Massive Number of Collections


Lauren Schaefer, Daniel Coupal6 min read • Published Feb 12, 2022 • Updated May 31, 2022





Rate this article


In the first post in this MongoDB Schema Design Anti-Patterns series, we discussed how we should avoid massive arrays when designing our schemas. But what about having a massive number of collections? Turns out, they're not great either. In this post, we'll examine why.
Are you more of a video person? This is for you.
Let's begin by discussing why having a massive number of collections is an anti-pattern. If storage is relatively cheap, who cares how many collections you have?
Every collection in MongoDB automatically has an index on the _id field. While the size of this index is pretty small for empty or small collections, thousands of empty or unused indexes can begin to drain resources. Collections will typically have a few more indexes to support efficient queries. All of these indexes add up.
Additionally, the WiredTiger storage engine (MongoDB's default storage engine) stores a file for each collection and a file for each index. WiredTiger will open all files upon startup, so performance will decrease when an excessive number of collections and indexes exist.
In general, we recommend limiting collections to 10,000 per replica set. When users begin exceeding 10,000 collections, they typically see decreases in performance.
To avoid this anti-pattern, examine your database and remove unnecessary collections. If you find that you have an increasing number of collections, consider remodeling your data so you have a consistent set of collections.
Let's take an example from the greatest tv show ever created: Parks and Recreation. Leslie is passionate about maintaining the parks she oversees, and, at one point, she takes it upon herself to remove the trash in the Pawnee River.
Let's say she wants to keep a minute-by-minute record of the water level and temperature of the Pawnee River, the Eagleton River, and the Wamapoke River, so she can look for trends. She could send her coworker Jerry to put 30 sensors in each river and then begin storing the sensor data in a MongoDB database.
One way to store the data would be to create a new collection every day to store sensor data. Each collection would contain documents that store information about one reading for one sensor.

Let's say that Leslie wants to be able to easily query on the
river and sensor fields, so she creates an index on each field.If Leslie were to store hourly data throughout all of 2019 and create two indexes in each collection (in addition to the default index on
_id), her database would have the following stats:- Database size: 5.2 GB
- Index size: 1.07 GB
- Total Collections: 365
Each day she creates a new collection and two indexes. As Leslie continues to collect data and her number of collections exceeds 10,000, the performance of her database will decline.
Also, when Leslie wants to look for trends across weeks and months, she'll have a difficult time doing so since her data is spread across multiple collections.

Let's say Leslie realizes this isn't a great schema, so she decides to restructure her data. This time, she decides to keep all of her data in a single collection. She'll bucket her information, so she stores one hour's worth of information from one sensor in each document.
Leslie wants to query on the
river and sensor fields, so she creates two new indexes for this collection.If Leslie were to store hourly data for all of 2019 using this updated schema, her database would have the following stats:
- Database size: 3.07 GB
- Index size: 27.45 MB
- Total Collections: 1
By restructuring her data, she sees a massive reduction in her index size (1.07 GB initially to 27.45 MB!). She now has a single collection with three indexes.
With this new schema, she can more easily look for trends in her data because it's stored in a single collection. Also, she's using the default index on
_id to her advantage by storing the hour the water level data was gathered in this field. If she wants to query by hour, she already has an index to allow her to efficiently do so.
For more information on modeling time-series data in MongoDB, see Building with Patterns: The Bucket Pattern.
In the example above, Leslie was able to remove unnecessary collections by changing how she stored her data.
Sometimes, you won't immediately know what collections are unnecessary, so you'll have to do some investigating yourself. If you find an empty collection, you can drop it. If you find a collection whose size is made up mostly of indexes, you can probably move that data into another collection and drop the original. You might be able to use $merge to move data from one collection to another.
Below are a few ways you can begin your investigation.

If your database is hosted in Atlas, navigate to the Atlas Data Explorer. The Data Explorer allows you to browse a list of your databases and collections. Additionally, you can get stats on your database including the database size, index size, and number of collections.
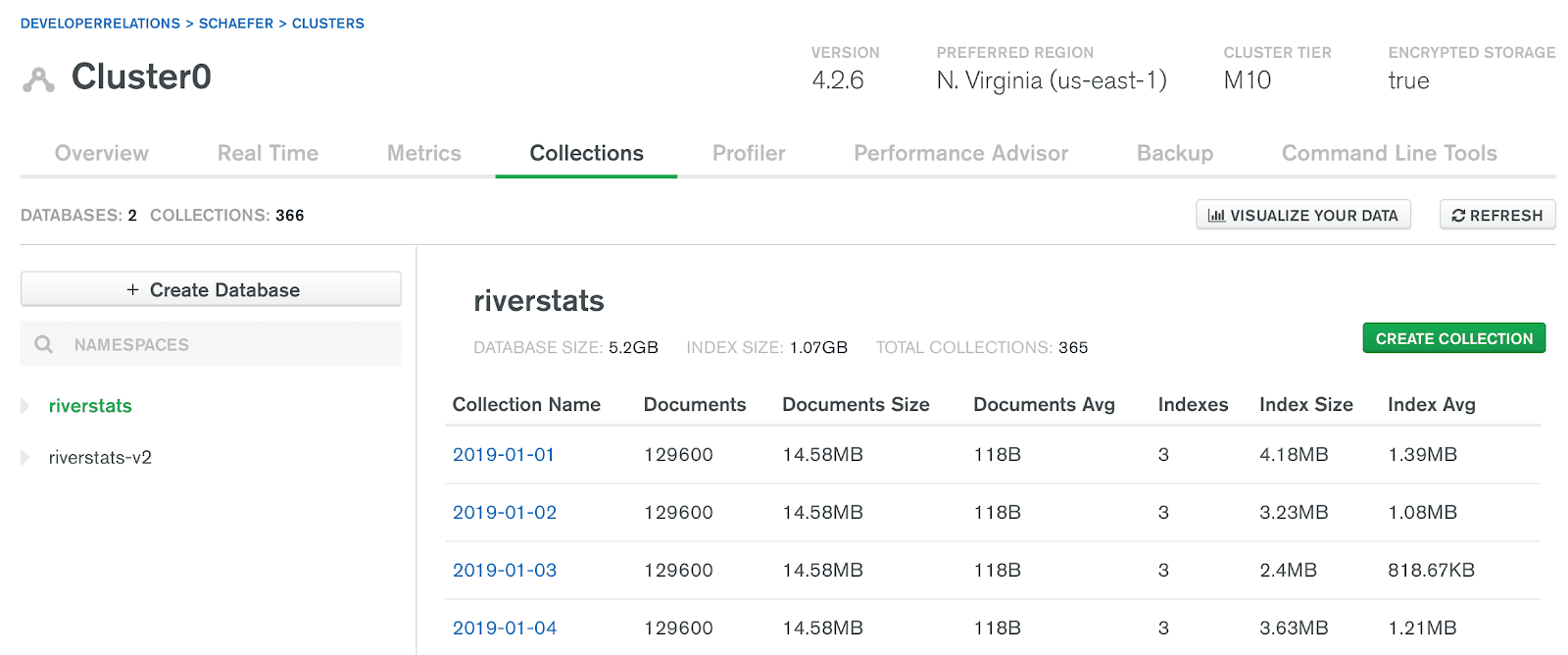
If you are using an M10 cluster or larger on Atlas, you can also use the Real-Time Performance Panel to check if your application is actively using a collection you're considering dropping.
Regardless of where your MongoDB database is hosted, you can use MongoDB Compass, MongoDB's desktop GUI. Similar to the Data Explorer, you can browse your databases and collections so you can check for unused collections. You can also get stats at the database and collection levels.
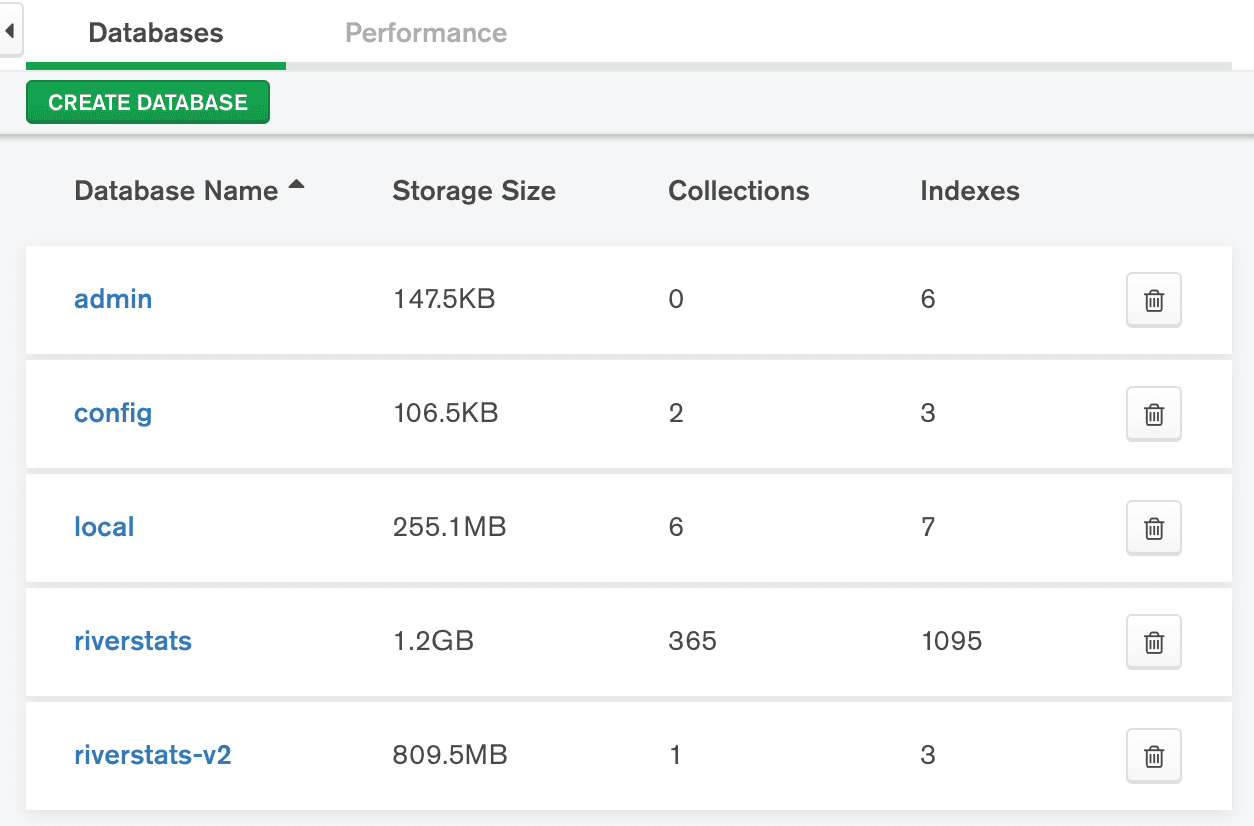
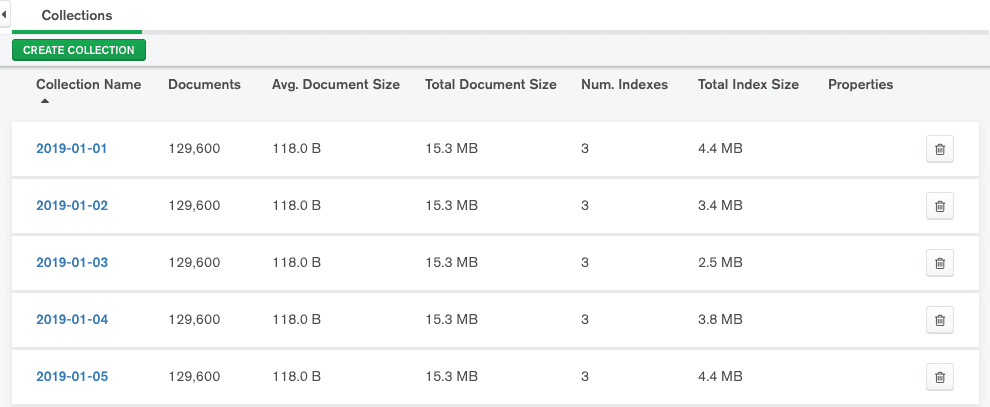
If you prefer working in a terminal instead of a GUI, connect to your database using the mongo shell.
To see a list of collections, run
db.getCollectionNames(). Output like the following will be displayed:To retrieve stats about your database, run
db.stats(). Output like the following will be displayed:You can also run
db.collection.stats() to see information about a particular collection.Be mindful of creating a massive number of collections as each collection likely has a few indexes associated with it. An excessive number of collections and their associated indexes can drain resources and impact your database's performance. In general, try to limit your replica set to 10,000 collections.
Come back soon for the next post in this anti-patterns series!
When you're ready to build a schema in MongoDB, check out MongoDB Atlas, MongoDB's fully managed database-as-a-service. Atlas is the easiest way to get started with MongoDB. With a forever-free tier, you're on your way to realizing the full value of MongoDB.
Check out the following resources for more information:
Rate this article