Atlas Data Lake SQL Integration to Form Powerful Data Interactions






Rate this article


As of June 2022, the functionality previously known as Atlas Data Lake is now named Atlas Data Federation. Atlas Data Federation’s functionality is unchanged and you can learn more about it here. Atlas Data Lake will remain in the Atlas Platform, with newly introduced functionality that you can learn about here.
Modern platforms have a wide variety of data sources. As businesses grow, they have to constantly evolve their data management and have sophisticated, scalable, and convenient tools to analyse data from all sources to produce business insights.
MongoDB has developed a rich and powerful query language, including a very robust aggregation framework.
These were mainly done to optimize the way developers work with data and provide great tools to manipulate and query MongoDB documents.
Having said that, many developers, analysts, and tools still prefer the legacy SQL language to interact with the data sources. SQL has a strong foundation around joining data as this was a core concept of the legacy relational databases normalization model.
This makes SQL have a convenient syntax when it comes to describing joins.
Providing MongoDB users the ability to leverage SQL to analyse multi-source documents while having a flexible schema and data store is a compelling solution for businesses.
Consider a requirement to create a single view to analyze data from operative different systems. For example:
- Customer data is managed in the user administration systems (REST API).
- Financial data is managed in a financial cluster (Atlas cluster).
- End-to-end transactions are stored in files on cold storage gathered from various external providers (cloud object storage - Amazon S3 or Microsoft Azure Blob Storage).
How can we combine and best join this data?
MongoDB Atlas Data Lake connects multiple data sources using the different source types. Once the data sources are mapped, we can create collections consuming this data. Those collections can have SQL schema generated, allowing us to perform sophisticated joins and do JDBC queries from various BI tools.
In the following view, I have created three main data sources:
- S3 Transaction Store (S3 sample data).
- Accounts from my Atlas clusters (Sample data sample_analytics.accounts).
- Customer data from a secure https source.
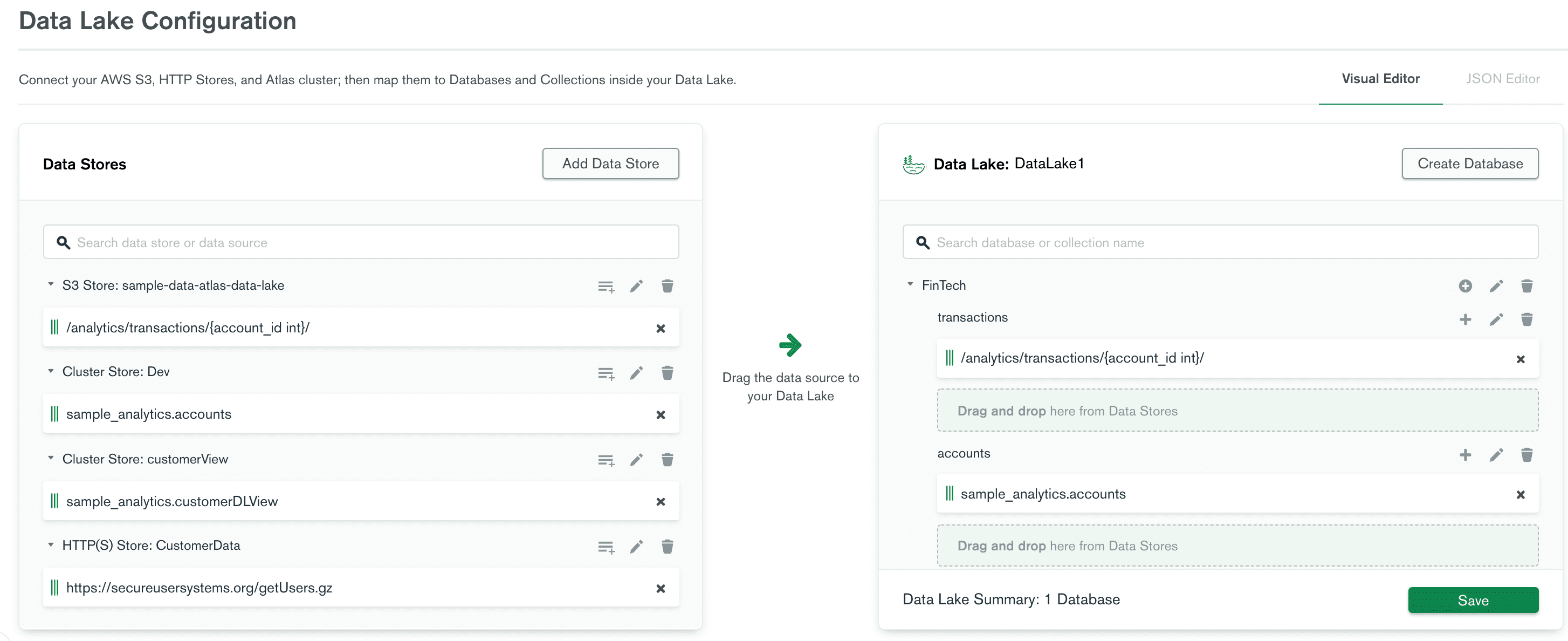
I mapped the stores into three collections under
FinTech database:TransactionsAccountsCustomerDL
Now, I can see them through a data lake connection as MongoDB collections.
