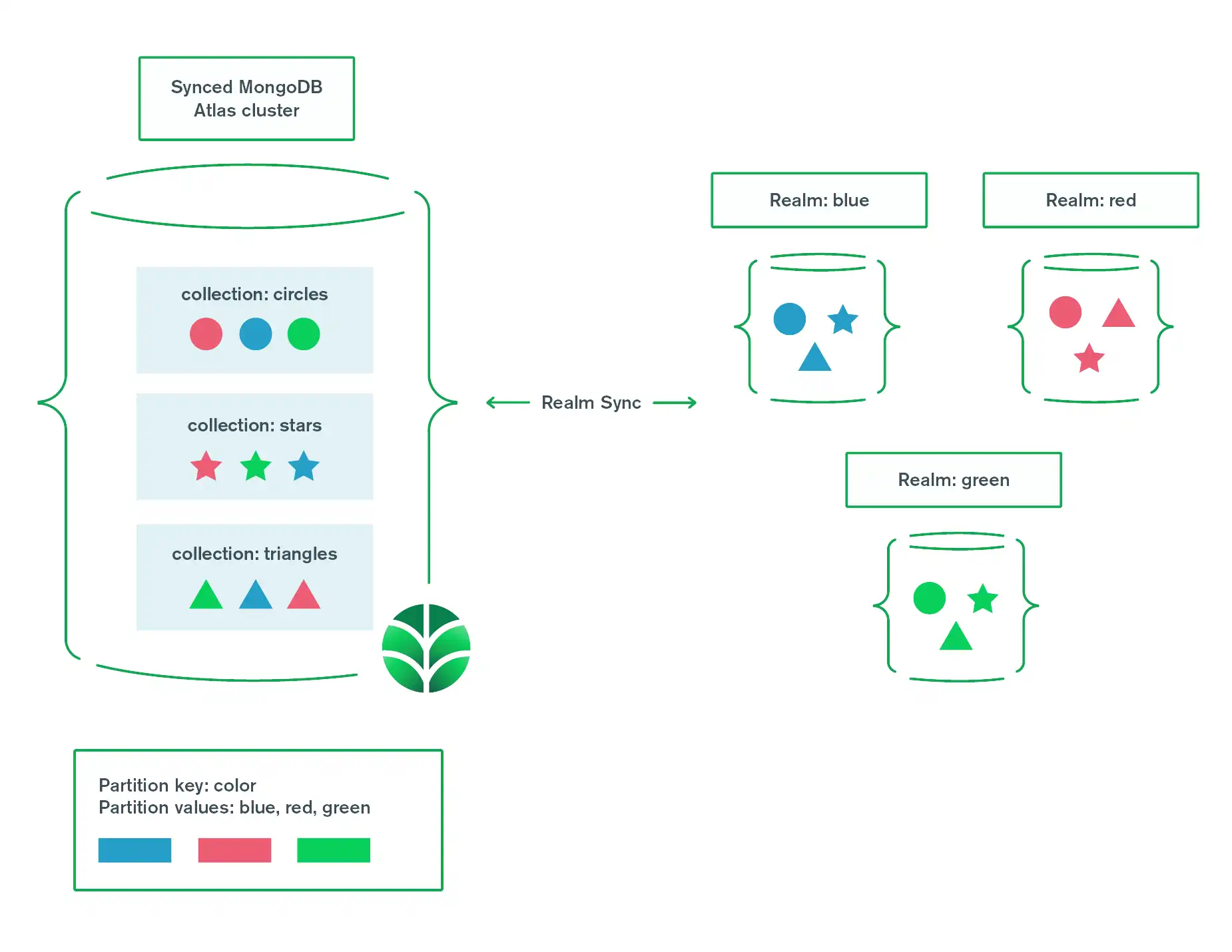
Partitions shape data in an Atlas cluster. Each shape represents an object type.
Partitions are determined by each shape's color: red, green, or blue.
Partition Key
A partition key is a named field that you specify when you configure Atlas Device Sync. Device Sync uses this key to determine which partition contains a given document.
