Integrating MongoDB with Amazon Managed Streaming for Apache Kafka (MSK)


Igor Alekseev, Robert Walters7 min read • Published May 06, 2022 • Updated Jun 12, 2023




Rate this tutorial


Amazon Managed Streaming for Apache Kafka (MSK) is a fully managed, highly available Apache Kafka service. MSK makes it easy to ingest and process streaming data in real time and leverage that data easily within the AWS ecosystem. By being able to quickly stand up a Kafka solution, you spend less time managing infrastructure and more time solving your business problems, dramatically increasing productivity. MSK also supports integration of data sources such as MongoDB via the AWS MSK Connect (Connect) service. This Connect service works with the MongoDB Connector for Apache Kafka, enabling you to easily integrate MongoDB data.
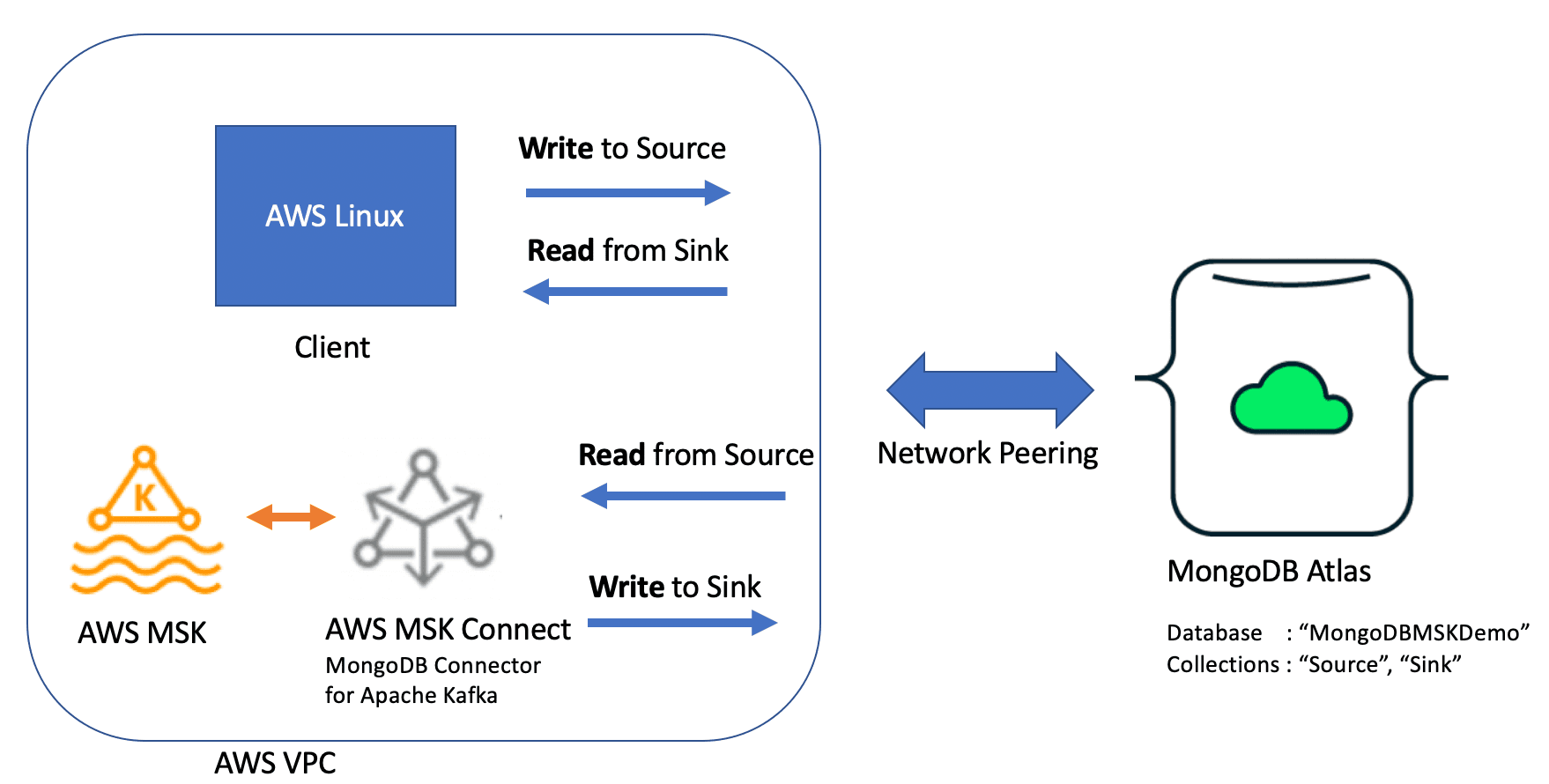
In this blog post, we will walk through how to set up MSK, configure the MongoDB Connector for Apache Kafka, and create a secured VPC Peered connection with MSK and a MongoDB Atlas cluster. The high-level process is as follows:
- Configure Amazon Managed Streaming for Apache Kafka
- Configure EC2 client
- Configure a MongoDB Atlas Cluster
- Configure Atlas Private Link including VPC and subnet of the MSK
- Configure plugin in MSK for MongoDB Connector
- Create topic on MSK Cluster
- Install MongoSH command line tool on client
- Configure MongoDB Connector as a source or sink
In this example, we will have two collections in the same MongoDB cluster—the “source” and the “sink.” We will insert sample data into the source collection from the client, and this data will be consumed by MSK via the MongoDB Connector for Apache Kafka running as an MSK connector. As data arrives in the MSK topic, another instance of the MongoDB Connector for Apache Kafka will write the data to the MongoDB Atlas cluster “sink” collection. To align with best practices for secure configuration, we will set up an AWS Network Peered connection between the MongoDB Atlas cluster and the VPC containing MSK and the client EC2 instance.
To create an Amazon MSK cluster using the AWS Management Console, sign in to the AWS Management Console, and open the Amazon MSK console.
- Choose Create cluster and select Quick create.
