Currency Analysis with Time Series Collections #2 — Simple Moving Average and Exponential Moving Average Calculation





Rate this tutorial


In the previous post, we learned how to group currency data based on given time intervals to generate candlestick charts to perform trend analysis. In this article, we’ll learn how the moving average can be calculated on time-series data.
Moving average is a well-known financial technical indicator that is commonly used either alone or in combination with other indicators. Additionally, the moving average is included as a parameter of other financial technical indicators like MACD. The main reason for using this indicator is to smooth out the price updates to reflect recent price changes accordingly. There are many types of moving averages but here we’ll focus on two of them: Simple Moving Average (SMA) and Exponential Moving Average (EMA).
This is the average price value of a currency/stock within a given period.
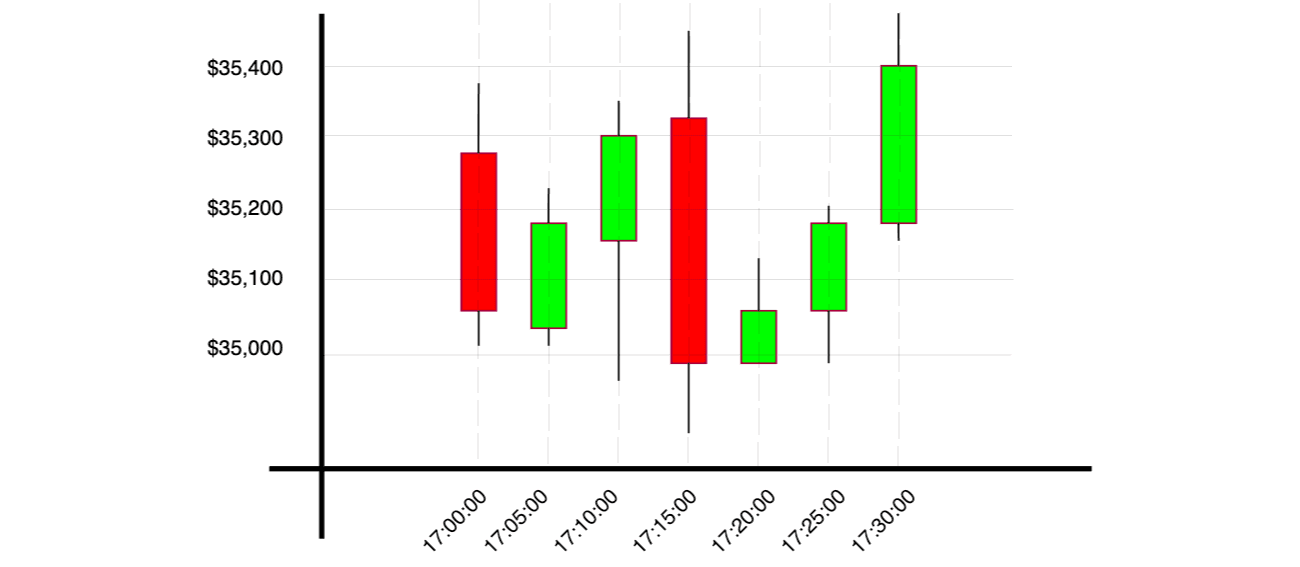
Let’s calculate the SMA for the BTC-USD currency over the last three data intervals, including the current data. Remember that each stick in the candlestick chart represents five-minute intervals. Therefore, for every interval, we would look for the previous three intervals.