Depending on your data model and the complexity of your app, your partition key could be either:
A property that already exists in each document and that logically partitions data. For example, consider an app where every document is private to a specific user. You might store the user's ID value in an
owner_idfield and then use that as the partition key.A synthetic property that you create to partition data (e.g.
_partition). You might use this when your app does not include a natural partition key.
You can make the partition key required or optional on your objects. App Services maps any object that does not include a partition key to a default partition - null partition.
Consider the following when choosing a partition key:
Partition keys must be one of these types:
String,ObjectID,Long, orUUID.App Services clients should never modify the partition value directly. You cannot use any field that clients can modify as a partition key.
Partition keys use the same field name in every synced document. The partition key should not collide with any field name in any object's model.
Example
The following schemas demonstrate natural and synthetic partition keys:
The
owner_idfield is a natural key because it's already part of the app's data model.The
_partitionfield is a synthetic key because its only purpose is to serve as a partition key.
An app can only specify a single partition key, but either of these fields could work depending on your use case:
{ "title": "note", "bsonType": "object", "required": [ "_id", "_partition", "owner_id", "text" ], "properties": { "_id": { "bsonType": "objectId" }, "_partition": { "bsonType": "string" }, "owner_id": { "bsonType": "string" }, "text": { "bsonType": "string" } } } { "title": "notebook", "bsonType": "object", "required": [ "_id", "_partition", "owner_id", "notes" ], "properties": { "_id": { "bsonType": "objectId" }, "_partition": { "bsonType": "string" }, "owner_id": { "bsonType": "string" }, "notes": { "bsonType": "array", "items": { "bsonType": "objectId" } } } }
Change a Partition Key
Your app's partition key is a central part of a Sync-enabled app's data model. When you set a partition key in your Sync configuration, you cannot later reassign the key's field. If you need to change a partition key, you must terminate sync. Then, you can enable it again with the new partition key. However, this requires all client applications to reset and sync data into new realms.
Warning
Restore Sync after Terminating Sync
When you terminate and re-enable Atlas Device Sync, clients can no longer Sync. Your client must implement a client reset handler to restore Sync. This handler can discard or attempt to recover unsynchronized changes.
Partition Value
A partition value is a value of the partition key field for a given document. Documents with the same partition value belong to the same partition. They sync to the same realm file, and share user-level data access permissions.
A partition's value is the identifier for its corresponding synced realm. You specify the partition's value when you open it as a synced realm in the client. If you change a partition value in Atlas, App Services interprets the change as two operations:
A delete from the old partition.
An insert into the new partition.
Warning
If you change a document's partition value, you lose client-side unsynced changes to the object.
Enable Partition-Based Sync
Before You Begin
You will need the following to enable Partition-Based Sync:
An App Services App. To learn how to create an App, see Create an App.
A linked Atlas data source. To learn how to add a data source, see Link a Data Source.
Procedure
Partition-Based Rules and Permissions
Whenever a user opens a synced realm from a client app, App Services evaluates your app's rules and determines if the user has read and write permissions for the partition. Users must have read permission to sync and read data in a realm and must have write permission to create, modify, or delete objects. Write permission implies read permission, so if a user has write permission then they also have read permission.
Partition-Based Sync Rule Behavior
Sync rules apply to specific partitions and are coupled to your app's data model by the partition key. Consider the following behavior when designing your schemas to ensure that you have appropriate data access granularity and don't accidentally leak sensitive information.
Sync rules apply dynamically based on the user. One user may have full read & write access to a partition while another user has only read permissions or is unable to access the partition entirely. You control these permissions by defining JSON expressions.
Sync rules apply equally to all objects in a partition. If a user has read or write permission for a given partition then they can read or modify all synced fields of any object in the partition.
Write permissions require read permissions, so a user with write access to a partition also has read access regardless of the defined read permission rules.
Partition-Based Sync Permissions
App Services enforces dynamic, user-specific read and write permissions to secure the data in each partition. You define permissions with JSON rule expressions that control whether or not a given user has read or write access to the data in a given partition. App Services evaluates a user's permissions every time they open a synced realm.