For Cluster name, enter MongoDBMSKCluster.
For Apache Kafka version, select one that is 2.6.2 or above.
For broker type, select kafla.t3.small.
From the table under All cluster settings, copy the values of the following settings and save them because you will need them later in this blog:
- VPC
- Subnets
- Security groups associated with VPC

- Choose “Create cluster.”
Next, let's configure an EC2 instance to create a topic. This is where the MongoDB Atlas source collection will write to. This client can also be used to query the MSK topic and monitor the flow of messages from the source to the sink.
- Choose Launch instances.
- Choose Select to create an instance of Amazon Linux 2 AMI (HVM) - Kernel 5.10, SSD Volume Type.
- Choose the t2.micro instance type by selecting the check box.
- Choose Next: Configure Instance Details.
- Navigate to the Network list and choose the VPC whose ID you saved in the previous step.
- Go to Auto-assign Public IP list and choose Enable.
- In the menu near the top, select Add Tags.
- Enter Name for the Key and MongoDBMSKCluster for the Value.
- Choose Review and Launch, and then click Launch.
- Choose Create a new key pair, enter MongoDBMSKKeyPair for Key pair name, and then choose Download Key Pair. Alternatively, you can use an existing key pair if you prefer.
- Start the new instance by pressing Launch Instances.
Next, we will need to configure the networking to allow connectivity between the client instance and the MSK cluster.
- Select View Instances. Then, in the Security Groups column, choose the security group that is associated with the MSKTutorialClient instance.
- Copy the name of the security group, and save it for later.
- In the navigation pane, click on Security Groups. Find the security group whose ID you saved in Step 1 (Create an Amazon MSK Cluster). Choose this row by selecting the check box in the first column.
- In the Inbound Rules tab, choose Edit inbound rules.
- Choose Add rule.
- In the new rule, choose All traffic in the Type column. In the second field in the Source column, select the security group of the client machine. This is the group whose name you saved earlier in this step.
- Click Save rules.
The cluster's security group can now accept traffic that comes from the client machine's security group.
