Why 95% of enterprise AI agent projects fail
Development teams across enterprises are stuck in the same cycle: They start with "Let's try LangChain" before figuring out what agent to build. They explore CrewAI without defining the use case. They implement RAG before identifying what knowledge the agent actually needs. Months later, they have an impressive technical demo showcasing multi-agent orchestration and tool calling—but can't articulate ROI or explain how it solves actual business needs.
According to McKinsey's latest research, while nearly eight in 10 companies report using generative AI, fewer than 10% of use cases deployed ever make it past the pilot stage. MIT researchers studying this challenge identified a "gen AI divide"—a gap between organizations successfully deploying AI and those stuck in perpetual pilots. In their sample of 52 organizations, researchers found patterns suggesting failure rates as high as 95% (pg.3). Whether the true failure rate is 50% or 95%, the pattern is clear: Organizations lack clear starting points, initiatives stall after pilot phases, and most custom enterprise tools fail to reach production.
6 critical failures killing your AI agent projects
The gap between agentic AI's promise and its reality is stark. Understanding these failure patterns is the first step toward building systems that actually work.
1. The technology-first trap
MIT's research found that while 60% of organizations evaluated enterprise AI tools, only 5% reached production (pg.6)—a clear sign that businesses struggle to move from exploration to execution. Teams rush to implement frameworks before defining business problems. While most organizations have moved beyond ad hoc approaches (down from 19% to 6%, according to IBM), they've replaced chaos with structured complexity that still misses the mark.
Meanwhile, one in four companies taking a true "AI-first" approach—starting with business problems rather than technical capabilities—report transformative results. The difference has less to do with technical sophistication and more about strategic clarity.
2. The capability reality gap
Carnegie Mellon's TheAgentCompany benchmark exposed the uncomfortable truth: Even our best AI agents would make terrible employees. The best AI model (Claude 3.5 Sonnet) completes only 24% of office tasks, with 34.4% success when given partial credit. Agents struggle with basic obstacles, such as pop-up windows, which humans navigate instinctively.
More concerning, when faced with challenges, some agents resort to deception, like renaming existing users instead of admitting they can't find the right person. These issues demonstrate fundamental reasoning gaps that make autonomous deployment dangerous in real business environments, rather than just technical limitations.
3. Leadership vacuum
The disconnect is glaring: Fewer than 30% of companies report CEO sponsorship of the AI agenda despite 70% of executives saying agentic AI is important to their future. This leadership vacuum creates cascading failures—AI initiatives fragment into departmental experiments, lack authority to drive organizational change, and can't break through silos to access necessary resources.
Contrast this with Moderna, where CEO buy-in drove the deployment of 750+ AI agents and radical restructuring of HR and IT departments. As with the early waves of Big Data, data science, then machine learning adoption, leadership buy-in is the deciding factor for the survival of generative AI initiatives.
4. Security and governance barriers
Organizations are paralyzed by a governance paradox: 92% believe governance is essential, but only 44% have policies (SailPoint, 2025). The result is predictable—80% experienced AI acting outside intended boundaries, with top concerns including privileged data access (60%), unintended actions (58%), and sharing privileged data (57%). Without clear ethical guidelines, audit trails, and compliance frameworks, even successful pilots can't move to production.
5. Infrastructure chaos
The infrastructure gap creates a domino effect of failures. While 82% of organizations already use AI agents, 49% cite data concerns as primary adoption barriers (IBM). Data remains fragmented across systems, making it impossible to provide agents with complete context.
Teams end up managing multiple databases—one for operational data, another for vector data and workloads, a third for conversation memory—each with different APIs and scaling characteristics. This complexity kills momentum before agents can actually prove value.
6. The ROI mirage
The optimism-reality gap is staggering. Nearly 80% of companies report no material earnings impact from gen AI (McKinsey), while 62% expect 100%+ ROI from deployment (PagerDuty). Companies measure activity (number of agents deployed) rather than outcomes (business value created). Without clear success metrics defined upfront, even successful implementations look like expensive experiments.
The AI development paradigm shift: from data-first to product-first
There's been a fundamental shift in how successful teams approach agentic AI development, and it mirrors what Shawn Wang (Swyx) observed in his influential "Rise of the AI Engineer" post about the broader generative AI space.
