How to Use the Union All Aggregation Pipeline Stage in MongoDB 4.4

Adrienne Tacke16 min read • Published Jan 31, 2022 • Updated Sep 23, 2022




Rate this tutorial


With the release of MongoDB 4.4 comes a new aggregation
pipeline
stage called
$unionWith. This stage lets you combine multiple
collections into a single result set!Here's how you'd use it:
Simplified syntax, with no additional processing on the specified
collection

Extended syntax, using optional pipeline field
⚠ If you use the pipeline field to process your collection before
combining, keep in mind that stages that write data, like
$out and
$merge, can't be used!Your resulting documents will merge your current collection's (or
pipeline's) stream of documents with the documents from the
collection/pipeline you specify. Keep in mind that this can include
duplicates!
If you've used the
UNION ALL operation in SQL before, the $unionWith
stage's functionality may sound familiar to you, and you wouldn't be
wrong! Both combine the result sets from multiple queries and return the
merged rows, some of which may be duplicates. However, that's where the
similarities end. Unlike MongoDB's $unionWith stage, you have to
follow a few
rules
in order to run a valid UNION ALL operation in SQL:- Make sure your two queries have the same number of columns
- Make sure the order of columns are the same
- Make sure the matching columns are compatible data types.
It'd look something like this in SQL:
With the
$unionWith stage in MongoDB, you don't have to worry about
these stringent constraints.The most convenient difference between the
$unionWith stage and other
UNION operations is that there's no matching schema restriction. This
flexible schema support means you can combine documents that may not
have the same type or number of fields. This is common in certain
scenarios, where the data we need to use comes from different sources:- TimeSeries data that's stored by month/quarter/some other unit of time
- IoT device data, per fleet or version
- Archival and Recent data, stored in a Data Lake
- Regional data
With MongoDB's
$unionWith stage, combining these data sources is
possible.Ready to try the new
$unionWith stage? Follow along by completing a
few setup steps first. Or, you can skip to the code
samples. 😉First, a general understanding of what the aggregation
framework
is and how to use it will be important for the rest of this tutorial. If
you are unfamiliar with the aggregation framework, check out this great
Introduction to the MongoDB Aggregation
Framework,
written by fellow dev advocate Ken Alger!
Next, based on your situation, you may already have a few prerequisites
setup or need to start from scratch. Either way, choose your scenario to
configure the things you need so that you can follow the rest of this
tutorial!
Choose your scenario:
I don't have an Atlas cluster set up yet:
- You'll need an Atlas account to play around with MongoDB Atlas! Create one if you haven't already done so. Otherwise, log into your Atlas account.
- Setup a free Atlas cluster (no credit card needed!). Be sure to select MongoDB 4.4 (may be Beta, which is OK) as your version in Additional Settings!💡 If you don't see the prompt to create a cluster: You may be prompted to create a project first before you see the prompt to create your first cluster. In this case, go ahead and create a project first (leaving all the default settings). Then continue with the instructions to deploy your first free cluster!
- Once your cluster is set up, add your IP address to your cluster's connection settings. This tells your cluster who's allowed to connect to it.
- Finally, create a database user for your cluster. Atlas requires anyone or anything accessing its clusters to authenticate as MongoDB database users for security purposes! Keep these credentials handy as you'll need them later on.
- Continue with the steps in Connecting to your cluster.
I have an Atlas cluster set up:
Great! You can skip ahead to Connecting to your cluster.
Connecting to your cluster
To connect to your cluster, we'll use the MongoDB for Visual Studio Code
extension (VS Code for short 😊). You can view your data directly,
interact with your collections, and much more with this helpful
extension! Using this also consolidates our workspace into a single
window, removing the need for us to jump back and forth between our code
and MongoDB Atlas!
💡 Though we'll be using the VS Code Extension and VS Code for the rest
of this tutorial, it's not a requirement to use the
$unionWith
pipeline stage! You can also use the
CLI, language-specific
drivers, or
Compass if you prefer!- Install the MongoDB for VS Code extension (or install VS Code first, if you don't already have it 😉).