To create a MongoDB Atlas Cluster, follow the Getting Started with Atlas tutorial. Note that in this blog, you will need to create an M30 Atlas cluster or above—as VPC peering is not available for M0, M2, and M5 clusters.
Once the cluster is created, configure an AWS private endpoint in the Atlas Network Access UI supplying the same subnets and VPC.
- Click on Network Access.
- Click on Private Endpoint, and then the Add Private Endpoint button.
- Fill out the VPC and subnet IDs from the previous section.
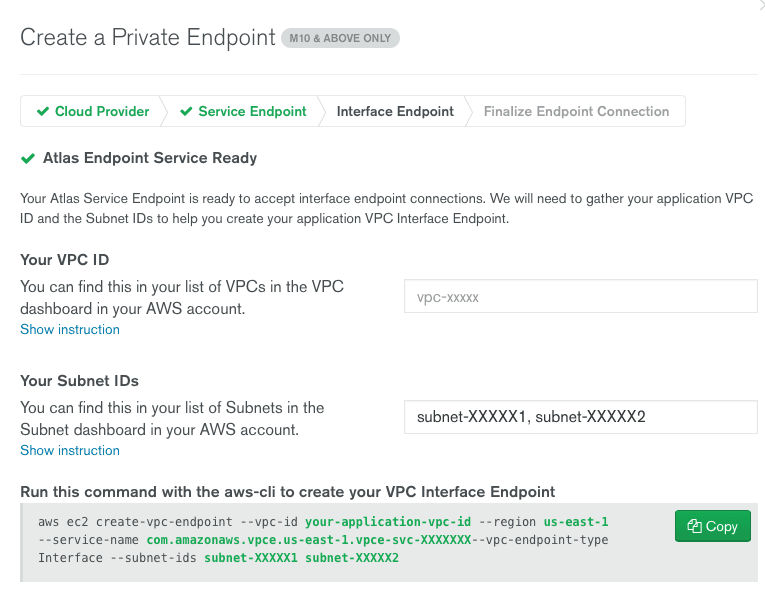
- SSH into the client machine created earlier and issue the following command in the Atlas portal: **aws ec2 create-vpc-endpoint **
- Note that you may have to first configure the AWS CLI command using aws configure before you can create the VPC through this tool. See Configuration Basics for more information.
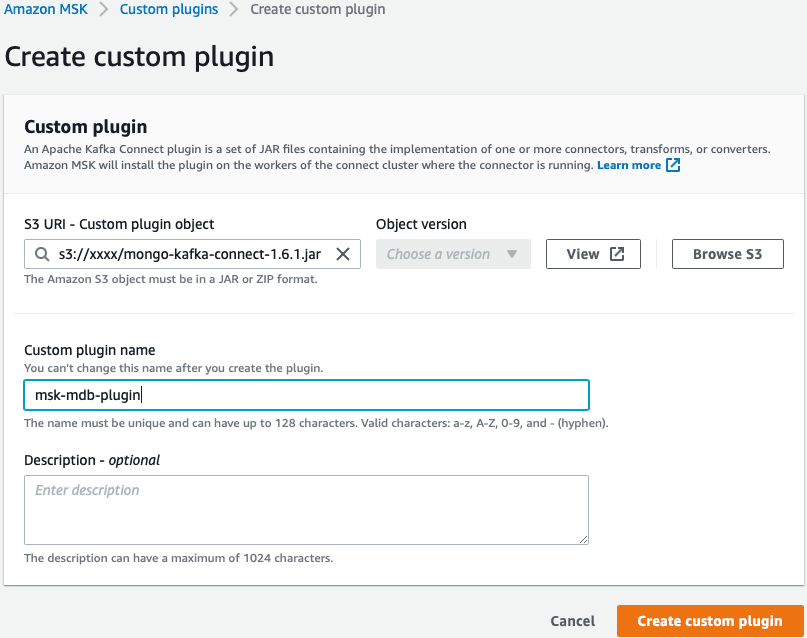
Next, we need to create a custom plugin for MSK. This custom plugin will be the MongoDB Connector for Apache Kafka. For reference, note that the connector will need to be uploaded to an S3 repository before you can create the plugin. You can download the MongoDB Connector for Apache Kafka from Confluent Hub.