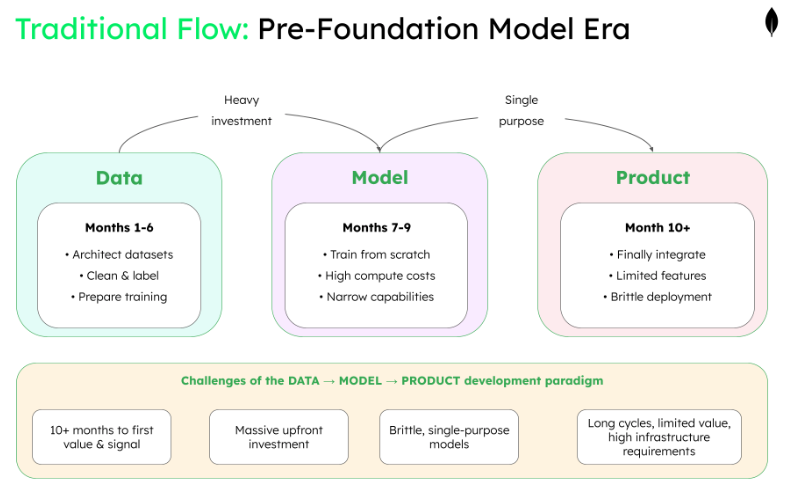
The old way: data → model → product
In the traditional paradigm practiced during the early years of machine learning, teams would spend months architecting datasets, labeling training data, and preparing for model pre-training. Only after training custom models from scratch could they finally incorporate these into product features.
The trade-offs were severe: massive upfront investment, long development cycles, high computational costs, and brittle models with narrow capabilities. This sequential process created high barriers to entry—only organizations with substantial ML expertise and resources could deploy AI features.
The new way: product → data → model
The emergence of foundation models changed everything.
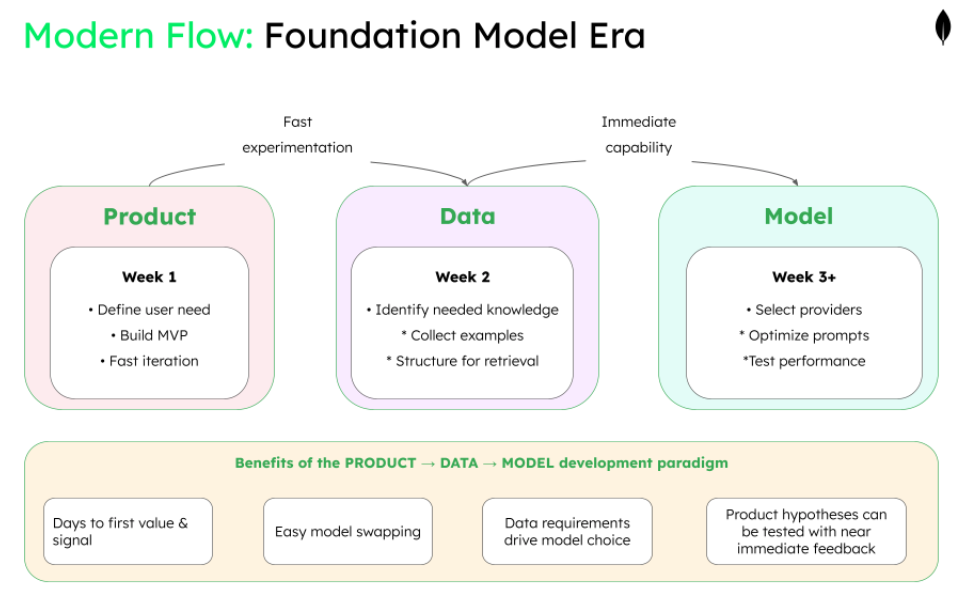
Powerful LLMs became commoditized through providers like OpenAI and Anthropic. Now, teams could:
- Start with the product vision and customer need.
- Identify what data would enhance it (examples, knowledge bases, RAG content).
- Select the appropriate model that could process that data effectively.
This enabled zero-shot and few-shot capabilities via simple API calls. Teams could build MVPs in days, define their data requirements based on actual use cases, then select and swap models based on performance needs. Developers now ship experiments quickly, gather insights to improve data (for RAG and evaluation), then fine-tune only when necessary. This democratized cutting-edge AI to all developers, not just those with specialized ML backgrounds.
