TL;DR – Introducing voyage-code-3, our next-generation embedding model optimized for code retrieval. It outperforms OpenAI-v3-large and CodeSage-large by an average of 13.80% and 16.81% on a suite of 32 code retrieval datasets, respectively. By supporting smaller dimensions with Matryoshka learning and quantized formats like int8 and binary, voyage-code-3 can also dramatically reduce storage and search costs with minimal impact on retrieval quality.
Note to readers: voyage-code-3 is available through the Voyage AI APIs directly. For access, sign up for Voyage AI.
Since its launch in Jan, voyage-code-2 has been the most heavily used model with exponentially increasing adoption by code assistants and agents startups for their code retrieval. Today, we’re thrilled to announce voyage-code-3, which:
Outperforms OpenAI-v3-large and CodeSage-large by an average of 13.80% and 16.81% on a suite of 32 code retrieval datasets, respectively.
Supports embeddings of 2048, 1024, 512, and 256 dimensions.
Offers multiple embedding quantization, including float (32-bit floating point), int8 (8-bit signed integer), uint8 (8-bit unsigned integer), binary (bit-packed int8), and ubinary (bit-packed uint8).
Supports a 32K-token context length, compared to OpenAI (8K) and CodeSage large (1K).
Matryoshka embeddings and quantization
Storage and search costs in vector-based search can become significant for large corpora, such as in code retrieval with massive repositories. The costs scale linearly in the embedding dimensionality and precision (i.e., the number of bits used to encode each number). voyage-code-3 supports much lower dimensional embeddings and binary and int8 quantization to dramatically lower the costs without losing much retrieval quality. These are enabled by Matryoshka learning and quantization-aware training.
Matryoshka embeddings: Matryoshka learning creates embeddings with a nested family of embeddings with various lengths within a single vector. Concretely, for each of k in {256, 512, and 1024}, the first k entries of the 2048-dimensional embedding also form a valid k-dimensional embedding that is shorter with a slight loss of retrieval quality. Thus, the users can vectorize the documents into a long 2048-dimensional vector in advance and then later have the flexibility to use a shorter version of the embedding (by taking the first k entries) without re-invoking the embedding model.
Quantization: Quantized embeddings have lower precision, represented with 8 bits or 1 bit per dimension, reducing 4x or 32x storage costs compared to 32-bit floats, respectively. voyage-code-3 can return the embeddings with lower precision with various data types, int8 (8-bit signed integer), uint8 (8-bit unsigned integer), binary (bit-packed int8), and ubinary (bit-packed uint8). Most vector databases support storing and searching with quantized embeddings directly, including Milvus, Qdrant, Weaviate, Elasticsearch, and Vespa AI.
Storage cost vs retrieval quality tradeoff: Quantization and shorter embeddings inevitably come with a reduced retrieval quality. Voyage focuses intently on this, striving to minimize the quality loss as much as possible. The following graph plots retrieval quality versus relative storage cost — showing a limited reduction of quality up to binary 1024-dimensional embeddings compared to the float32 2048-dimensional embeddings.