- Select “Create custom plugin” from the Custom Plugins menu within MSK.
- Fill out the custom plugin form, including the S3 location of the downloaded connector, and click “Create custom plugin.”
When we start reading the data from MongoDB, we also need to create a topic in MSK to accept the data. On the client EC2 instance, let’s install Apache Kafka, which includes some basic tools.
To begin, run the following command to install Java:
sudo yum install java-1.8.0
Next, run the command below to download Apache Kafka.
Building off the previous step, run this command in the directory where you downloaded the TAR file:
tar -xzf kafka_2.12-2.6.2.tgz
The distribution of Kafka includes a bin folder with tools that can be used to manage topics. Go to the kafka_2.12-2.6.2 directory.
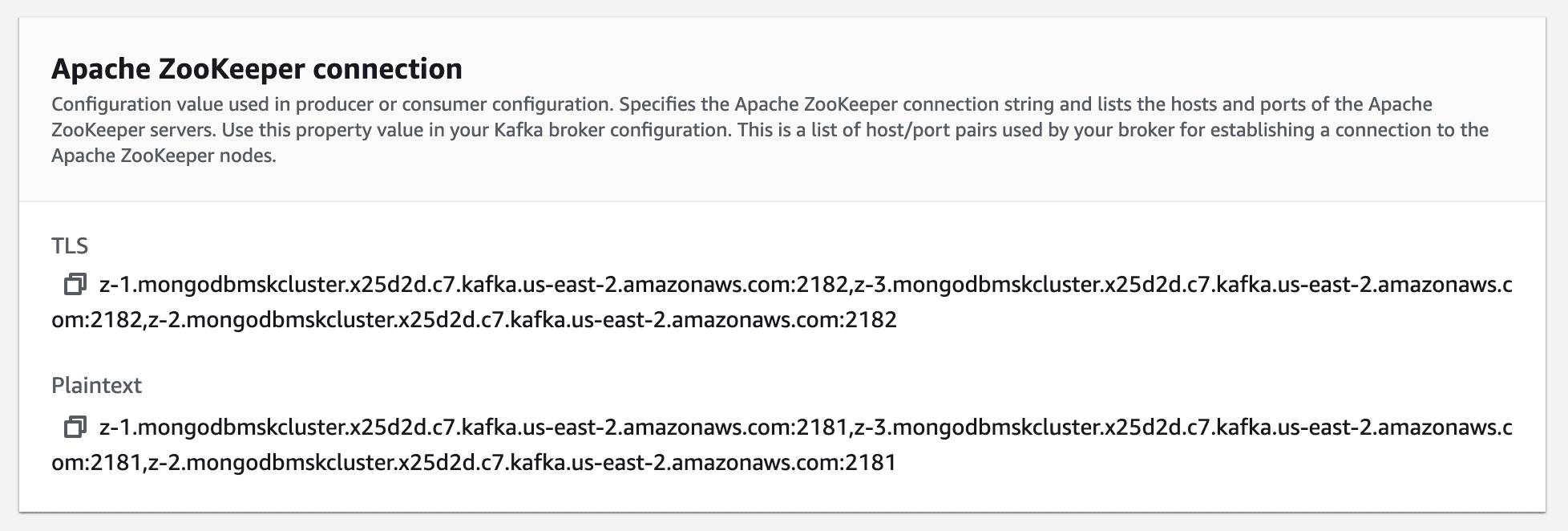
To create the topic that will be used to write MongoDB events, issue this command:
bin/kafka-topics.sh --create --zookeeper (INSERT YOUR ZOOKEEPER INFO HERE)--replication-factor 1 --partitions 1 --topic MongoDBMSKDemo.SourceAlso, remember that you can copy the Zookeeper server endpoint from the “View Client Information” page on your MSK Cluster. In this example, we are using plaintext.