Tip
Your rule expressions can use JSON expansions like
%%partition and %%user to dynamically
determine a user's permissions based on the context of their request.
Key Concepts
Read Permissions
A user with read permissions for a given partition can view all fields of any object in the corresponding synced realm. Read permissions do not permit a user to modify data.
Write Permissions
A user with write permissions for a given partition can modify the value of any field of any object in the corresponding synced realm. Write permissions require read permissions, so any user that can modify data can also view that data before and after it's modified.
Permission Strategies
Important
Relationships cannot span partitions
In an app that uses Partition-Based Sync, an object can only have a relationship with other objects in the same partition. The objects can exist in different databases and collections (within the same cluster) as long as the partition key value matches.
You can structure your read and write permission expressions as a set of permission strategies that apply to your partition strategy. The following strategies outline common approaches that you might take to define sync read and write permissions for your app.
Global Permissions
You can define global permissions that apply to all users for all partitions. This is, in essence, a choice to not implement user-specific permissions in favor of universal read or write permissions that apply to all users.
To define a global read or write permission, specify a boolean value or a JSON expression that always evaluates to the same boolean value.
Example | Description | |
|---|---|---|
| The expression true means that all users have the given access
permissions for all partitions. | |
| The expression false means that no users have the given access
permissions for any partitions. | |
| This expression always evaluates to true, so it's effectively the
same as directly specifying true. |
Permissions for Specific Partitions
You can define permissions that apply to a specific partition or a groups of partitions by explicitly specifying their partition values.
Example | Description | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| This expression means that all users have the given access permissions
for data with a partition value of "Public". | |||||||||
| This expression means that all users have the given access permissions
for data with any of the specified partition values. |
Permissions for Specific Users
You can define permissions that apply to a specific user or a group of users by explicitly specifying their ID values.
Example | Description | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| This expression means that the user with id
"5f4863e4d49bd2191ff1e623" has the given access permissions for data
in any partition. | |||||||||
| This expression means that any user with one of the specified user ID
values has the given access permissions for data in any partition. |
Permissions Based on User Data
You can define permissions that apply to users based on specific data defined in their custom user data document, metadata fields, or other data from an authentication provider.
Example | Description | |
|---|---|---|
| This expression means that a user has read access to a
partition if the partition value is listed in the readPartitions
field of their custom user data. | |
| This expression means that a user has write access to a
partition if the partition value is listed in the
data.writePartitions field of their user object. |
Function Rules
You can define complex dynamic permissions by evaluating a function that returns a boolean value. This is useful for permission schemes that require you to access external systems or other custom logic that you cannot express solely in JSON expressions.
Example | Description | |||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| This expression calls the canReadPartition function and
passes in the partition value as its first and only argument. The
function looks up the user's permissions for the partition from a MongoDB
collection and then returns a boolean that indicates if the user can read
data in the requested partition. |
Migrate Partition-Based Sync Rules to App Services Rules
If you migrate your Partition-Based Sync App to Flexible Sync, your data access rules also need to migrate.
Some Partition-Based Sync rule strategies can't translate directly to App Services Rules. You may need to manually migrate permissions that include:
%functionoperator.Function rules are not compatible with Flexible Sync and cannot be migrated.
%%partitionexpansion.App Services Rules do not have an equivalent expansion for
%%partition, so it cannot be migrated.%or,%not,%nor,%andexpansions.These permissions may work, but there is enough nuance that you should test them to ensure expected behavior. Testing new permissions won't work on the App you are migrating. You'll need a new app to test manually-migrated permissions.
See the list of Flexible Sync-compatible expansions for all supported expansions.
You should also check out the Device Sync Permissions Guide for more information about how to work with permissions.
Partition Strategies
A partition strategy is a key/value pattern to divide objects into partitions. Different use cases call for different partition strategies. You can compose partition strategies within the same app to form a larger strategy. This enables you to handle arbitrarily complex use cases.
Which strategy to use depends on your app's data model and access patterns. Consider an app with both public and private data. You might put some data, like announcements, in a public partition. You might restrict other data, like personal information, to privileged users.