Let's grab our data lake connection string from the Atlas UI.
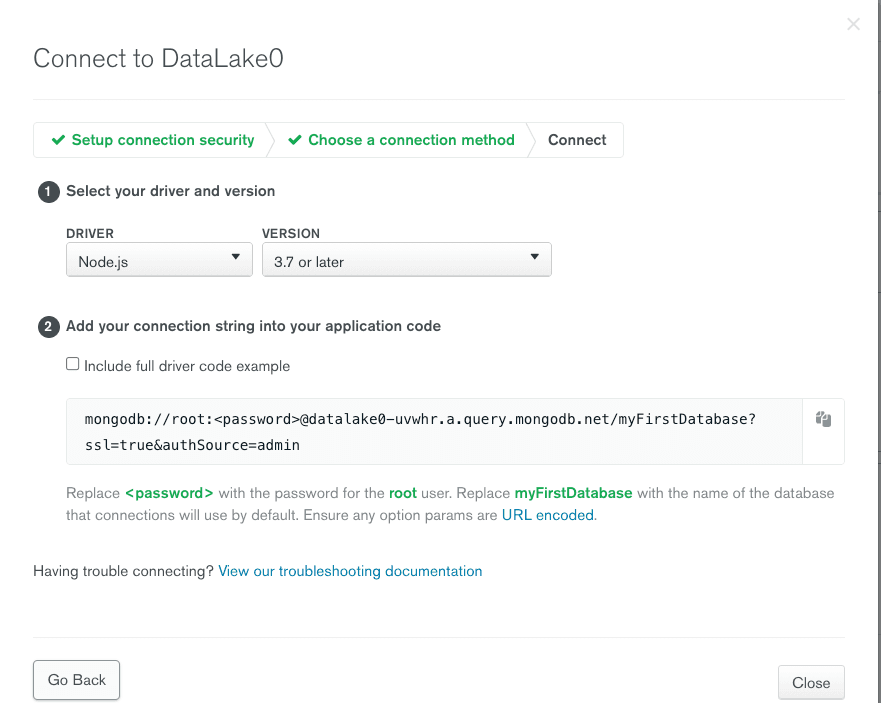
This connection string can be used with our BI tools or client applications to run SQL queries.
Once we connect to the data lake via a mongosh shell, we can generate a SQL schema for our collections. This is required for the JDBC or $sql operators to recognise collections as SQL “tables.”

The above query will prompt account information and the transaction counts of each account.
Let’s connect a powerful BI tool like Tableau with the JDBC driver.

Setting
connection.properties file.Click the “Other Databases (JDBC)” connector and load the connection.properties file pointing to our data lake URI.