Once the plugin is created, we can create an instance of the MongoDB connector by selecting “Create connector” from the Connectors menu.

- Select the MongoDB plug in and click “Next.”
- Fill out the form as follows:
Conector name: MongoDB Source Connector
Cluster Type: MSK Connector
Select the MSK cluster that was created previously, and select “None” under the authentication drop down menu.
Enter your connector configuration (shown below) in the configuration settings text area.
connector.class=com.mongodb.kafka.connect.MongoSourceConnector
database=MongoDBMSKDemo
collection=Source
tasks.max=1
connection.uri=(MONGODB CONNECTION STRING HERE)
value.converter=org.apache.kafka.connect.storage.StringConverter
key.converter=org.apache.kafka.connect.storage.StringConverterNote: You can find your Atlas connection string by clicking on the Connect button on your Atlas cluster. Select “Private Endpoint” if you have already configured the Private Endpoint above, then press “Choose a connection method.” Next, select “Connect your application” and copy the mongodb+srv connection string.
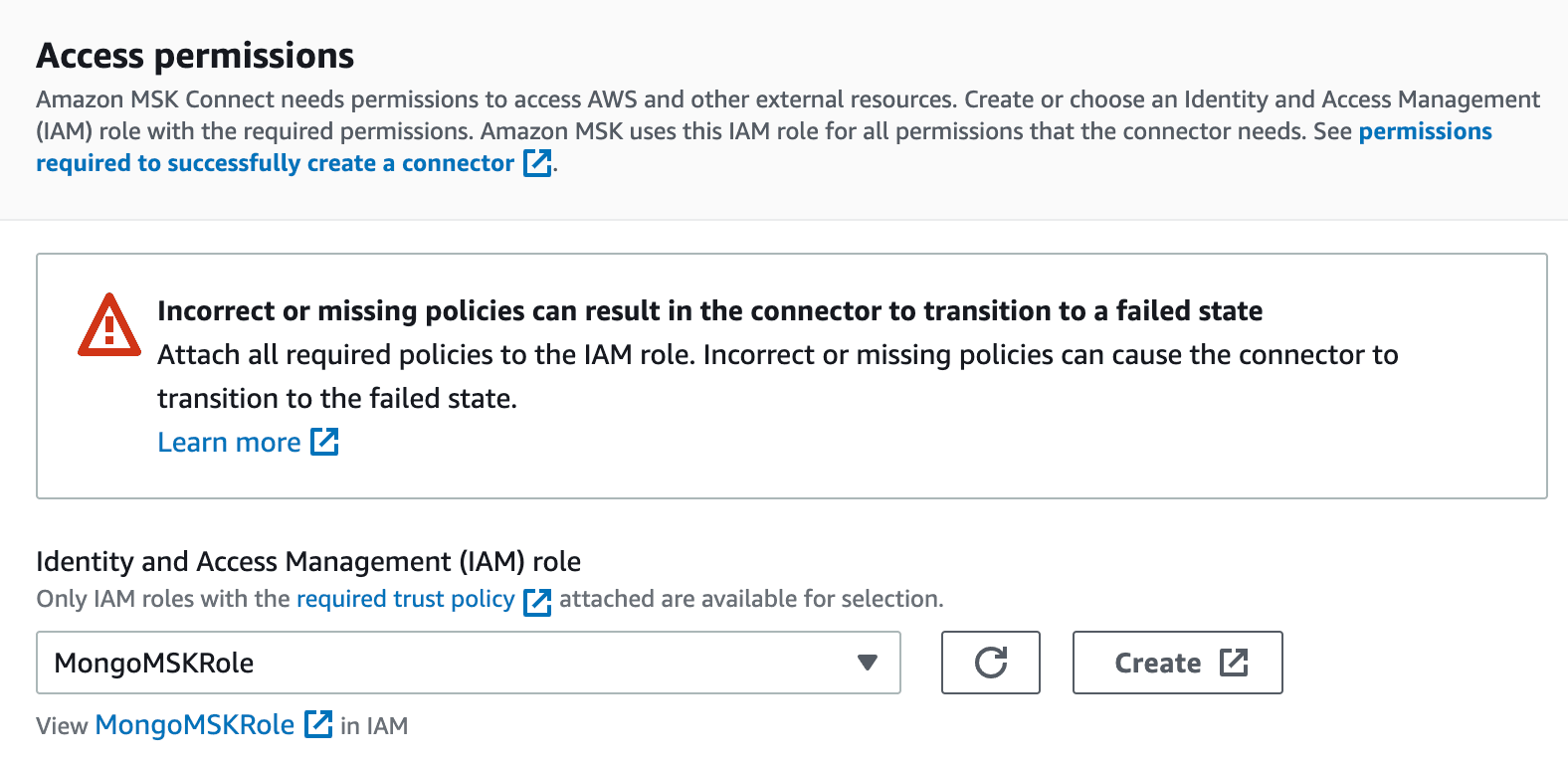
In the “Access Permissions” section, you will need to create an IAM role with the required trust policy.