When developing a partition strategy, consider:
Data Security: Users may need different read and write access permissions to subsets of data. Consider the permissions users need for types of documents. A user has the same permissions for every document in a partition.
Storage Capacity: Your client apps may have limited on-device storage on some devices and platforms. A partition strategy should take storage limitations into account. Make sure a user can store their synced data on their device.
Tip
Combine Strategies
You can use a partition key name like _partition with a query string
as the value. This lets you use multiple strategies in the same app.
For example:
_partitionKey: "user_id=abcdefg" _partitionKey: "team_id=1234&city='New York, NY'"
You can use functions and rule expressions to parse the string. Sync can determine whether a user has access to a partition based on the combined strategy.
Firehose Strategy
A firehose partition strategy groups all documents into a single partition. With this structure, every user syncs all of your app's data to their device. This approach is functionally a decision to not partition data. This works for basic applications or small public data sets.
Data Security. All data is public to clients with a realm that uses the partition. If a user has read or write access to the partition, they can read or write any document.
Storage Capacity. Every user syncs every document in the partition. All data must fit within your most restrictive storage limitation. Use this strategy only when data sets are small and do not grow quickly.
One way to create a firehose is to set the partition key as an optional field. Don't include a value for this field in any document. App Services maps any document that doesn't include a partition value to the null partition.
You can also set a static partition value. This is when the partition
value doesn't change based on the user or data. For example, realms
across all clients could use the partition value "MyPartitionValue".
Example
An app lets users browse scores and statistics for local high school
baseball games. Consider the following documents in the games and
teams collections:
collection games: [ { teams: ["Brook Ridge Miners", "Southside Rockets"], score: { ... }, date: ... } { teams: ["Brook Ridge Miners", "Uptown Bombers"], score: { ... }, date: ... } { teams: ["Brook Ridge Miners", "Southside Rockets"], score: { ... }, date: ... } { teams: ["Southside Rockets", "Uptown Bombers"], score: { ... }, date: ... } { teams: ["Brook Ridge Miners", "Uptown Bombers"], score: { ... }, date: ... } { teams: ["Southside Rockets", "Uptown Bombers"], score: { ... }, date: ... } ] collection teams: [ { name: "Brook Ridge Miners" } { name: "Southside Rockets" } { name: "Uptown Bombers" } ]
The total number of games is small. A small number of local teams only play a few games each year. Most devices should be able to download all game data for easy offline access. In this case, the firehose strategy is appropriate. The data is public and documents don't need a partition key.
The strategy maps the collections to the following realms:
realm null: [ Game { teams: ["Brook Ridge Miners", "Southside Rockets"], score: { ... }, date: ... } Game { teams: ["Brook Ridge Miners", "Uptown Bombers"], score: { ... }, date: ... } Game { teams: ["Brook Ridge Miners", "Southside Rockets"], score: { ... }, date: ... } Game { teams: ["Southside Rockets", "Uptown Bombers"], score: { ... }, date: ... } Game { teams: ["Brook Ridge Miners", "Uptown Bombers"], score: { ... }, date: ... } Game { teams: ["Southside Rockets", "Uptown Bombers"], score: { ... }, date: ... } Team { name: "Brook Ridge Miners" } Team { name: "Southside Rockets" } Team { name: "Uptown Bombers" } ]
User Strategy
A user partition strategy groups private documents for each user. These documents go into a partition specific to that user. This works when each document has an owner, and nobody else needs the data. A username or ID that identifies the owner makes a natural partition key.
Data Security. Data in a user partition is specific to a given user. It may contain information private to that user. Each user syncs only their own partition. Other users cannot access documents in the partition.
Storage Capacity. Each user only syncs data from their own partition. Their data must fit within their device's storage constraints. Use this strategy only when each user has a manageable amount of data.