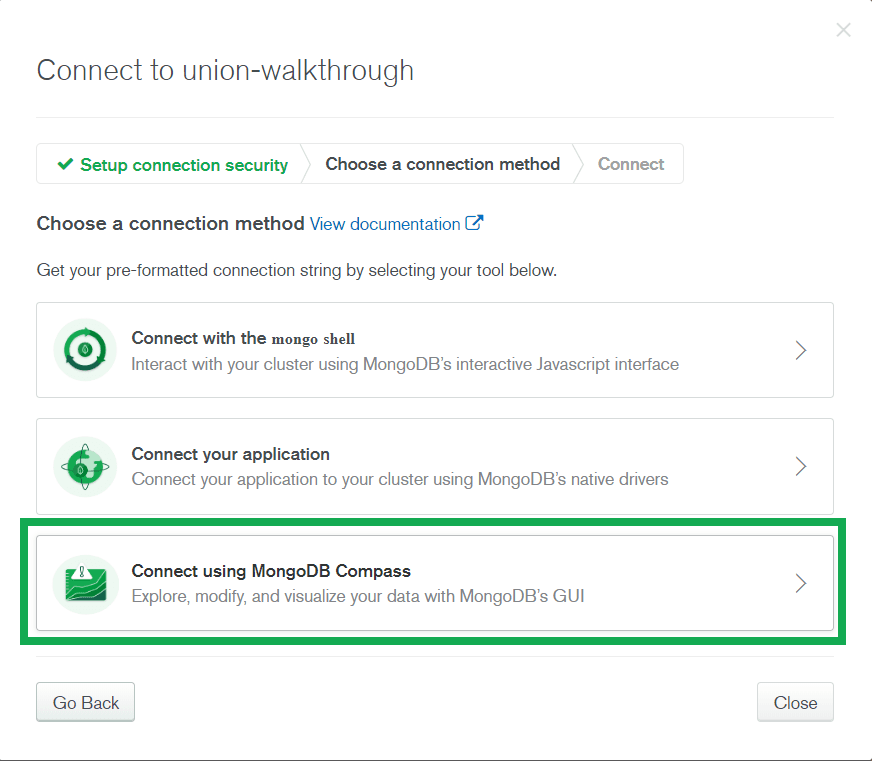
- To connect to your cluster, you'll need a connection string. You can get this connection string from your cluster connection settings. Go to your cluster and select the "Connect" option:

- Select the "Connect using MongoDB Compass" option. This will give us a connection string in the DNS Seedlist Connection format that we can use with the MongoDB extension.
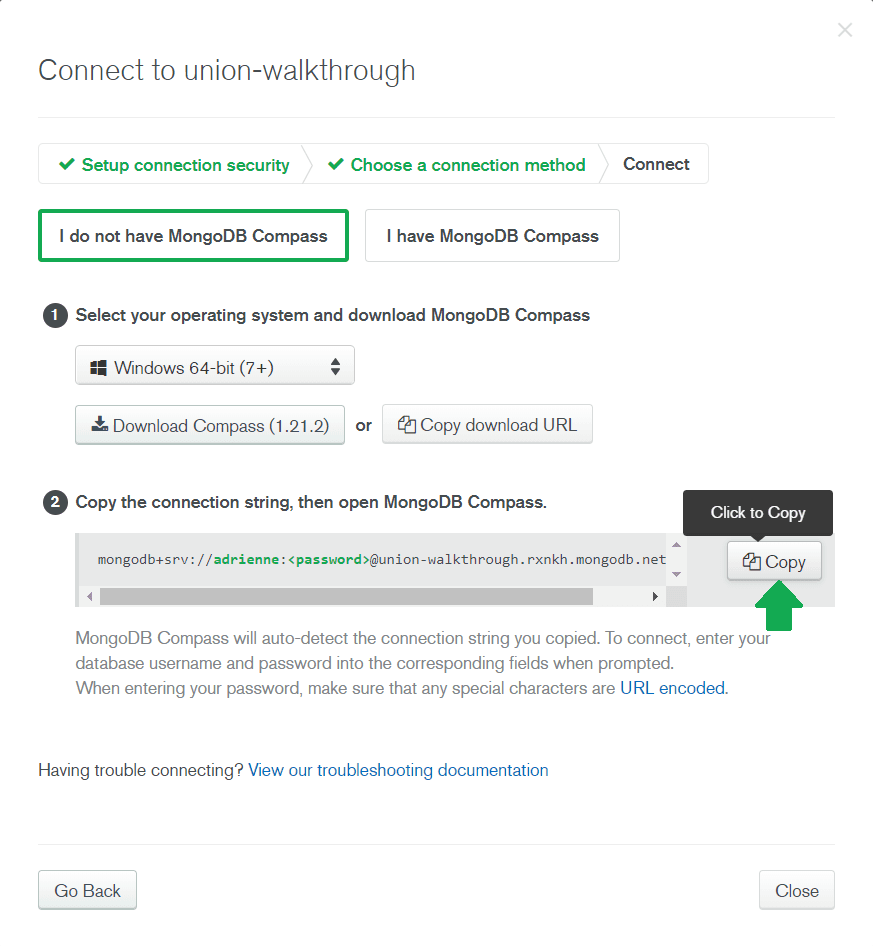
 💡 The MongoDB for VS Code extension also supports the standard connection string format. Using the DNS seedlist connection format is purely preference.
💡 The MongoDB for VS Code extension also supports the standard connection string format. Using the DNS seedlist connection format is purely preference. - Skip to the second step and copy the connection string (don't worry about the other settings, you won't need them):
- Switch back to VS Code. Press
Ctrl+Shift+P(on Windows) orShift+Command+P(on Mac) to bring up the command palette. This shows a list of all VS Code commands.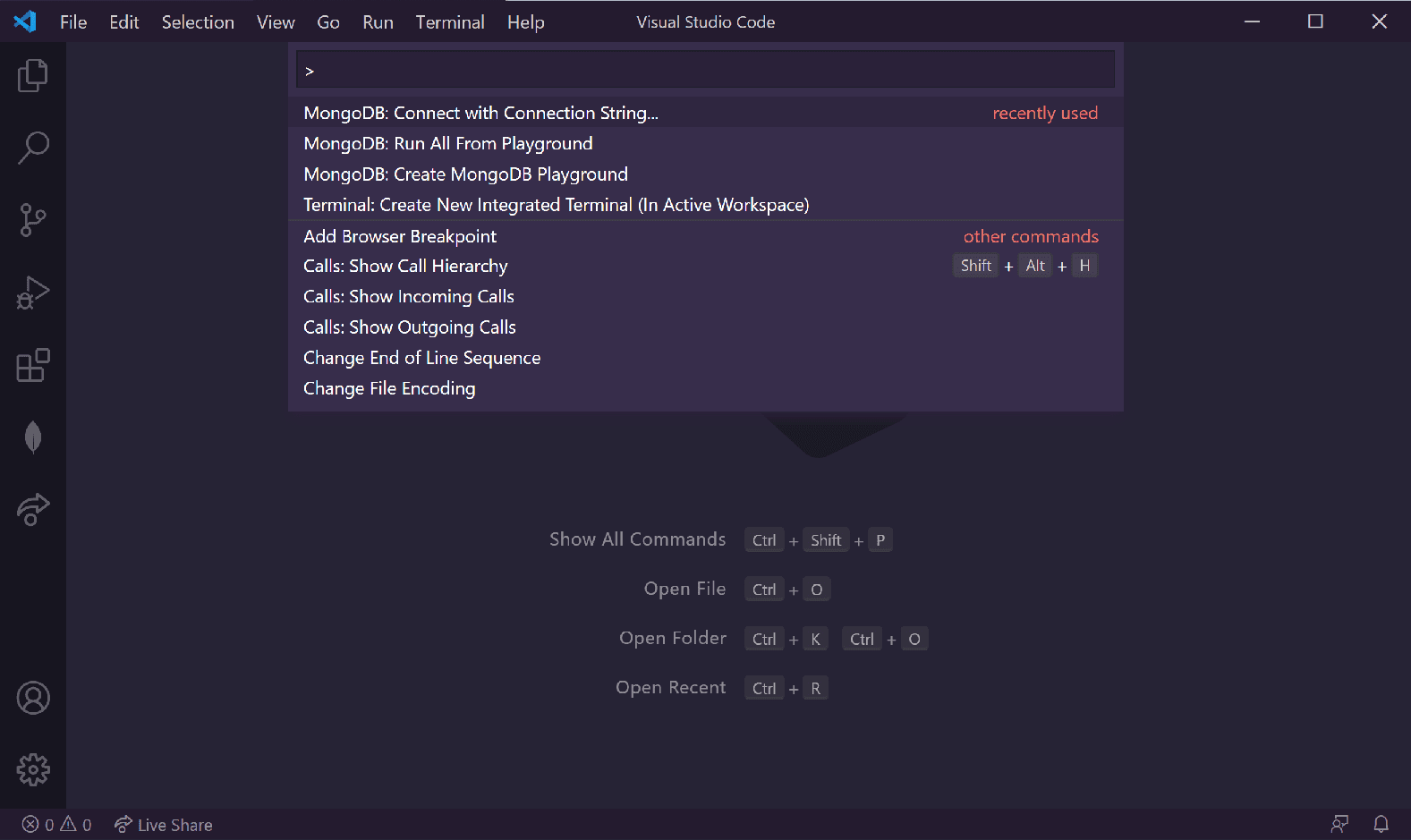
- Start typing "MongoDB" until you see the MongoDB extension's list of available commands. Select the "MongoDB: Connect with Connection String" option.
- Paste in your copied connection string. 💡 Don't forget! You have to replace the placeholder password with your actual password!
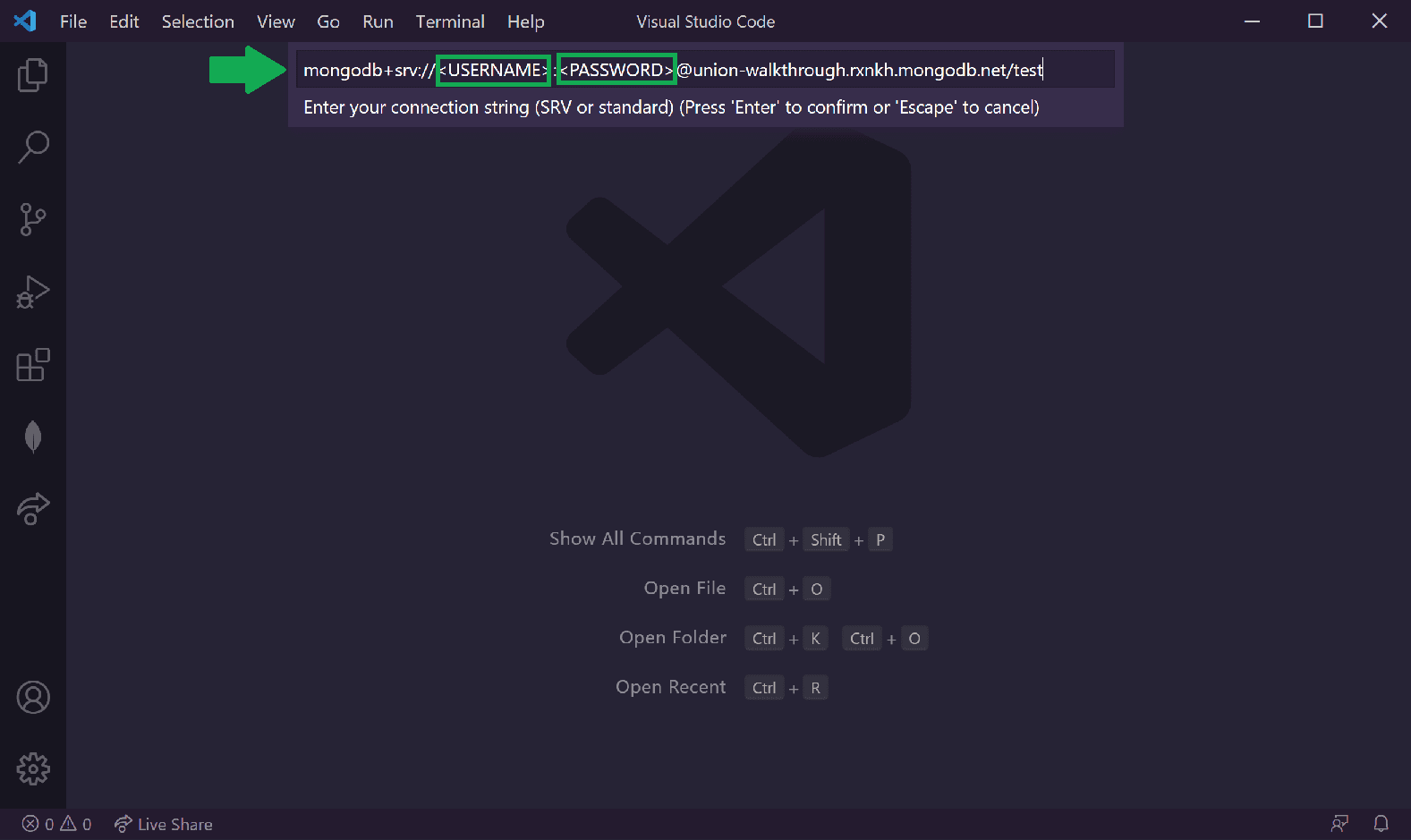
- Press enter to connect! You'll know the connection was successful if you see a confirmation message on the bottom right. You'll also see your cluster listed when you expand the MongoDB extension pane.
With the MongoDB extension installed and your cluster connected, you can now use MongoDB Playgrounds to test out the
$unionWith examples! MongoDB Playgrounds give us a nice sandbox to easily write and test Mongo queries. I love using it when prototying or trying something new because it has query auto-completion and syntax highlighting, something that you don't get in most terminals.Let's finally dive into some examples!
To follow along, you can use these MongoDB Playground
files I
have created to accompany this blog post or create your
own!
💡 If you create your own playground, remember to change the database
name and delete the default template's code first!
Right at the top, specify the database you'll be using. In this example,
I'm using a database also called
union-walkthrough:💡 I haven't actually created a database called
union-walkthrough in
Atlas yet, but that's no problem! When the playground runs, it will see
that it does not yet exist and create a database of the specified name!Next, we need data! Particularly about some planets. And particularly
about planets in a certain movie series. 😉
Using the awesome SWAPI API, I've collected such
information on a few planets. Let's add them into two collections,
separated by popularity.
Any planets that appear in at least 2 or more films are considered
popular. Otherwise, we'll add them into the
lonely_planets collection:This separation is indicative of how our data may be grouped. Despite
the separation, we can use the
$unionWith stage to combine these two
collections if we ever needed to analyze them as a single result set!Let's say that we needed to find out the total population of planets,
grouped by climate. Additionally, we'd like to leave out any planets
that don't have population data from our calculation. We can do this
using an aggregation:
If you've followed along in your own MongoDB playground and have copied
the code so far, try running the aggregation!
And if you're using the provided MongoDB playground I created, highlight
lines 264 - 290 and then run the selected code.
💡 You'll notice in the code snippet above that I've added another
use('union-walkthrough'); method right above the aggregation code. I
do this to make the selection of relevant code within the playground
easier. It's also required so that the aggregation code can run against
the correct database. However, the same thing can be achieved by
selecting multiple lines, namely the original use('union-walkthrough')
line at the top and whatever additional example you'd like to run!You should see the results like so:
Unsurprisingly, planets with "temperate" climates seem to have more
inhabitants. Something about that cool 75 F / 23.8 C, I guess 🌞
Let's break down this aggregation:
The first object we pass into our aggregation is also our first stage,
used here as our filter criteria. Specifically, we use the
$match
pipeline stage:
In this example, we filter out any documents that have
unknown as
their population value using the
$ne (not
equal) operator.The next object (and next stage) in our aggregation is our
$unionWith
stage. Here, we specifiy what collection we'd like to perform a union
with (including any duplicates). We also make use of the pipeline field
to similarly filter out any documents in our popular_planets
collection that have an unknown population:Finally, we have our last stage in our aggregation. After combining our
lonely_planets and popular_planets collections (both filtering out
documents with no population data), we group the resulting documents
using a
$group
stage:Since we want to know the total population per climate type, we first
specify
_id to be the $climate field from our combined result set.
Then, we calculate a new field called totalPopulation by using a
$sum
operator to add each matching document's population values together.
You'll also notice that based on the data we have, we needed to use a
$toLong
operator to first convert our $population field into a calculable
value!Now, if you don't need to run some additional processing on the
collection you're combining with, you don't have to! The
pipeline
field is optional and is only there if you need it.So, if you just need to work with the planet data as a unified set, you
can do that too:
Copy this aggregation into your own playground and run it!
Alternatively, select and run lines 293 - 297 if using the provided
MongoDB playground!
Tada! Now you can use this unified dataset for analysis or further
processing.
Combining the same schemas is great, but we can do that in regular SQL
too! The real convenience of the
$unionWith pipeline stage is that it
can also combine collections with different schemas. Let's take a look!As before, we'll specifiy the database we want to use:
This time, we'll use some acquired information about certain starships
and vehicles that are used in this same movie series. Let's add them to
their respective collections:
You may be thinking (as I first did), what's the difference between
starships and vehicles? You'll be pleased to know that starships are
defined as any "single transport craft that has hyperdrive capability".