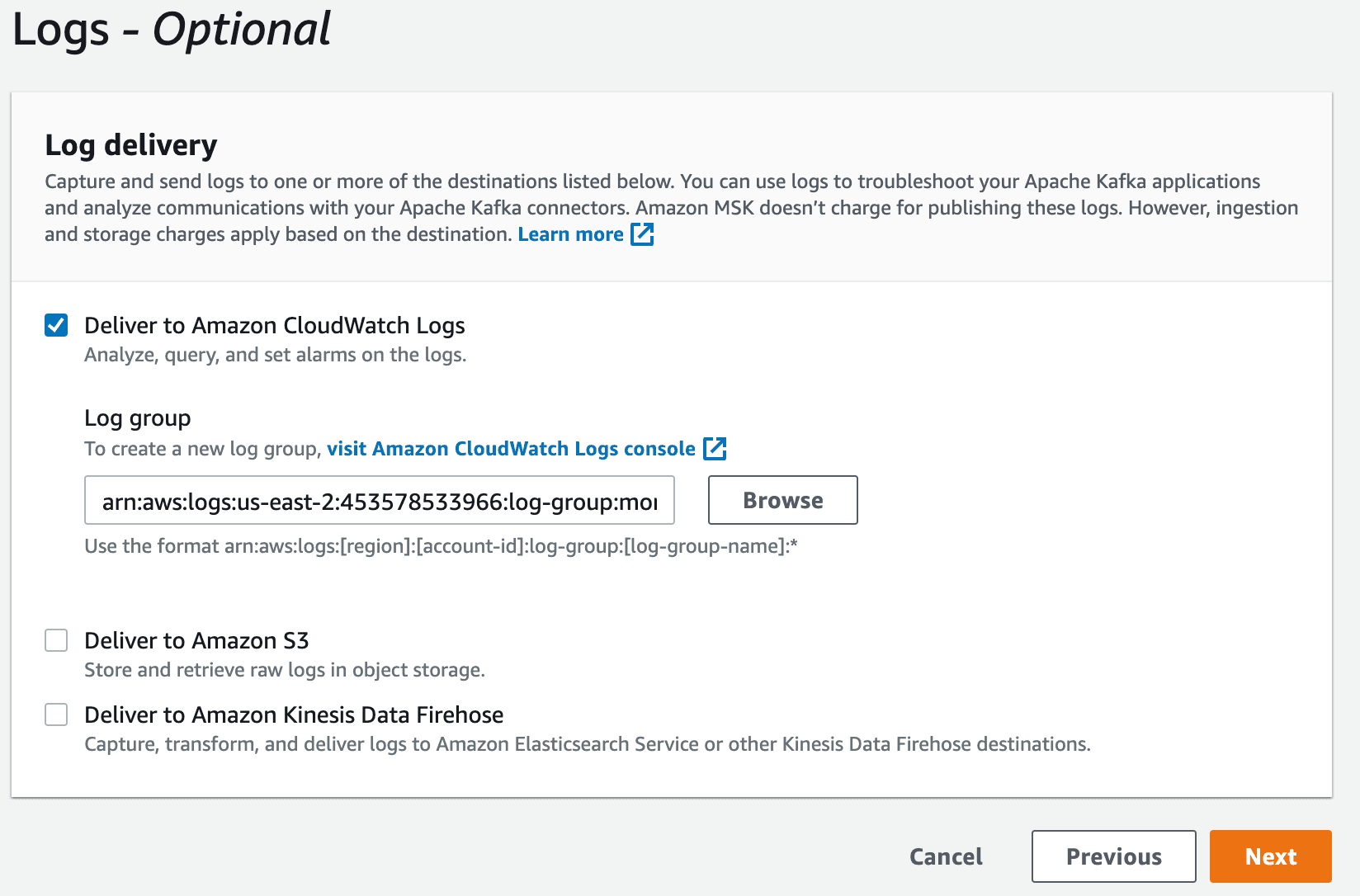
Once this is done, click “Next.” The last section will offer you the ability to use logs—which we highly recommend, as it will simplify the troubleshooting process.