Example
A music streaming app stores data about playlists and song ratings for each
user. Consider the following documents in the playlists and ratings
collections:
collection playlists: [ { name: "Work", owner_id: "dog_enthusiast_95", song_ids: [ ... ] } { name: "Party", owner_id: "cat_enthusiast_92", song_ids: [ ... ] } { name: "Soup Tunes", owner_id: "dog_enthusiast_95", song_ids: [ ... ] } { name: "Disco Anthems", owner_id: "PUBLIC", song_ids: [ ... ] } { name: "Deep Focus", owner_id: "PUBLIC", song_ids: [ ... ] } ] collection ratings: [ { owner_id: "dog_enthusiast_95", song_id: 3, rating: -1 } { owner_id: "cat_enthusiast_92", song_id: 1, rating: 1 } { owner_id: "dog_enthusiast_95", song_id: 1, rating: 1 } ]
Every document includes the owner_id field. This is a good partition
key for a user partition strategy. It naturally maps documents to
individual users. This limits the data on each device to playlists and
ratings for the device's user.
Users have read and write access to their user realm. This contains playlists they have created and ratings that they've given to songs.
Every user has read access to the realm for partition value
PUBLIC. This contains playlists that are available to all users.
The strategy maps the collections to the following realms:
realm dog_enthusiast_95: [ Playlist { name: "Work", owner_id: "dog_enthusiast_95", song_ids: [ ... ] } Playlist { name: "Soup Tunes", owner_id: "dog_enthusiast_95", song_ids: [ ... ] } Rating { owner_id: "dog_enthusiast_95", song_id: 3, rating: -1 } Rating { owner_id: "dog_enthusiast_95", song_id: 1, rating: 1 } ] realm cat_enthusiast_92: [ Playlist { name: "Party", owner_id: "cat_enthusiast_92", song_ids: [ ... ] } Rating { owner_id: "cat_enthusiast_92", song_id: 1, rating: 1 } ] realm PUBLIC: [ Playlist { name: "Disco Anthems", owner_id: "PUBLIC", song_ids: [ ... ] } Playlist { name: "Deep Focus", owner_id: "PUBLIC", song_ids: [ ... ] } ]
Team Strategy
A team partition strategy groups private documents shared by a team of users. A team might include a store location's employees or a band's members. Each team has a partition specific to that group. All users in the team share access and ownership of the team's documents.
Data Security. Data in a team partition is specific to a given team. It may contain data private to the team but not to a member of the team. Each user syncs partitions for the teams they belong to. Users not in a team cannot access documents in the team's partition.
Storage Capacity: Each user only syncs data from their own teams. The data from a user's teams must fit within their device's storage constraints. Use this strategy when users belong to a manageable number of teams. If users belong to many teams, the combined realms could contain a lot of data. You may need to limit the number of team partitions synced at a time.
Example
An app lets users create projects to collaborate with other users.
Consider the following documents in the projects
and tasks collections:
collection projects: [ { name: "CLI", owner_id: "cli-team", task_ids: [ ... ] } { name: "API", owner_id: "api-team", task_ids: [ ... ] } ] collection tasks: [ { status: "complete", owner_id: "api-team", text: "Import dependencies" } { status: "inProgress", owner_id: "api-team", text: "Create app MVP" } { status: "inProgress", owner_id: "api-team", text: "Investigate off-by-one issue" } { status: "todo", owner_id: "api-team", text: "Write tests" } { status: "inProgress", owner_id: "cli-team", text: "Create command specifications" } { status: "todo", owner_id: "cli-team", text: "Choose a CLI framework" } ]
Every document includes the owner_id field. This is a good partition
key for a team partition strategy. It naturally maps documents to
individual teams. This limits the data on each device. Users only have
projects and tasks that are relevant to them.
Users have read and write access to partitions owned by teams where they're a member.