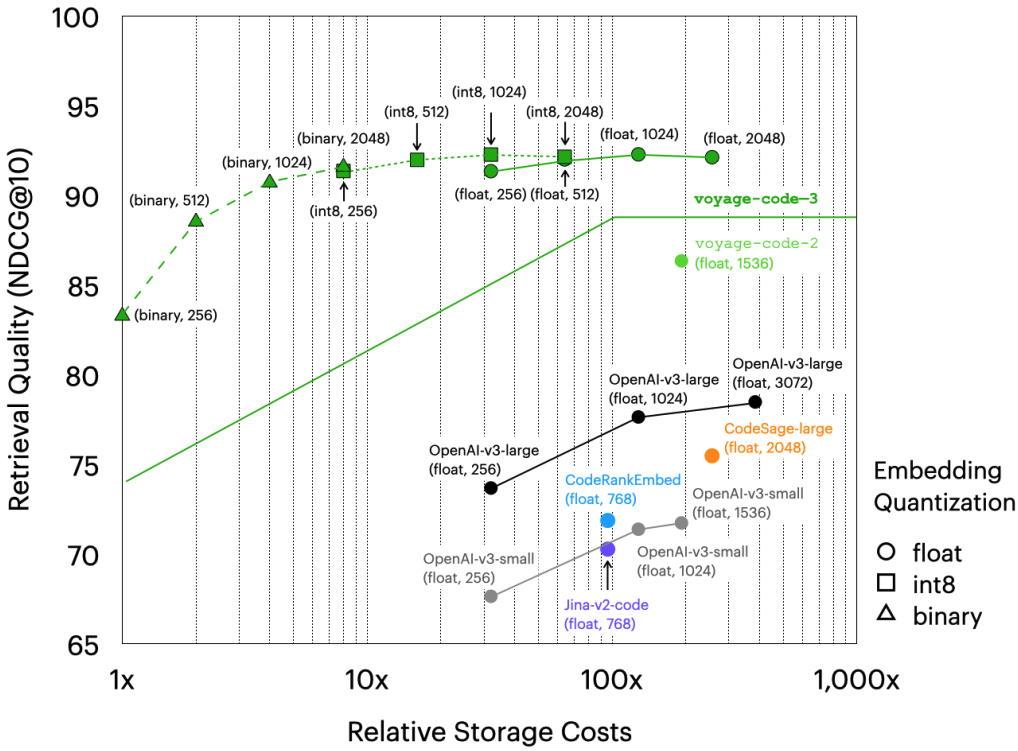
All green data points above the green line represent voyage-code-3, and those below are uniquely colored per model and explicitly labeled with quantization and dimension. Lines connecting data points represent the same model and data type but at different embedding dimensions. The evaluation results used to generate this plot are available in this spreadsheet.
Optimized for code retrieval
Code retrieval presents unique challenges compared to general text retrieval due to the need for algorithmic reasoning and the nuanced syntax rules such as keywords, control structures, nesting, and formatting. These challenges are further complicated by several retrieval subtasks, including text-to-code (e.g., retrieve code snippets using natural language queries), code-to-code (e.g., identify semantically similar code snippets), and docstring-to-code (e.g., retrieve code snippets using function docstring queries).
Curated, massive code training data: We curated a larger, more diverse, high-quality code corpus for training voyage-code-3 than voyage-code-2. First, we assembled a broad corpus with trillions of tokens comprising text, code, and mathematical content with a carefully tuned code-to-text ratio. Next, we developed a comprehensive dataset with positive pairs for contrastive learning based on public GitHub repositories, containing docstring-code and code-code pairs across 300+ programming languages. This dataset was combined with the general text pair dataset used to train our leading general-purpose voyage-3 model. Finally, we collected additional real-world query-code pairs, covering a wide range of tasks in code assistant use cases, to ensure robust coverage of real-world scenarios.
Evaluation: We evaluated voyage-code-3 using an enhanced suite of evaluation datasets designed to address the shortcomings of existing benchmarks and deliver practical, robust results. Existing datasets can suffer from noisy labels, overly simplistic tasks, and data contamination risks, making them ill-suited for real-world applications. For instance, the original CoSQA dataset was found to have 51% of its queries paired with mismatched code. Our evaluation incorporated diverse tasks, such as text-to-code and code-to-code, repurposed question-answer datasets for retrieval, and introduced complex, real-world repositories and scenarios that challenge embedding models to achieve deeper understanding. For a deeper dive into code retrieval evaluation, check out our previous blog post.