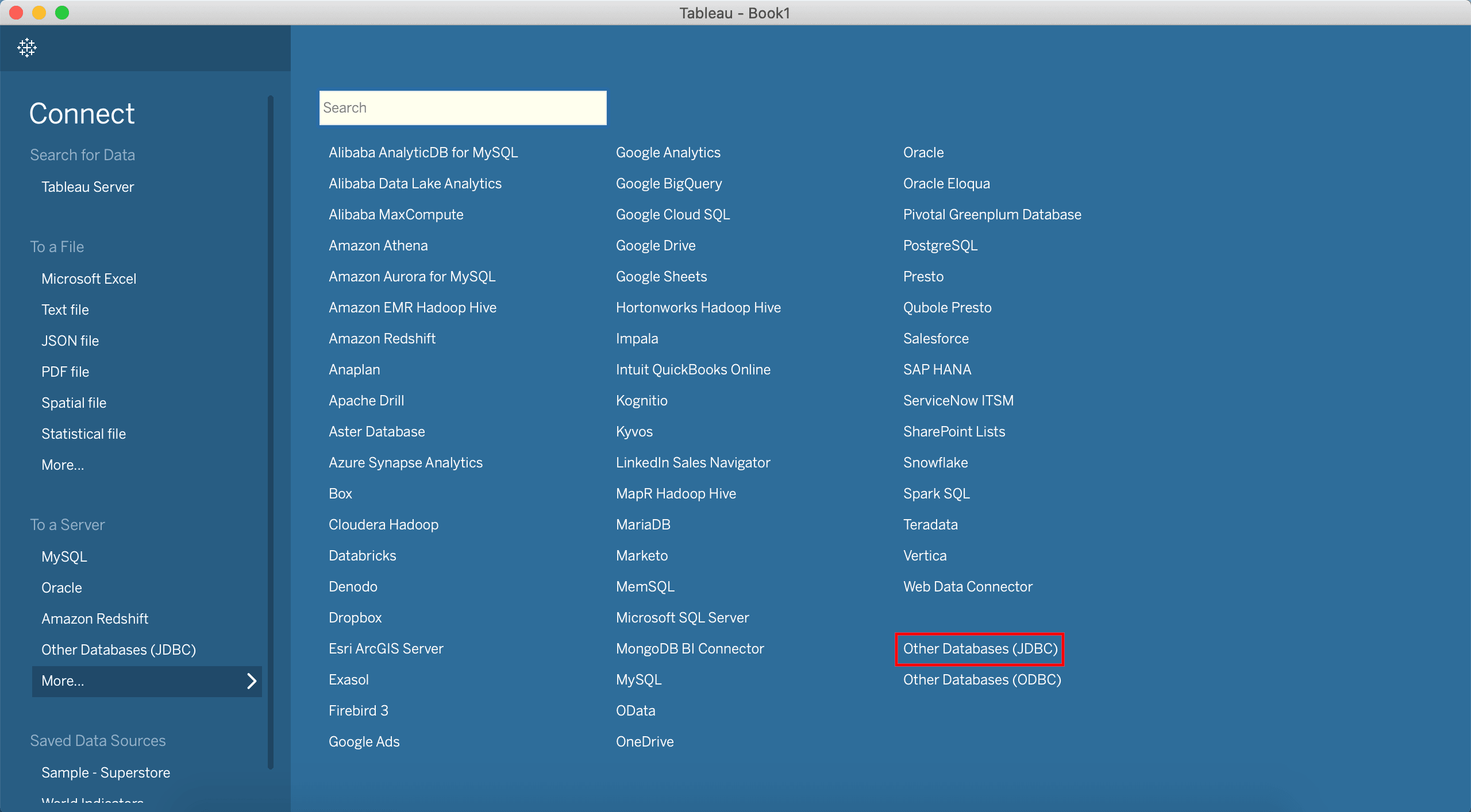
Once the data is read successfully, the collections will appear on the right side.

We can drag and drop collections from different sources and link them together.