Data stored in a
teamsoruserscollection can map users to team membership:collection teams: [ { name: "cli-team", member_ids: [ ... ] } { name: "api-team", member_ids: [ ... ] } ] collection users: [ { name: "Joe", team_ids: [ ... ] } { name: "Liz", team_ids: [ ... ] } { name: "Matt", team_ids: [ ... ] } { name: "Emmy", team_ids: [ ... ] } { name: "Scott", team_ids: [ ... ] } ]
The strategy maps the collections to the following realms:
realm cli-team: [ Project { name: "CLI", owner_id: "cli-team", task_ids: [ ... ] } Task { status: "inProgress", owner_id: "cli-team", text: "Create command specifications" } Task { status: "todo", owner_id: "cli-team", text: "Choose a CLI framework" } ] realm api-team: [ Project { name: "API", owner_id: "api-team", task_ids: [ ... ] } Task { status: "complete", owner_id: "api-team", text: "Import dependencies" } Task { status: "inProgress", owner_id: "api-team", text: "Create app MVP" } Task { status: "inProgress", owner_id: "api-team", text: "Investigate off-by-one issue" } Task { status: "todo", owner_id: "api-team", text: "Write tests" } ]
Channel Strategy
A channel partition strategy groups documents for a common topic or domain. Each topic or domain has its own partition. Users can choose to access or subscribe to specific channels. A name or ID may identify these channels in a public list.
Data Security. Data in a channel partition is specific to a topic or area. Users can choose to access these channels. You can limit a user's access to a subset of channels. You could prevent users from accessing channels entirely. When user has read or write permission for a channel, they can access any document in the partition.
Storage Capacity. Users can choose to sync data from any allowed channel. All data from a user's channels must fit within their device's storage constraints. Use this strategy to partition public or semi-private data sets. This strategy breaks up data sets that would not fit within storage constraints.
Example
An app lets users create chatrooms based on topics. Users can search
for and join channels for any topic that interests them. Consider
these documents in the chatrooms and messages collections:
collection chatrooms: [ { topic: "cats", description: "A place to talk about cats" } { topic: "sports", description: "We like sports and we don't care who knows" } ] collection messages: [ { topic: "cats", text: "Check out this cute pic of my cat!", timestamp: 1625772933383 } { topic: "cats", text: "Can anybody recommend a good cat food brand?", timestamp: 1625772953383 } { topic: "sports", text: "Did you catch the game last night?", timestamp: 1625772965383 } { topic: "sports", text: "Yeah what a comeback! Incredible!", timestamp: 1625772970383 } { topic: "sports", text: "I can't believe how they scored that goal.", timestamp: 1625773000383 } ]
Every document includes the topic field. This is a good partition
key for a channel partition strategy. It naturally maps documents to
individual channels. This reduces the data on each device. Data only
contains messages and metadata for channels the user has chosen.
Users have read and write access to chatrooms where they're subscribed. Users can change or delete any message - even those sent by other users. To limit write permissions, you could give users read-only access. Then, handle sending messages with a serverless function.
Store the use's subscribed channels in either the
chatroomsoruserscollection:collection chatrooms: [ { topic: "cats", subscriber_ids: [ ... ] } { topic: "sports", subscriber_ids: [ ... ] } ] collection users: [ { name: "Joe", chatroom_ids: [ ... ] } { name: "Liz", chatroom_ids: [ ... ] } { name: "Matt", chatroom_ids: [ ... ] } { name: "Emmy", chatroom_ids: [ ... ] } { name: "Scott", chatroom_ids: [ ... ] } ]
The strategy maps the collections to the following realms:
realm cats: [ Chatroom { topic: "cats", description: "A place to talk about cats" } Message { topic: "cats", text: "Check out this cute pic of my cat!", timestamp: 1625772933383 } Message { topic: "cats", text: "Can anybody recommend a good cat food brand?", timestamp: 1625772953383 } ] realm sports: [ Chatroom { topic: "sports", description: "We like sports and we don't care who knows" } Message { topic: "sports", text: "Did you catch the game last night?", timestamp: 1625772965383 } Message { topic: "sports", text: "Yeah what a comeback! Incredible!", timestamp: 1625772970383 } Message { topic: "sports", text: "I can't believe how they scored that goal.", timestamp: 1625773000383 } ]
Region Strategy
A region partition strategy groups documents related to a location or region. Each partition contains documents specific to those areas.
Data Security. Data is specific to a given geographic area. You can limit a user's access to their current region. Alternately, give access to data on a region-by-region basis.
Storage Capacity. Storage needs vary depending on size and usage patterns for the region. Users might only sync data in their own region. The data for any region should fit within a device's storage constraints. If users sync multiple regions, partition into smaller subregions. This helps avoid syncing unneeded data.