Evaluation details
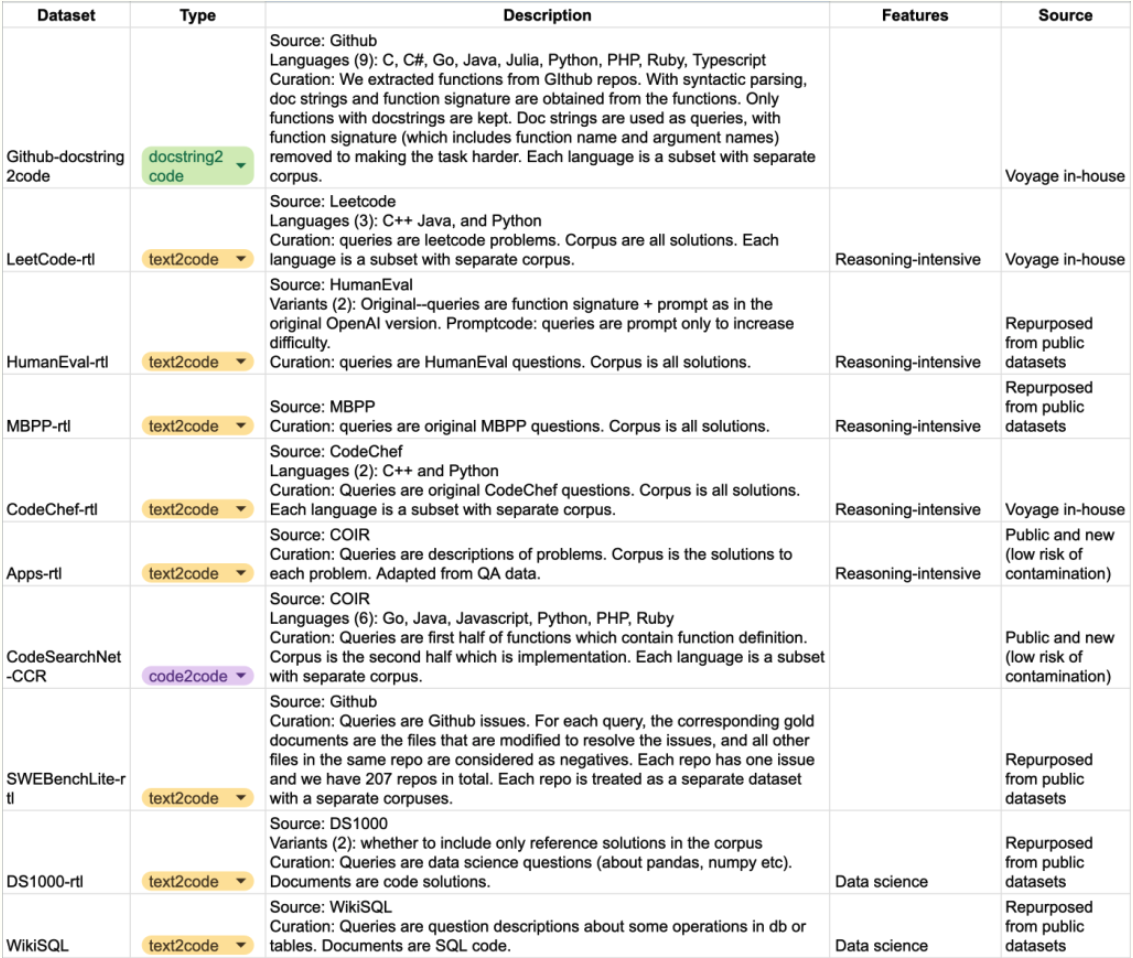
Datasets: We evaluate voyage-code-3 across 32 datasets spanning five categories that cover various code retrieval tasks, real-world use cases, and challenging code scenarios. These datasets are discussed in length in our code retrieval evaluation blog post. The table below summarizes the key datasets.
Models: We evaluate voyage-code-3 alongside several general-purpose and code-specific alternatives, including: OpenAI-v3-large (text-embedding-3-large), OpenAI-v3-small (text-embedding-3-small), CodeSage-large, CodeRankEmbed (cornstack/CodeRankEmbed), Jina-v2-code (jina-embeddings-v2-base-code), voyage-code-2, voyage-3, and voyage-3-lite.