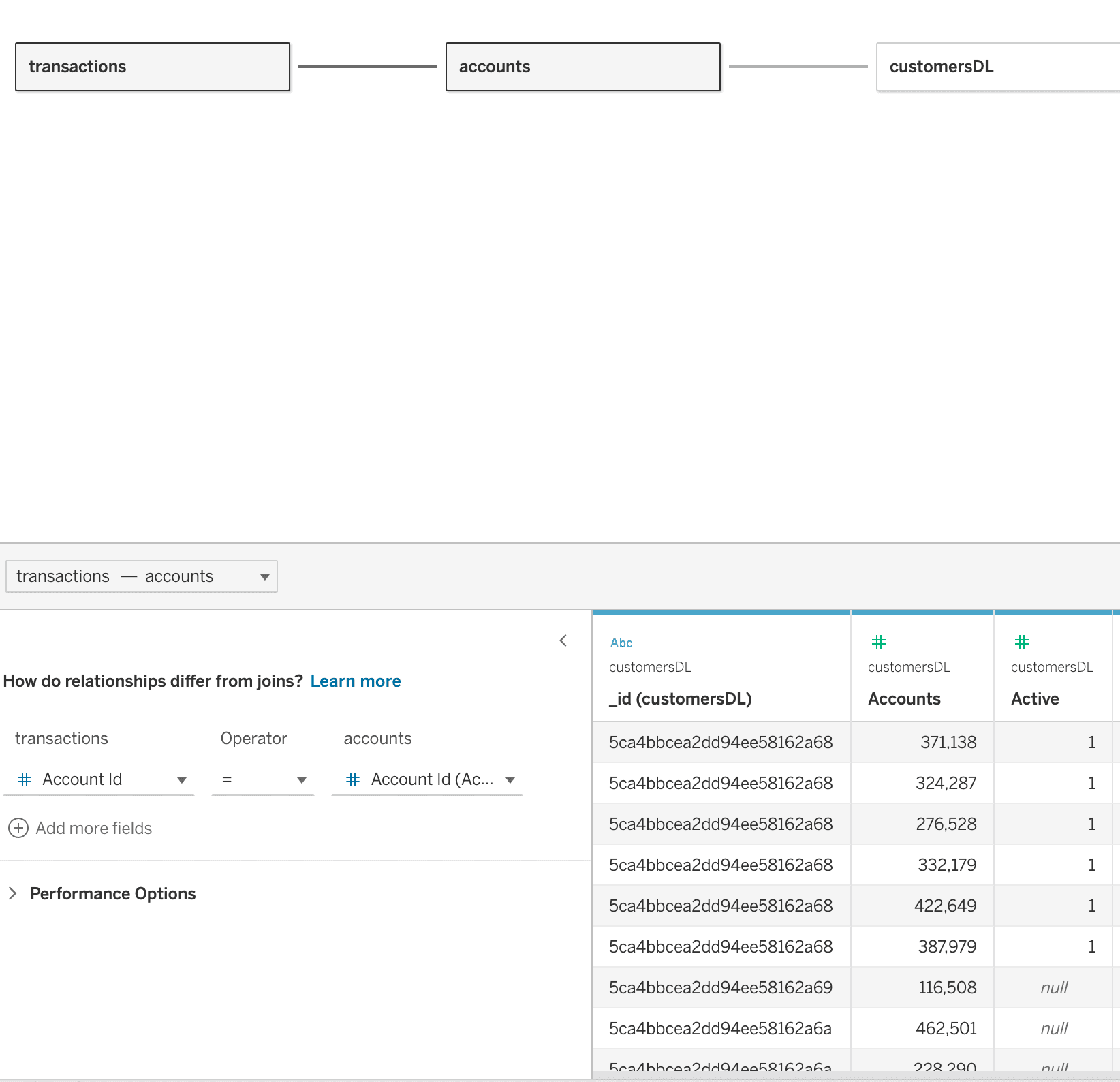
In my case, I connected
Transactions => Accounts based on the Account Id field, and accounts and users based on the Account Id to Accounts field.
In this view, we will see a unified table for all accounts with usernames and their transactions start quarter.
MongoDB has all the tools to read, transform, and analyse your documents for almost any use-case.
Whether your data is in an Atlas operational cluster, in a service, or on cold storage like cloud object storage, Atlas Data Lake will provide you with the ability to join the data in real time. With the option to use powerful join SQL syntax and SQL-based BI tools like Tableau, you can get value out of the data in no time.
Try Atlas Data Lake with your BI tools and SQL today.
Rate this article