Example
An app lets users search for nearby restaurants and order from their
menus. Consider the following documents in the restaurants
collection:
collection restaurants: [ { city: "New York, NY", name: "Joe's Pizza", menu: [ ... ] } { city: "New York, NY", name: "Han Dynasty", menu: [ ... ] } { city: "New York, NY", name: "Harlem Taste", menu: [ ... ] } { city: "Chicago, IL", name: "Lou Malnati's", menu: [ ... ] } { city: "Chicago, IL", name: "Al's Beef", menu: [ ... ] } { city: "Chicago, IL", name: "Nando's", menu: [ ... ] } ]
Every document includes the city field. This is a good partition
key for a region partition strategy. It naturally maps documents to
specific physical areas. This limits data to messages and metadata
for a user's current city. Users have read access to restaurants in
their current region. You could determine the user's region in your
application logic.
The strategy maps the collections to the following realms:
realm New York, NY: [ { city: "New York, NY", name: "Joe's Pizza", menu: [ ... ] } { city: "New York, NY", name: "Han Dynasty", menu: [ ... ] } { city: "New York, NY", name: "Harlem Taste", menu: [ ... ] } ] realm Chicago, IL: [ { city: "Chicago, IL", name: "Lou Malnati's", menu: [ ... ] } { city: "Chicago, IL", name: "Al's Beef", menu: [ ... ] } { city: "Chicago, IL", name: "Nando's", menu: [ ... ] } ]
Bucket Strategy
A bucket partition strategy groups documents by range. When documents range along a dimension, a partition contains a subrange. Consider time-based bucket ranges. Triggers move documents to new partitions when they fall out of their bucket range.
Data Security. Limit users to read or write only specific buckets. Data may flow between buckets. Consider access permissions for a document across all possible buckets.
Storage Capacity. Storage needs vary based on size and usage patterns for each bucket. Consider which buckets users need to access. Limit the size of buckets to fit within a device's storage constraints. If users sync many buckets, partition into smaller buckets. This helps avoid syncing unneeded data.
Example
An IoT app shows real-time views of sensor readings several times a
second. Buckets derive from the number of seconds since the reading
came in. Consider these documents in the readings collection:
collection readings: [ { bucket: "0s<t<=60s", timestamp: 1625773000383 , data: { ... } } { bucket: "0s<t<=60s", timestamp: 1625772970383 , data: { ... } } { bucket: "0s<t<=60s", timestamp: 1625772965383 , data: { ... } } { bucket: "60s<t<=300s", timestamp: 1625772953383 , data: { ... } } { bucket: "60s<t<=300s", timestamp: 1625772933383 , data: { ... } } ]
Every document includes the bucket field. This field maps documents
to specific time ranges. A user's device only contains sensor readings
for the window they view.
Users have read access to sensor readings for any time bucket.
Sensors use client apps with write access to upload readings.
The strategy maps the collections to the following realms:
realm 0s<t<=60s: [ Reading { bucket: "0s<t<=60s", timestamp: 1625773000383 , data: { ... } } Reading { bucket: "0s<t<=60s", timestamp: 1625772970383 , data: { ... } } Reading { bucket: "0s<t<=60s", timestamp: 1625772965383 , data: { ... } } ] realm 60s<t<=300s: [ Reading { bucket: "60s<t<=300s", timestamp: 1625772953383 , data: { ... } } Reading { bucket: "60s<t<=300s", timestamp: 1625772933383 , data: { ... } } ]
Data Ingest
Data Ingest is a feature of Flexible Sync and cannot be enabled on apps that use Partition-Based Sync.