First we’ll group the BTC-USD currency data for five-minute intervals:

And, we will have the following candlestick chart:
We have four metrics for each interval and we will choose the close price as the numeric value for our moving average calculation. We are only interested in
_id (a nested field that includes the symbol and time information) and the close price. Therefore, since we are not interested in high, low, open prices for SMA calculation, we will exclude it from the aggregation pipeline with the $project aggregation stage:After we grouped and trimmed, we will have the following dataset:
Once we have the above dataset, we want to enrich our data with the simple moving average indicator as shown below. Every interval in every symbol will have one more field (sma) to represent the SMA indicator by including the current and last three intervals:
How is it calculated? For the time,
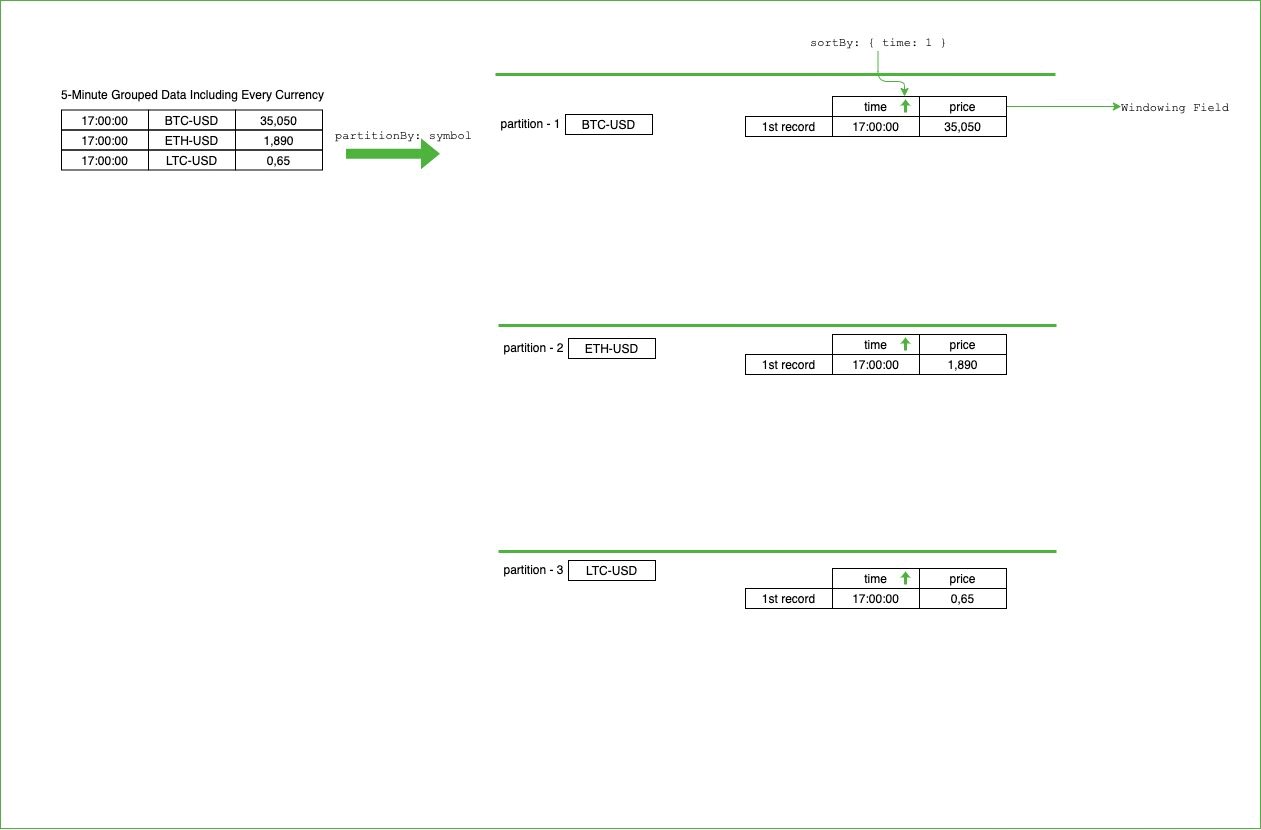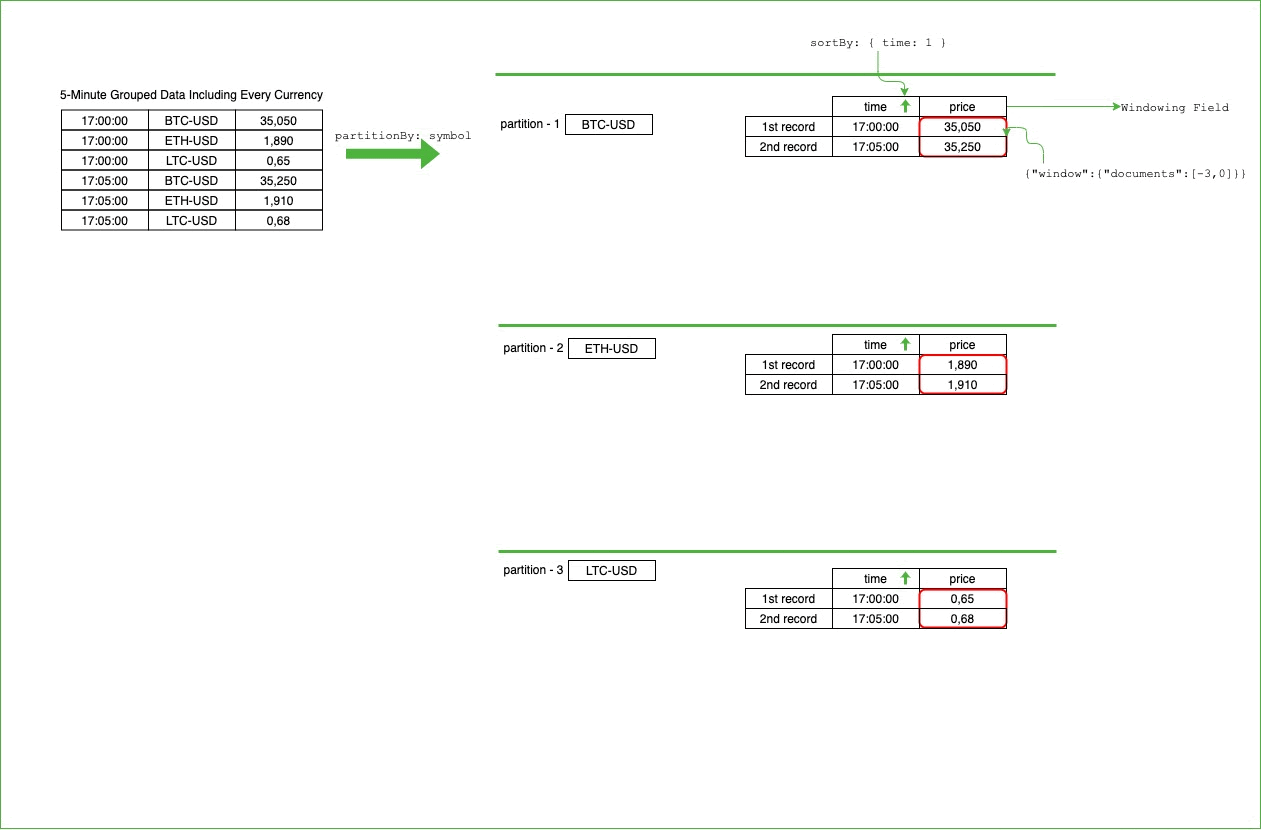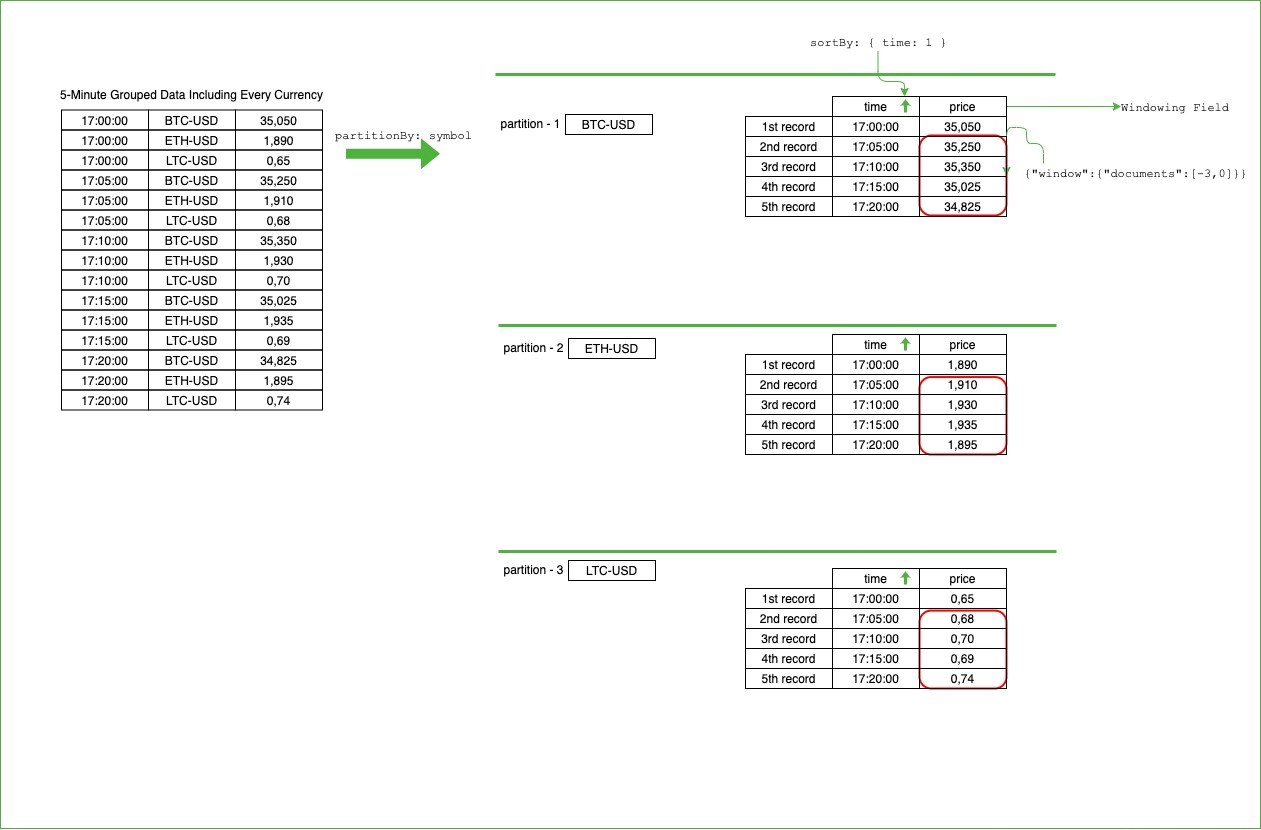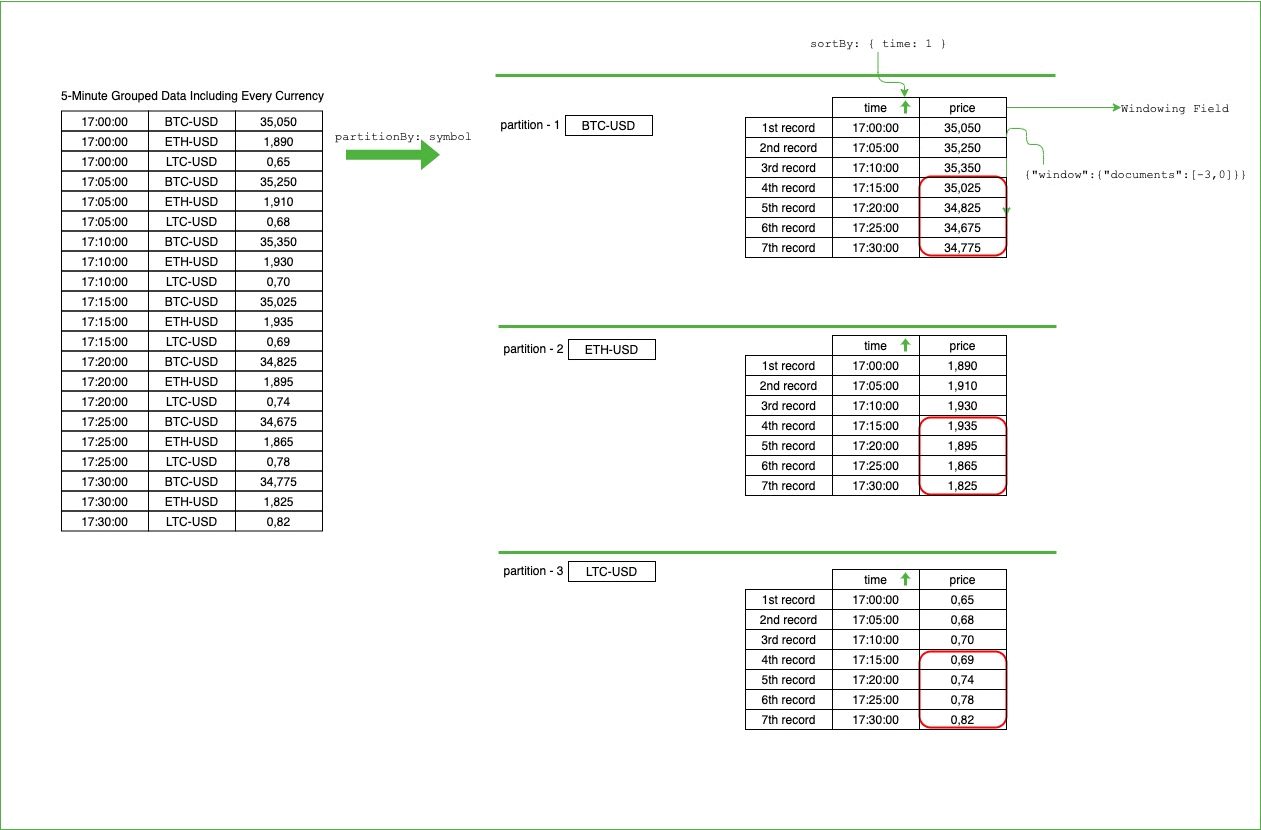