Now that we have the source connector up and running, let’s configure a sink connector to complete the round trip. Create another instance of the MongoDB connector by selecting “Create connector” from the Connectors menu.
Select the same plugin that was created previously, and fill out the form as follows:
Connector name: MongoDB Sink Connector
Cluster type: MSK Connector
Select the MSK cluster that was created previously and select “None” under the authentication drop down menu.
Enter your connector configuration (shown below) in the Configuration Settings text area.
connector.class=com.mongodb.kafka.connect.MongoSinkConnector
database=MongoDBMSKDemo
collection=Sink
tasks.max=1
topics=MongoDBMSKDemo.Source
connection.uri=(MongoDB Atlas Connection String Gos Here)
value.converter=org.apache.kafka.connect.storage.StringConverter
key.converter=org.apache.kafka.connect.storage.StringConverterIn the Access Permissions section, select the IAM role created earlier that has the required trust policy. As with the previous connector, be sure to leverage a log service like CloudWatch.
Once the connector is successfully configured, we can test the round trip by writing to the Source collection and seeing the same data in the Sink collection.
We can insert data in one of two ways: either through the intuitive Atlas UI, or with the new MongoSH (mongoshell) command line tool. Using MongoSH, you can interact directly with a MongoDB cluster to test queries, perform ad hoc database operations, and more.
For your reference, we’ve added a section on how to use the mongoshell on your client EC2 instance below.
On the client EC2 instance, create a /etc/yum.repos.d/mongodb-org-5.0.repo file by typing:
sudo nano /etc/yum.repos.d/mongodb-org-5.0.repoPaste in the following:
[mongodb-org-5.0]
name=MongoDB Repository
baseurl=https://repo.mongodb.org/yum/amazon/2/mongodb-org/5.0/x86_64/
gpgcheck=1
enabled=1
gpgkey=[https://www.mongodb.org/static/pgp/server-5.0.asc](https://www.mongodb.org/static/pgp/server-5.0.asc)Next, install the MongoSH shell with this command:
sudo yum install -y mongodb-mongoshUse the template below to connect to your MongoDB cluster via mongoshell:
mongosh “ (paste in your Atlas connection string here) “Once connected, type:
Use MongoDBMSKDemo
db.Source.insertOne({“Testing”:123})To check the data on the sink collection, use this command:
db.Sink.find({})If you run into any issues, be sure to check the log files. In this example, we used CloudWatch to read the events that were generated from MSK and the MongoDB Connector for Apache Kafka.