Partition-Based Sync Configuration
When you use Partition-Based Sync, your Atlas App Services app uses this Sync configuration:
{ "type": "partition", "state": <"enabled" | "disabled">, "development_mode_enabled": <Boolean>, "service_name": "<Data Source Name>", "database_name": "<Development Mode Database Name>", "partition": { "key": "<Partition Key Field Name>", "type": "<Partition Key Type>", "permissions": { "read": { <Expression> }, "write": { <Expression> } } }, "last_disabled": <Number>, "client_max_offline_days": <Number>, "is_recovery_mode_disabled": <Boolean> }
Field | Description |
|---|---|
typeString | The sync mode. There are two Sync modes: Flexible Sync and the older Partition-Based Sync. Valid Options for a Partition-Based Sync Configuration:
|
stateString | The current state of the sync protocol for the application. Valid Options:
|
service_nameString | The name of the MongoDB data source
to sync. You cannot use sync with a serverless instance or Federated database instance. |
development_mode_enabledBoolean | If true, Development Mode is enabled
for the application. While enabled, App Services automatically stores synced
objects in a specific database (specified in database_name) and
mirrors objects types in that database's collection schemas. |
database_nameString | The name of a database in the synced cluster where App Services stores data in
Development Mode. App Services automatically
generates a schema for each synced type and maps each object type to a
collection within the database. |
partition.keyString | The field name of your app's partition key. This
field must be defined in the schema for object types that you want to
sync. |
partition.typeString | The value type of the partition key field. This must match the type defined in the object schema. Valid Options:
|
partition.permissions.readExpression | An expression that evaluates to true when a user
has permission to read objects in a partition. If the expression
evaluates to false, App Services does not allow the user to read
an object or its properties. |
partition.permissions.writeExpression | An expression that evaluates to true when a user
has permission to write objects in a partition. If the expression
evaluates to false, App Services does not allow the user to
modify an object or its properties. Write permission requires read
permission. A user cannot write to a document that they cannot read. |
last_disabledNumber | The date and time that sync was last paused or disabled, represented by
the number of seconds since the Unix epoch (January 1, 1970, 00:00:00
UTC). |
client_max_offline_daysNumber | Controls how long the backend compaction
process waits before aggressively pruning metadata that some clients
require to synchronize from an old version of a realm. |
is_recovery_mode_disabledBoolean | If false, Recovery Mode is enabled
for the application. While enabled, Realm SDKs that support this feature
attempt to recover unsynced changes upon performing a client reset.
Recovery mode is enabled by default. |
Alter Your Partition-Based Sync Configuration
You must Terminate Device Sync and Re-enable Device Sync to make changes to your Partition-Based Device Sync Configuration. While you are re-enabling Atlas Device Sync, you can specify a new Partition Key, or changes to your Read/Write Permissions. Making changes to your Device Sync configuration while terminating and re-enabling Device Sync will trigger a client reset. To learn more about handling client resets, read the client reset documentation.
Partition-Based Sync Errors
The following errors may occur when your App uses Partition-Based Sync.
Error Name | Description |
|---|---|
ErrorIllegalRealmPath | This error indicates that the client attempted to open a realm with a partition value of the wrong type. For example, you might see the error message "attempted to bind on illegal realm partition: expected partition to have type objectId but found string". To recover from this error, ensure that the type of the partition value used to open the realm matches the partition key type in your Device Sync configuration. |
Backend Compaction
Atlas Device Sync uses space in your app's synced Atlas cluster to store metadata for synchronization. This includes a history of changes to each realm. Atlas App Services minimizes this space usage in your Atlas cluster. Minimizing metadata is necessary to reduce the time and data needed for sync.
Apps using Partition-Based Sync perform backend compaction to reduce the amount of metadata stored in an Atlas Cluster. Backend compaction is an maintenance process that automatically runs for all Apps using Partition-Based Sync. Using compaction, the backend optimizes a realm's history by removing unneeded changeset metadata. The process removes any instruction whose effect is later overwritten by a newer instruction.
Example
Consider the following realm history:
CREATE table1.object1 UPDATE table1.object1.x = 4 UPDATE table1.object1.x = 10 UPDATE table1.object1.x = 42
The following history would also converge to the same state, but without unneeded interim changes:
CREATE table1.object1 UPDATE table1.object1.x = 42
Note
Partition Based Sync uses backend compaction to reduce Device Sync history stored in Atlas. Flexible Sync achieves this with trimming and client maximum offline time.