17:00:00, the calculation of SMA is very simple. Since we don’t have the three previous data points, we can take the existing price (35050) at that time as average. If we don’t have three previous data points, we can get all the available possible price information and divide by the number of price data.The harder part comes when we have more than three previous data points. If we have more than three previous data points, we need to remove the older ones. And, we have to keep doing this as we have more data for a single symbol. Therefore, we will calculate the average by considering only up to three previous data points. The below table represents the calculation step by step for every interval:
| Time | SMA Calculation for the window (3 previous + current data points) |
|---|---|
| 17:00:00 | 35050/1 |
| 17:05:00 | (35050+35170)/2 |
| 17:10:00 | (35050+35170+35280)/3 |
| 17:15:00 | (35050+35170+35280+34910)/4 |
| 17:20:00 | (35170+35280+34910+35060)/4 *oldest price data (35050) discarded from the calculation |
| 17:25:00 | (35280+34910+35060+35150)/4 *oldest price data (35170) discarded from the calculation |
| 17:30:00 | (34190+35060+35150+35350)/4 *oldest price data (35280) discarded from the calculation |
As you see above, the window for the average calculation is moving as we have more data.
Until now, we learned the theory of moving average calculation. How can we use MongoDB to do this calculation for all of the currencies?
MongoDB 5.0 introduced a new aggregation stage,
$setWindowFields, to perform operations on a specified range of documents (window) in the defined partitions. Because it also supports average calculation on a window through $avg operator, we can easily use it to calculate Simple Moving Average:We chose the symbol field as partition key. For every currency, we have a partition, and each partition will have its own window to process that specific currency data. Therefore, when we’d like to process sequential data of a single currency, we will not mingle the other currency’s data.
After we set the partition field, we apply sorting to process the data in an ordered way. The partition field provides processing of single currency data together. However, we want to process data as ordered by time. As we see in how SMA is calculated on the paper, the order of the data matters and therefore, we need to specify the field for ordering.