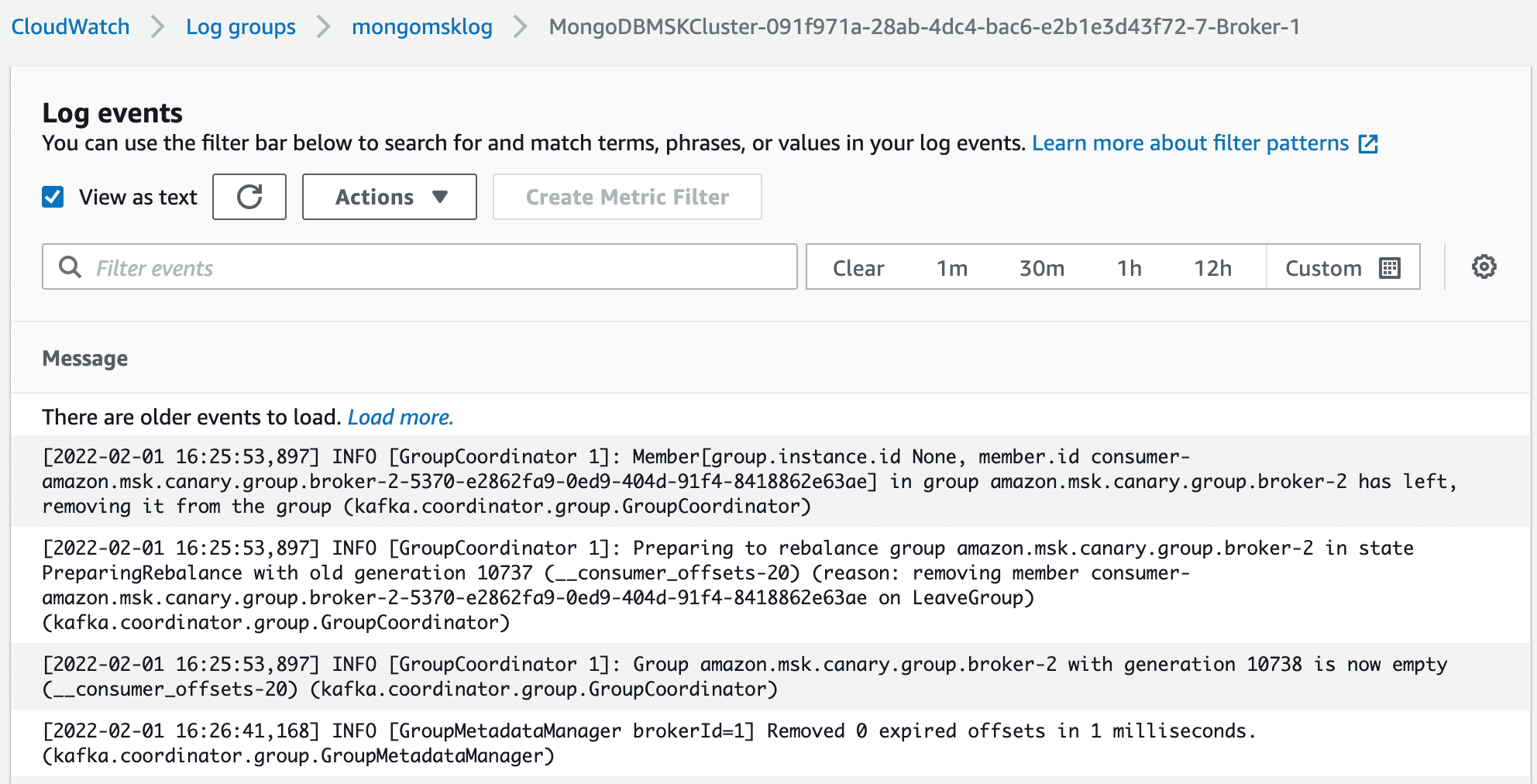
Amazon Managed Streaming for Apache Kafka (MSK) is a fully managed, secure, and highly available Apache Kafka service that makes it easy to ingest and process streaming data in real time. MSK allows you to import Kafka connectors such as the MongoDB Connector for Apache Kafka. These connectors make working with data sources seamless within MSK. In this article, you learned how to set up MSK, MSK Connect, and the MongoDB Connector for Apache Kafka. You also learned how to set up a MongoDB Atlas cluster and configure it to use AWS network peering. To continue your learning, check out the following resources: