Kafka to MongoDB Atlas End to End Tutorial





Rate this tutorial


Data and event-driven applications are in high demand in a large variety of industries. With this demand, there is a growing challenge with how to sync the data across different data sources.
A widely adopted solution for communicating real-time data transfer across multiple components in organization systems is implemented via clustered queues. One of the popular and proven solutions is Apache Kafka.
The Kafka cluster is designed for streams of data that sequentially write events into commit logs, allowing real-time data movement between your services. Data is grouped into topics inside a Kafka cluster.
MongoDB provides a Kafka connector certified by Confluent, one of the largest Kafka providers. With the Kafka connector and Confluent software, you can publish data from a MongoDB cluster into Kafka topics using a source connector. Additionally, with a sink connector, you can consume data from a Kafka topic to persist directly and consistently into a MongoDB collection inside your MongoDB cluster.
In this article, we will provide a simple step-by-step guide on how to connect a remote Kafka cluster—in this case, a Confluent Cloud service—with a MongoDB Atlas cluster. For simplicity purposes, the installation is minimal and designed for a small development environment. However, through the article, we will provide guidance and links for production-related considerations.
Pre-requisite: To avoid JDK known certificate issues please update your JDK to one of the following patch versions or newer:
- JDK 11.0.7+
- JDK 13.0.3+
- JDK 14.0.2+
Once ready, create a topic to be used in the Kafka cluster. I created one named “orders.”
This “orders” topic will be used by Kafka Sink connector. Any data in this topic will be persisted automatically in the Atlas database.
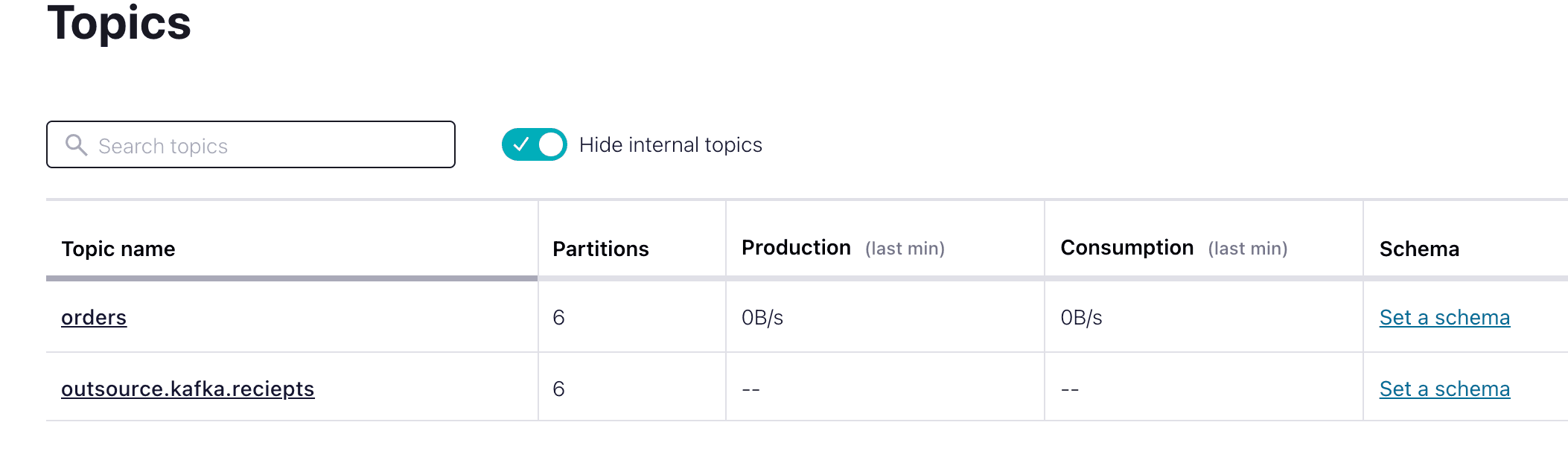
You will also need another topic called "outsource.kafka.receipts". This topic will be used by the MongoDB Source connector, streaming reciepts from Atlas database.
Generate an
api-key and api-secret to interact with this Kafka cluster. For the simplicity of this tutorial, I have selected the “Global Access” api-key. For production, it is recommended to give as minimum permissions as possible for the api-key used. Get a hold of the generated keys for future use.Obtain the Kafka cluster connection string via
Cluster Overview > Cluster Settings > Identification > Bootstrap server for future use. Basic clusters are open to the internet and in production, you will need to amend the access list for your specific hosts to connect to your cluster via advanced cluster ACLs.Create a project and cluster or use an existing Atlas cluster in your project.