Results
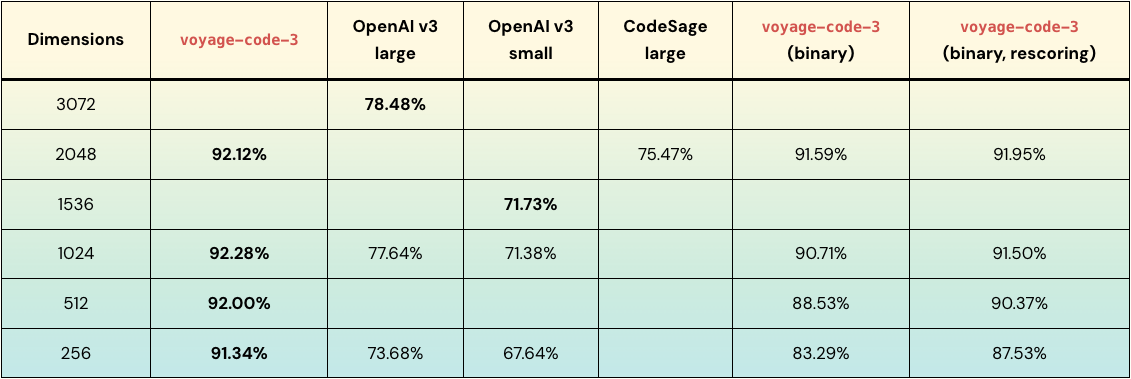
The table below summarizes the key results from the code retrieval quality versus relative storage costs plot above. voyage-code-3 outperforms OpenAI-v3-large on average by:
14.64% and 17.66% at 1024 and 256 dimensions, respectively
13.80% at 1/3 the storage costs (1024 vs 3072 dimensions)
4.81% at 1/384 the storage costs (binary 256 vs float 3072 dimensions)
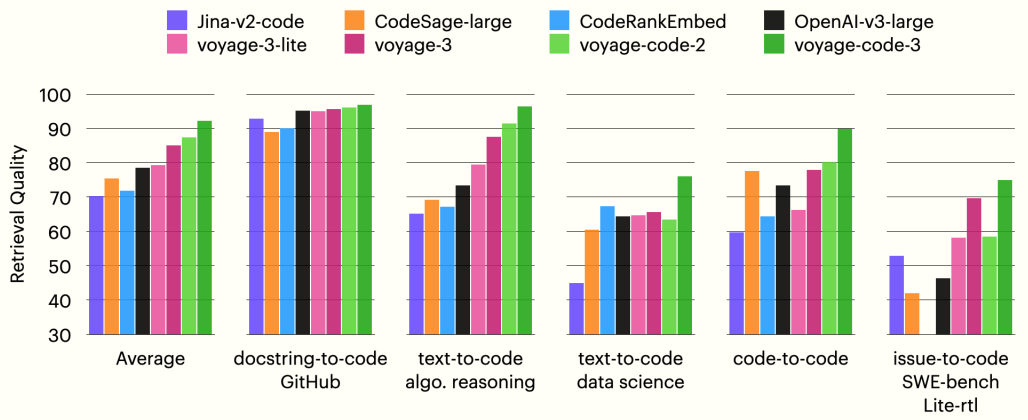
The bar charts below show the average retrieval quality for each group of datasets (see spreadsheet for a full list of datasets and the grouping). voyage-code-3 outperforms all other models in every group, exceeding OpenAI-v3-large on average by 16.30%.
Binary rescoring: Finally, users sometimes first retrieve a decent number of (e.g., 100 in our evaluation) documents with binary embeddings and then rescore the retrieved documents with full-precision embeddings. For voyage-code-3, as shown in the table, binary rescoring yields up to 4.25% improvement in retrieval quality when applied on top of standard binary retrieval.
All the evaluation results are available in this spreadsheet.
Try voyage-code-3!
voyage-code-3 is available today! The first 200 million tokens are free. To get started, head over to our docs to learn more. If you’re also interested in fine-tuned embedding models, we’d love to hear from you—please email us at contact@voyageai.com.