After partitions are set and sorted, then we can process the data for each partition. We generate one more field, “
sma”, and we define the calculation method of this derived field. Here we set three things:- The operator that is going to be executed (
$avg). - The field (
$price) where the operator is going to be executed on. - The boundaries of the window (
[-3,0]). [-3: “start from 3 previous data points”.0]: “end up with including current data point”.- We can also set the second parameter of the window as “
current” to include the current data point rather than giving numeric value.
Moving the window on the partitioned and sorted data will look like the following. For every symbol, we’ll have a partition, and all the records belonging to that partition will be sorted by the time information:
If we bring all the aggregation stages together, we will end-up with this aggregation pipeline:
You may want to add more calculated fields with different options. For example, you can have two SMA calculations with different parameters. One of them could include the last three points as we have done already, and the other one could include the last 10 points, and you may want to compare both. Find the query below:
Here in the above code, we set two derived fields. The
sma_3 field represents the moving average for the last three data points, and the sma_10 field represents the moving average for the 10 last data points. Furthermore, you can compare these two moving averages to take a position on the currency or use it for a parameter for your own technical indicator.The below chart shows two moving average calculations. The line with blue color represents the simple moving average with the window
[-3,0]. The line with the turquoise color represents the simple moving average with the window [-10,0]. As you can see, when the window is bigger, reaction to price change gets slower: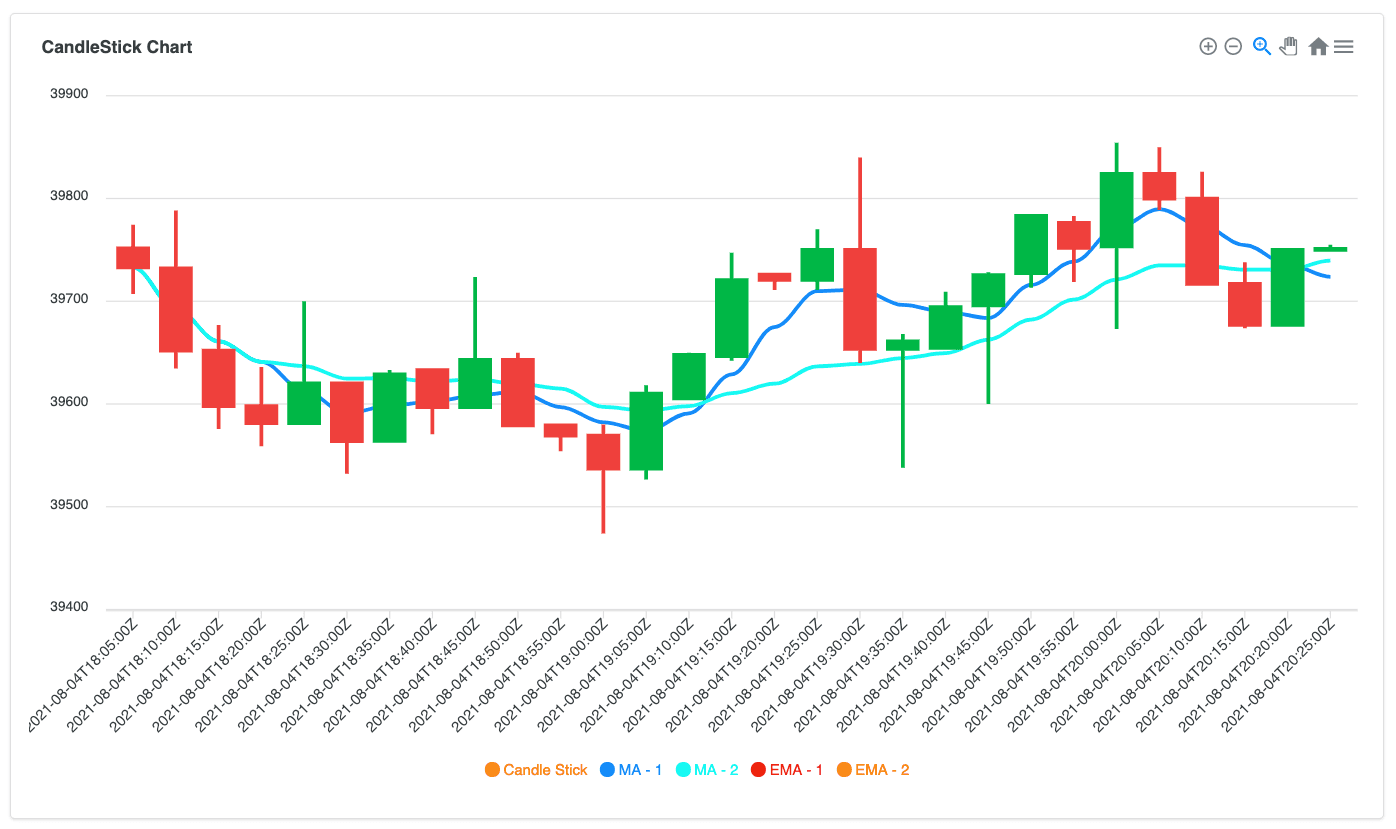
You can even enrich it further with the additional operations such as covariance, standard deviation, and so on. Check the full supported options here. We will cover the Exponential Moving Average here as an additional operation.
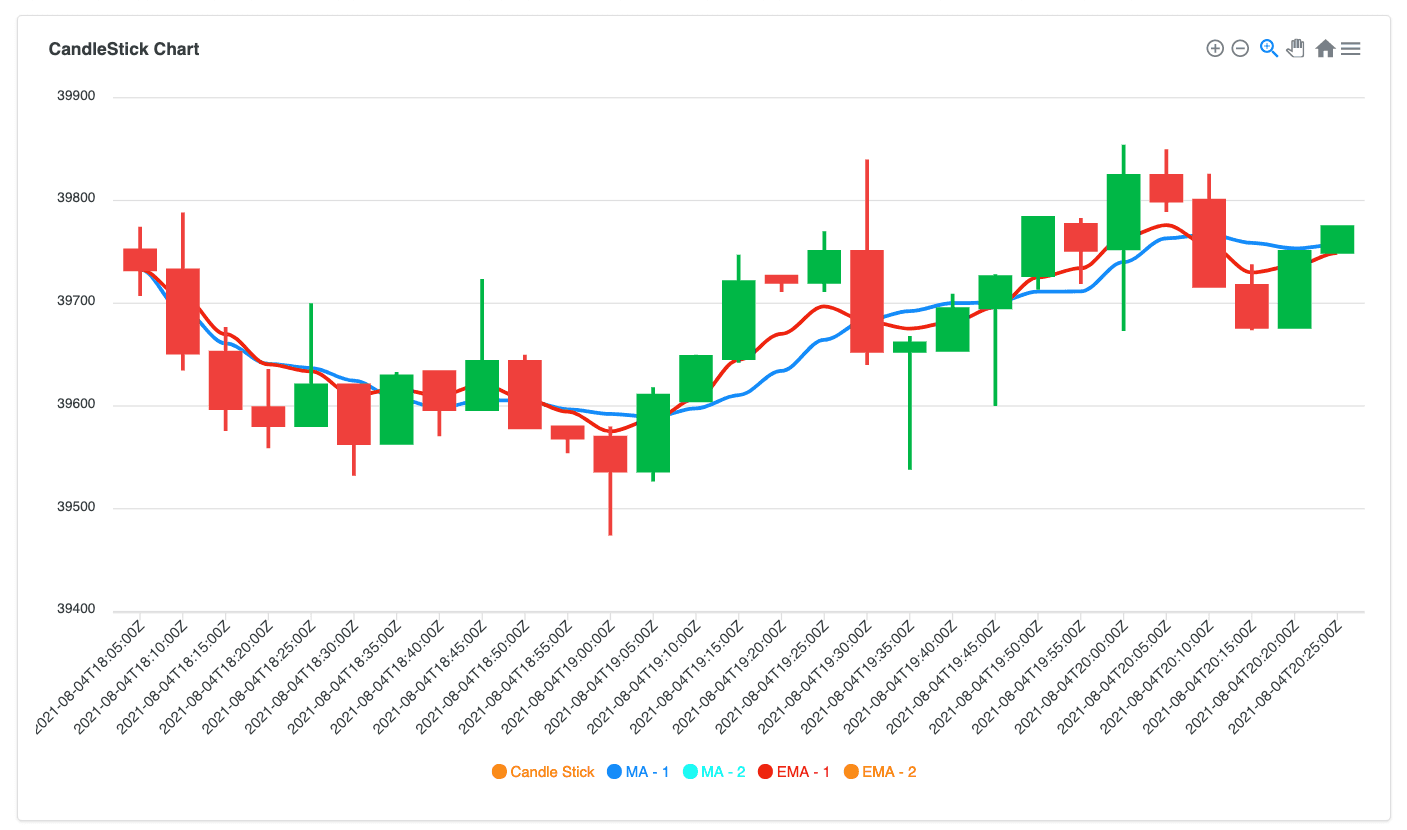
EMA is a kind of moving average. However, it weighs the recent data higher. In the calculation of the Simple Moving Average, we equally weight all the input parameters. However, in the Exponential Moving Average, based on the given parameter, recent data gets more important. Therefore, Exponential Moving Average reacts faster than Simple Moving Average to recent price updates within the similar size window.
$expMovingAvg has been introduced in MongoDB 5.0. It takes two parameters: the field name that includes numeric value for the calculation, and N or alpha value. We’ll set the parameter N to specify how many previous data points need to be evaluated while calculating the moving average and therefore, recent records within the N data points will have more weight than the older data. You can refer to the documentation for more information:In the below diagram, SMA is represented with the blue line and EMA is represented with the red line, and both are calculated by five recent data points. You can see how the Simple Moving Average reacts slower to the recent price updates than the Exponential Moving Average even though they both have the same records in the calculation:
MongoDB 5.0, with the introduction of Windowing Function, makes calculations much easier over a window. There are many aggregation operators that can be executed over a window, and we have seen
$avg and $expMovingAvg in this article.Here in the given examples, we set the window boundaries by including the positional documents. In other words, we start to include documents from three previous data points to current data point (
documents: [-3,0]). You can also set a range of documents rather than defining position.For example, if the window is sorted by time, you can include the last 30 minutes of data (whatever number of documents you have) by specifying the range option as follows:
range: [-30,0], unit: "minute". Now, we may have hundreds of documents in the window but we know that we only include the documents that are not older than 30 minutes than the current data.You can also materialize the query output into another collection through
$out or $merge aggregation stages. And furthermore, you can enable change streams or Database Triggers on the materialized view to automatically trigger buy/sell actions based on the result of technical indicator changes.Rate this tutorial