Prepare your Atlas cluster for a kafka-connect connection. Inside your project’s access list, enable user and relevant IP addresses of your local host, the one used for Kafka Connect binaries. Finally, get a hold of the Atlas connection string for future use.
Kafka Connect is one of the mechanisms to reliably stream data between different data systems and a Kafka cluster. For production use, we recommend using a distributed deployment for high availability, fault tolerance, and scalability. There is also a cloud version to install the connector on the Confluent Cloud.
To have the binaries to install kafka-connect and all of its dependencies, let’s download the files:

Configure the plugins directory where we will host the MongoDB Kafka Connector plugin:
Edit the
<confluent-install-dir>/etc/schema-registry/connect-avro-standalone.properties using the content provided below. Ensure that you replace the <kafka-cluster>:<kafka-port> with information taken from Confluent Cloud bootstrap server earlier.Additionally, replace the generated
<api-key> and <api-secret> taken from Confluent Cloud in every section.Important: Place the
plugin.path to point to our plugin directory with permissions to the user running the kafka-connect process.The MongoDB Sink connector will allow us to read data off a specific Kafka topic and write to a MongoDB collection inside our cluster. Create a MongoDB sink connector properties file in the main working dir:
mongo-sink.properties with your Atlas cluster details replacing <username>:<password>@<atlas-cluster>/<database> from your Atlas connect tab. The working directory can be any directory that the connect-standalone binary has access to and its path can be provided to the kafka-connect command shown in "Start Kafka Connect and Connectors" section.With the above configuration, we will listen to the topic called “orders” and publish the input documents into database
kafka and collection name orders.The MongoDB Source connector will allow us to read data off a specific MongoDB collection topic and write to a Kafka topic. When data will arrive into a collection called
receipts, we can use a source connector to transfer it to a Kafka predefined topic named “outsource.kafka.receipts” (the configured prefix followed by the <database>.<collection> name as a topic—it's possible to use advanced mapping to change that).Let’s create file
mongo-source.properties in the main working directory:The main properties here are the database, collection, and aggregation pipeline used to listen for incoming changes as well as the connection string. The
topic.prefix adds a prefix to the <database>.<collection> namespace as the Kafka topic on the Confluent side. In this case, the topic name that will receive new MongoDB records is “outsource.kafka.receipts” and was predefined earlier in this tutorial.I have also added
publish.full.document.only=true as I only need the actual document changed or inserted without the change stream event wrapping information.For simplicity reasons, I am running the standalone Kafka Connect in the foreground.