Any other single transport craft that does not have hyperdrive
capability is considered a vehicle. The more you know! 😮
If you look at the two collections, you'll see that they have two key
differences:
- The
max_atmosphering_speedfield is present in both collections, but is astringin thestarshipscollection and anintin thevehiclescollection. - The
starshipscollection has two fields (hyperdrive_rating,MGLT) that are not present in thevehiclescollection, as it only relates to starships.
But you know what? That's not a problem for the
$unionWith stage! You
can combine them just as before:Try running the aggregation in your playground! Or if you're following
along in the MongoDB playground I've provided, select and run lines
185 - 189! You should get the following combined result set as your
output:
Can you imagine doing that in SQL? Hint: You can't! That kind of schema
restriction is something you don't need to worry about with MongoDB,
though!
So we can combine different schemas no problem. What if we need to do a
little extra work on our collection before combining it? That's where
the
pipeline field comes in!Let's say that there's some classified information in our data about the
vehicles. Namely, any vehicles manufactured by Kuat Drive Yards (AKA a
division of the Imperial Department of Military Research).
By direct orders, you are instructed not to give out this information
under any circumstances. In fact, you need to intercept any requests for
vehicle information and remove these classified vehicles from the list!
We can do that like so:
In this example, we're combining the
starships and vehicles
collections as before, using the $unionWith pipeline stage. We also
process the vehicle data a bit more, using the $unionWith's optional
pipeline field:In our case, we are evaluating whether or not the
manufacturer field
holds a value of "Kuat Drive Yards, Imperial Department of Military
Research". If it does (uh oh, that's classified!), we use a system
variable called
$$PRUNE,
which lets us exclude all fields at the current document/embedded
document level. If it doesn't, we use another system variable called
$$DESCEND,
which will return all fields at the current document level, except for
any embedded documents.This works perfectly for our use case. Try running the aggregation
(lines 192 - 211, if using the provided MongoDB Playground). You should
see a combined result set, minus any Imperial manufactured vehicles:
We did our part to restrict classified information! 🎶 Hums Imperial
March 🎶
Now that we know how the
$unionWith stage works, it's important to
discuss its limits and restrictions.We've mentioned it already, but it's important to reiterate: using the
$unionWith stage will give you a combined result set which may include
duplicates! This is equivalent to how the UNION ALL operator works in
SQL as well. As a workaround, using a $group stage at the end of
your pipeline to remove duplicates is advised, but only when possible
and if the resulting data does not get inaccurately skewed.There are plans to add similar fuctionality to
UNION (which combines
result sets but removes duplicates), but that may be in a future
release.If you use a
$unionWith stage as part of a
$lookup
pipeline, the collection you specify for the $unionWith cannot be
sharded. As an example, take a look at this aggregation:The coll
questionable_planets (located within the $unionWith stage)
cannot be sharded. This is enforced to prevent a significant decrease in
performance due to the shuffling of data around the cluster as it
determines the best execution plan.Aggregation pipelines can't use the
$unionWith stage inside
transactions because a rare, but possible 3-thread deadlock can occur in
very niche scenarios. Additionally, in MongoDB 4.4, there is a
first-time definition of a view that would restrict its reading from
within a transaction.The
$out
and
$merge
stages cannot be used in a
$unionWith pipeline. Since both $out and
$merge are stages that write data to a collection, they need to be
the last stage in a pipeline. This conflicts with the usage of the
$unionWith stage as it outputs its combined result set onto the next
stage, which can be used at any point in an aggregation pipeline.If your aggregation includes a
collation,
that collation is used for the operation, ignoring any other collations.
However, if your aggregation doesn't include a collation, it will use
the collation for the top-level collection/view on which the aggregation
is run:
- If the
$unionWithcoll is a collection, its collation is ignored. - If the
$unionWithcoll is a view, then its collation must match that of the top-level collection/view. Otherwise, the operation errors.
We've discussed what the
$unionWith pipeline stage is and how you can
use it in your aggregations to combine data from multiple collections.
Though similar to SQL's UNION ALL operation, MongoDB's $unionWith
stage distinguishes itself through some convenient and much-needed
characteristics. Most notable is the ability to combine collections with
different schemas! And as a much needed improvement, using a
$unionWith stage eliminates the need to write additional code, code
that was required because we had no other way to combine our data!If you have any questions about the
$unionWith pipeline stage or this
blog post, head over to the MongoDB Community
forums or Tweet
me!Rate this tutorial