Important: Run with the latest Java version to avoid JDK SSL bugs.
Now every document that will be populated to topic “orders” will be inserted into the
orders collection using a sink connector. A source connector we configured will transmit every receipt document from receipt collection back to another topic called "outsource.kafka.receipts" to showcase a MongoDB consumption to a Kafka topic.Through the Confluent UI, I have submitted a test document to my “orders” topic.

Looking into my Atlas cluster, I can see a new collection named
orders in the kafka database.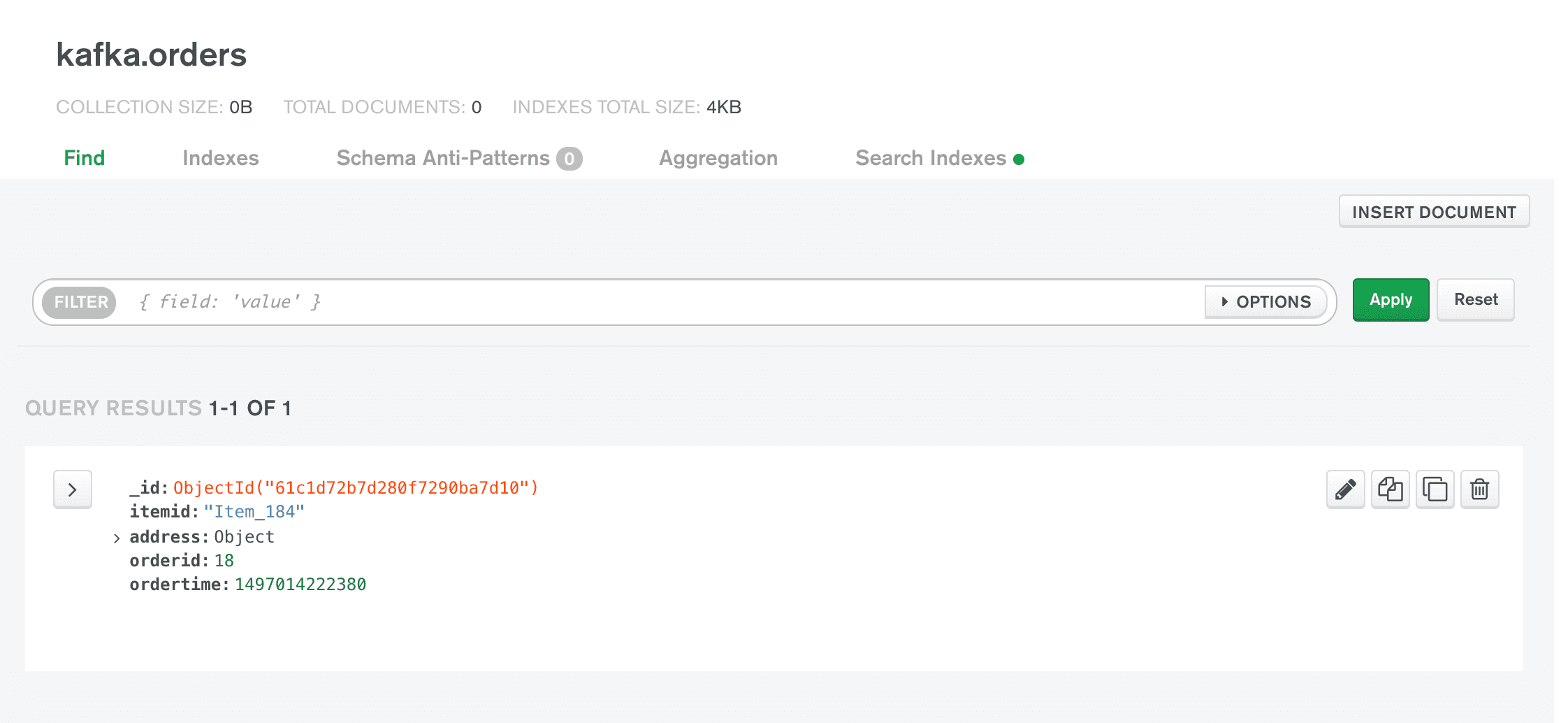
Now, let's assume that our application received the order document from the
orders collection and produced a receipt. We can replicate this by inserting a document in the kafka.reciepts collection: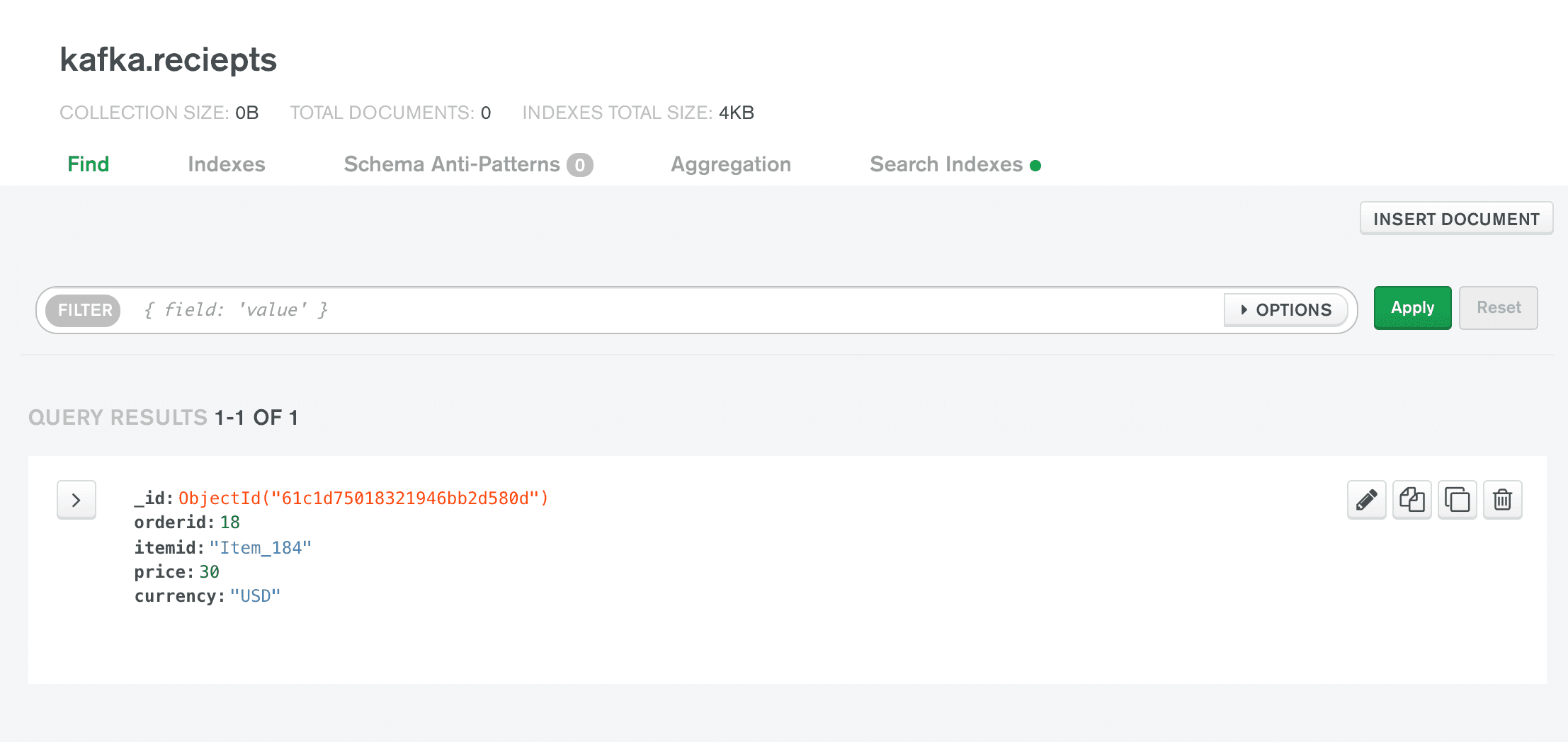
This operation will cause the source connector to produce a message into “outsource.kafka.reciepts” topic.
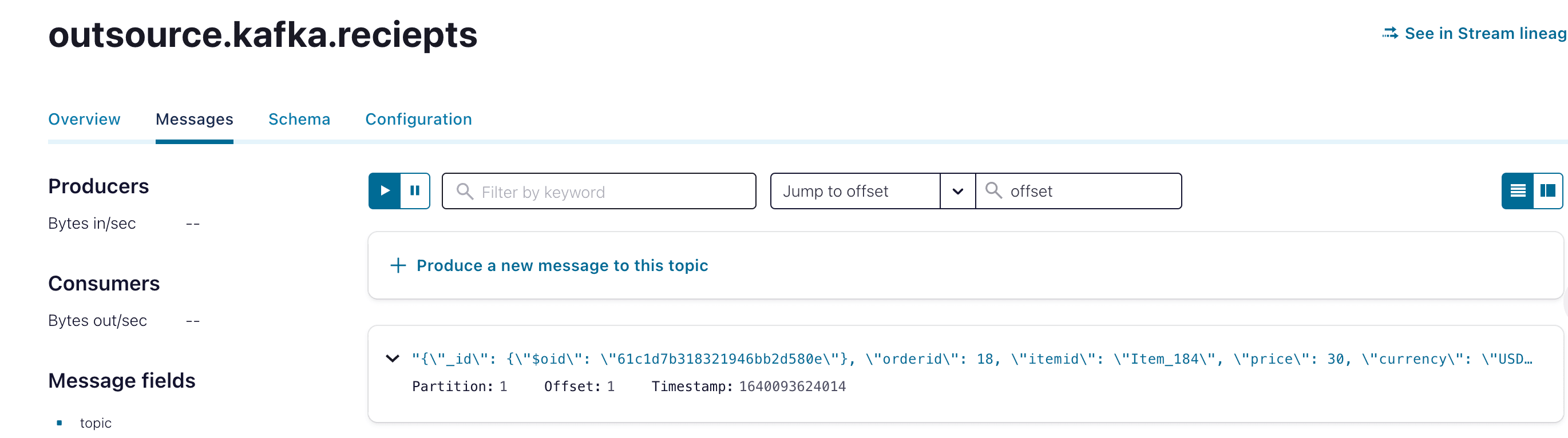
Log lines on kafka-connect will show that the process received and published the document:
In this how-to article, I have covered the fundamentals of building a simple yet powerful integration of MongoDB Atlas to Kafka clusters using MongoDB Kafka Connector and Kafka Connect.
This should be a good starting point to get you going with your next event-driven application stack and a successful integration between MongoDB and Kafka.
Rate this tutorial