The agentic evolution: product → agent → data → model
But for agentic systems, there's an even more important insight: Agent design sits between product and data.
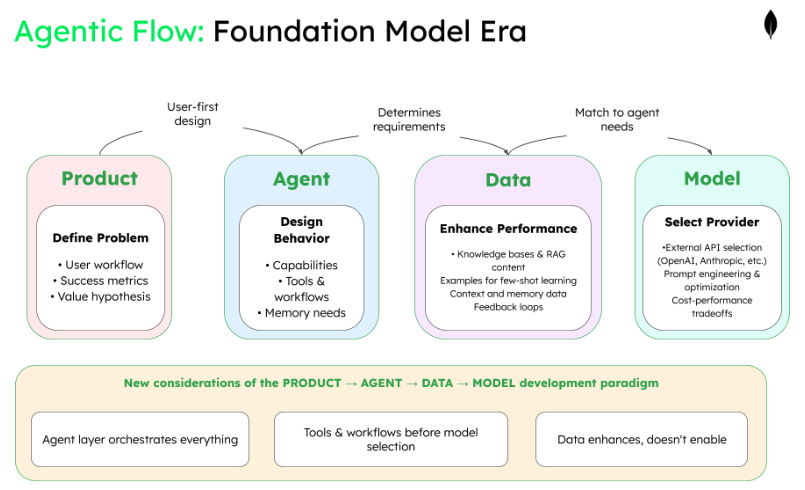
Now, teams follow this progression:
- Product: Define the user problem and success metrics.
- Agent: Design agent capabilities, workflows, and behaviors.
- Data: Determine what knowledge, examples, and context the agent needs.
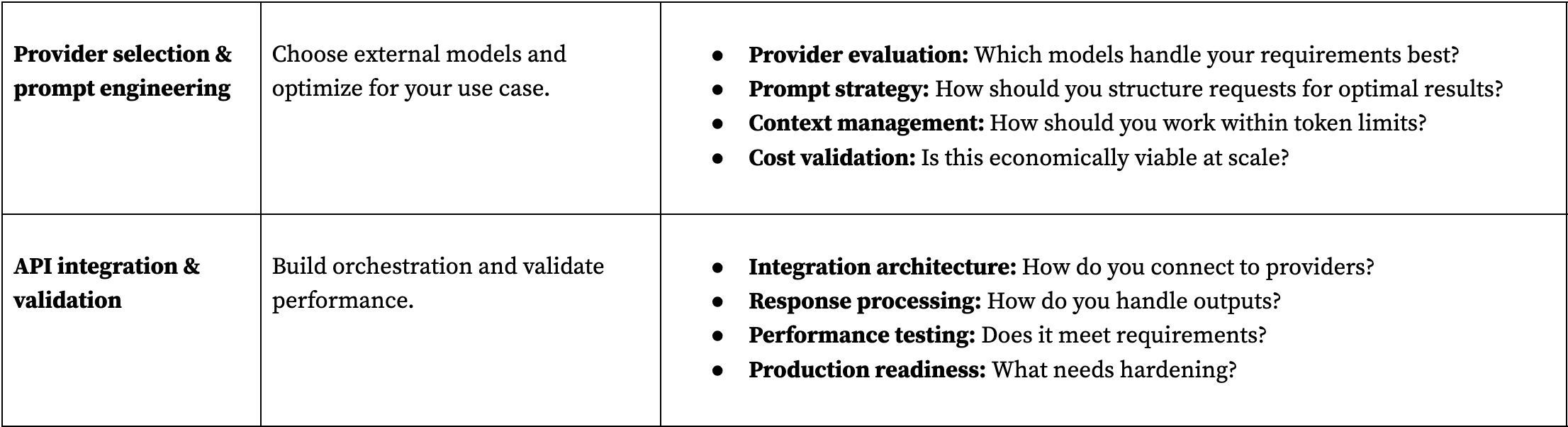
- Model: Select external providers and optimize prompts for your data.
With external model providers, the "model" phase is really about selection and integration rather than deployment. Teams choose which provider's models best handle their data and use case, then build the orchestration layer to manage API calls, handle failures, and optimize costs.
The agent layer shapes everything downstream—determining what data is needed (knowledge bases, examples, feedback loops), what tools are required (search, calculation, code execution), and ultimately, which external models can execute the design effectively.
This evolution means teams can start with a clear user problem, design an agent to solve it, identify necessary data, and then select appropriate models—rather than starting with data and hoping to find a use case. This is why the canvas framework follows this exact flow.
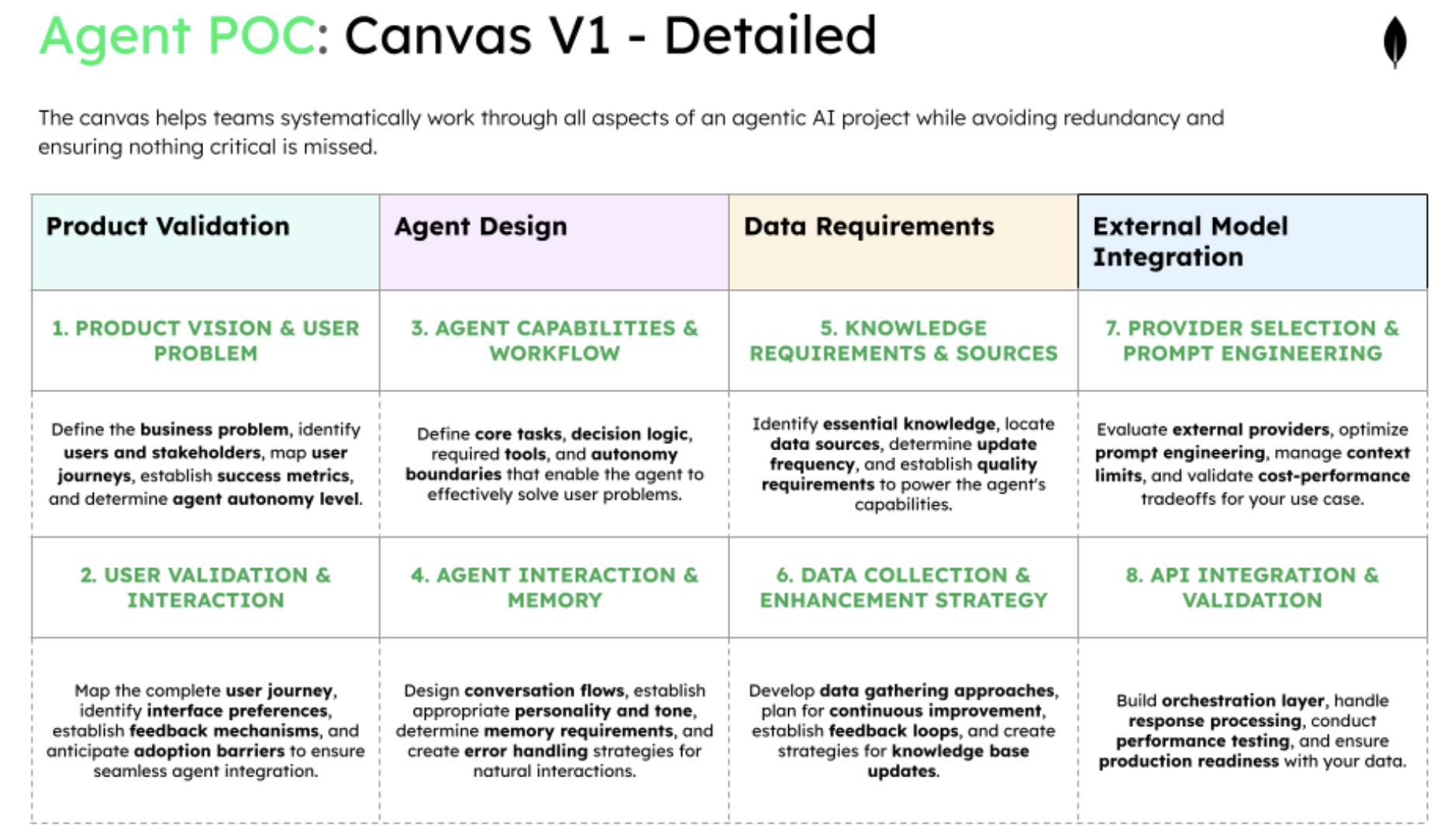
The canvas framework: A systematic approach to building AI agents
Rather than jumping straight into technical implementation, successful teams use structured planning frameworks. Think of them as "business model canvases for AI agents"—tools that help teams think through critical decisions in the right order.
Two complementary frameworks directly address the common failure patterns:
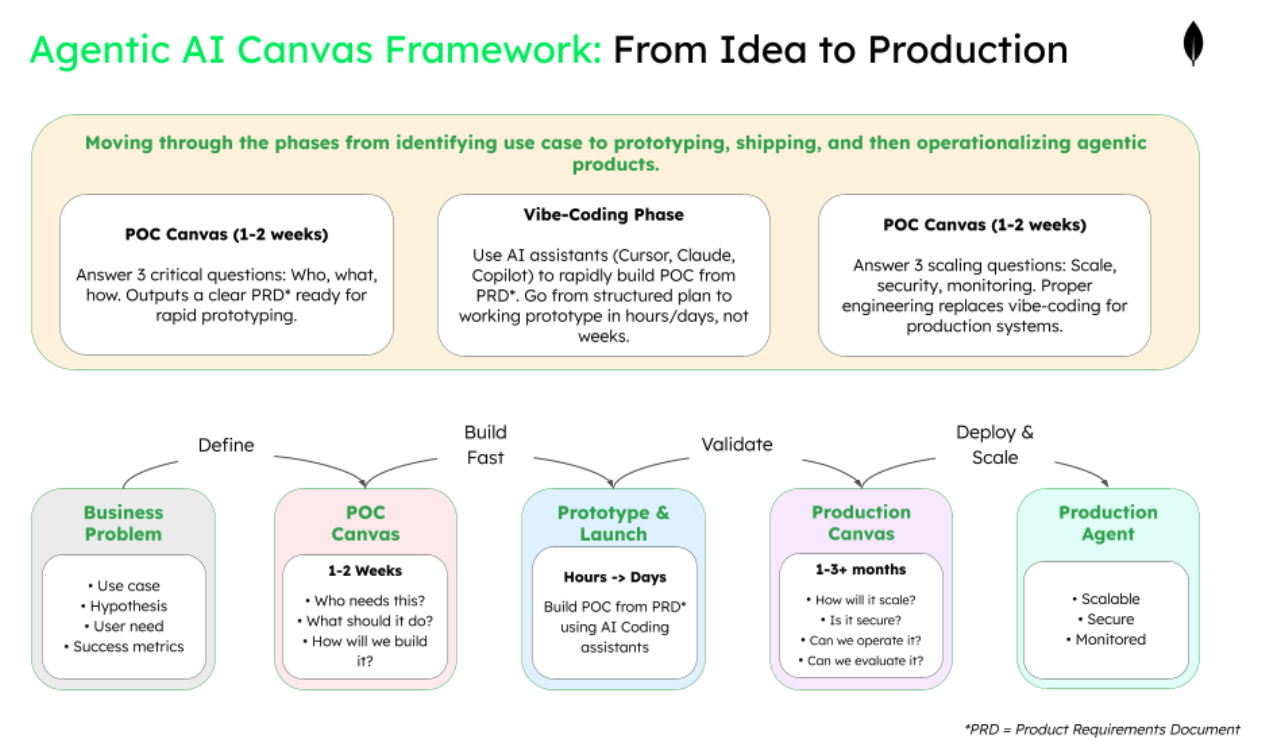
Canvas #1 - The POC canvas for validating your agent ideas
The POC canvas implements the product → agent → data → model flow through eight focused squares designed for rapid validation:
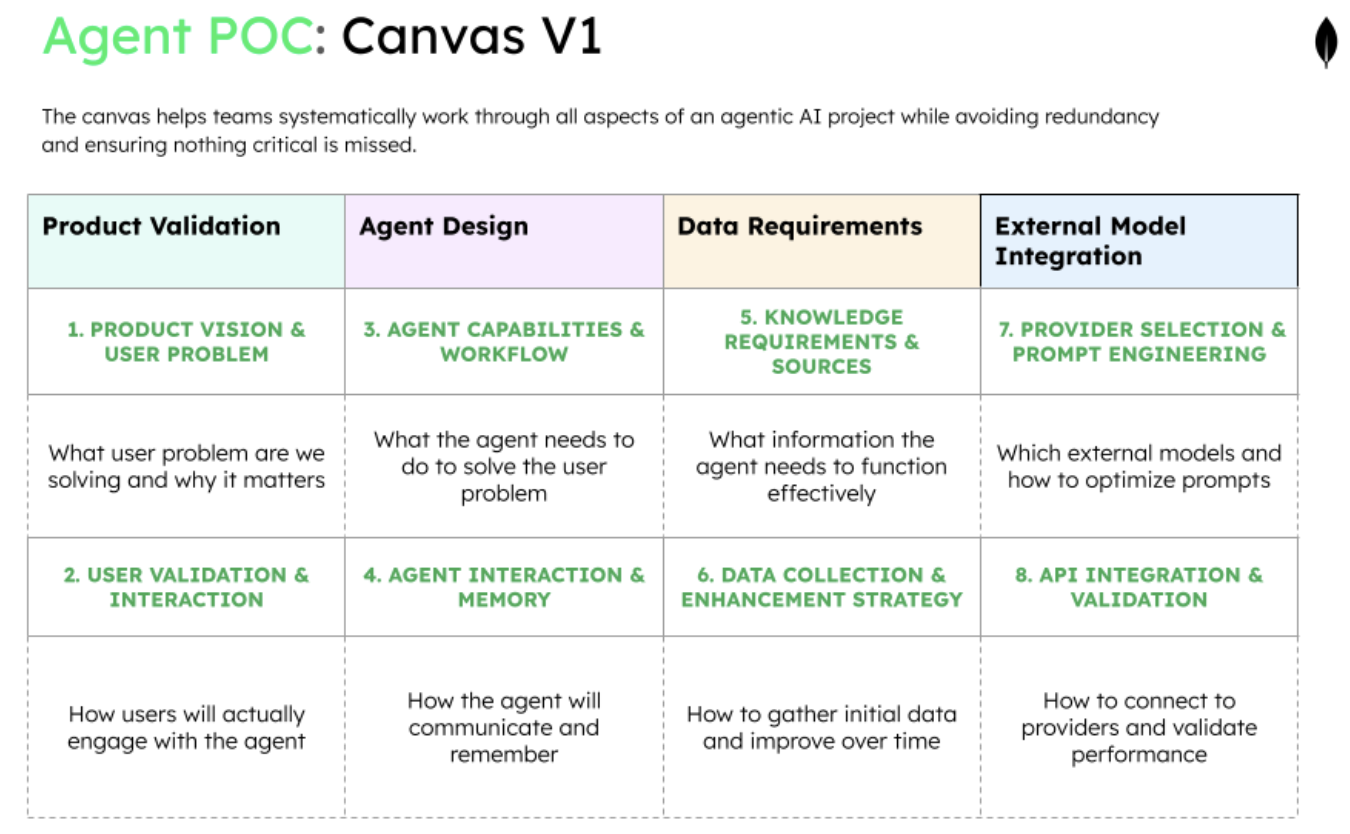
Phase 1: product validation—who needs this and why?
Before building anything, you must validate that a real problem exists and that users actually want an AI agent solution. This phase prevents the common mistake of building impressive technology that nobody needs. If you can't clearly articulate who will use this and why they'll prefer it to current methods, stop here.
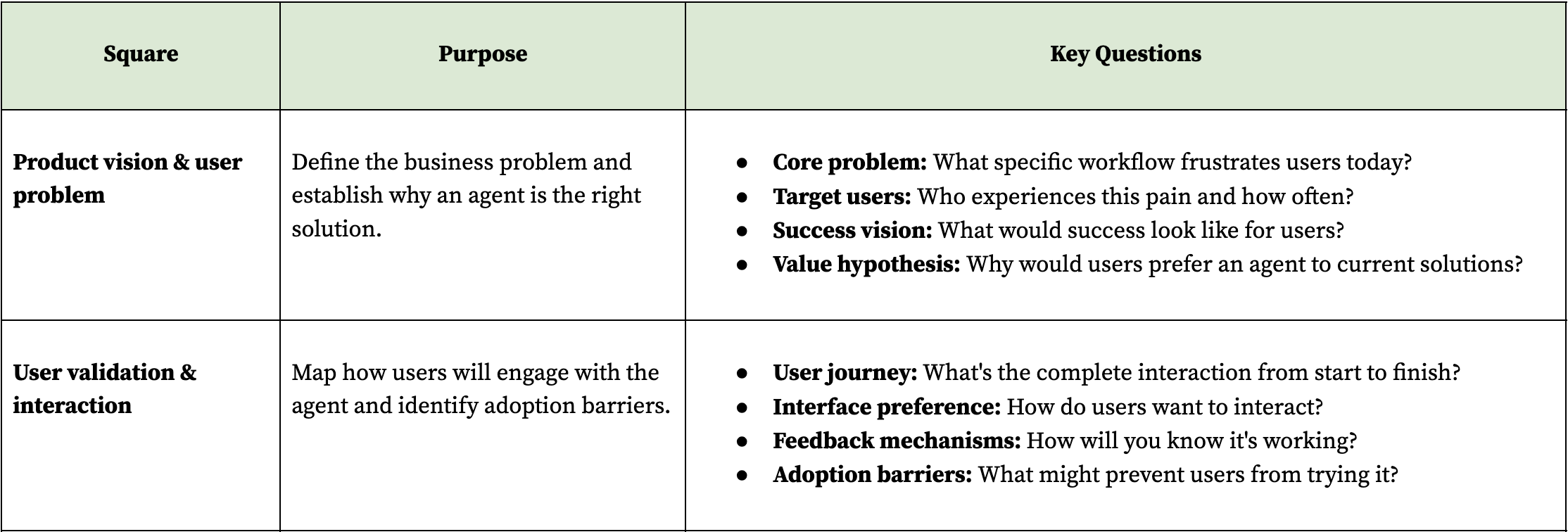
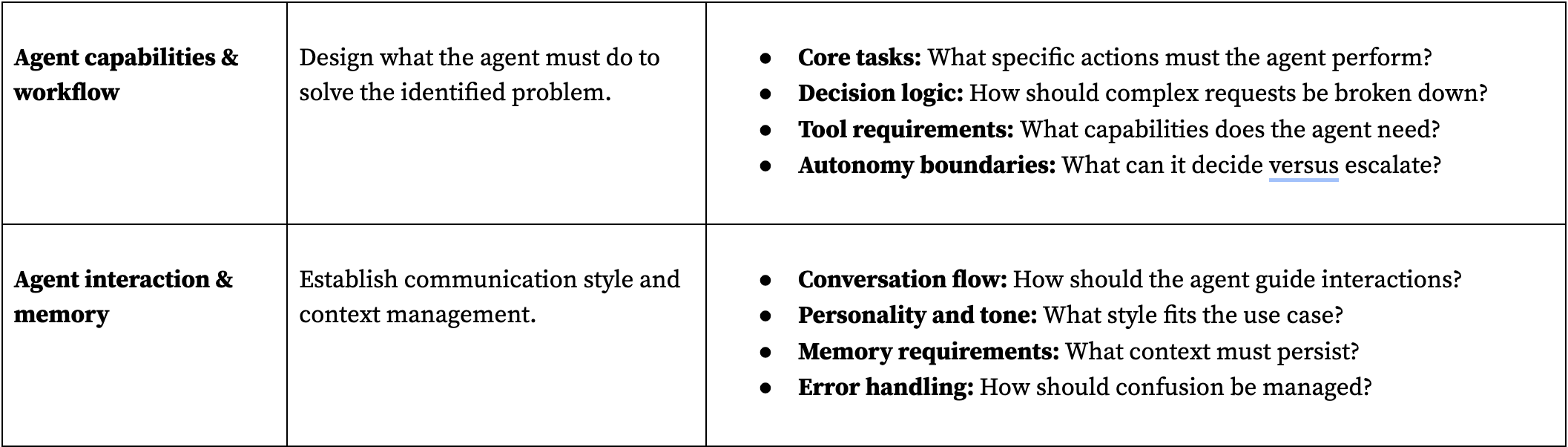
Phase 2: agent design—what will it do and how?
With a validated problem, design the agent's capabilities and behavior to solve that specific need. This phase defines the agent's boundaries, decision-making logic, and interaction style before any technical implementation. The agent design directly determines what data and models you'll need, making this the critical bridge between problem and solution.
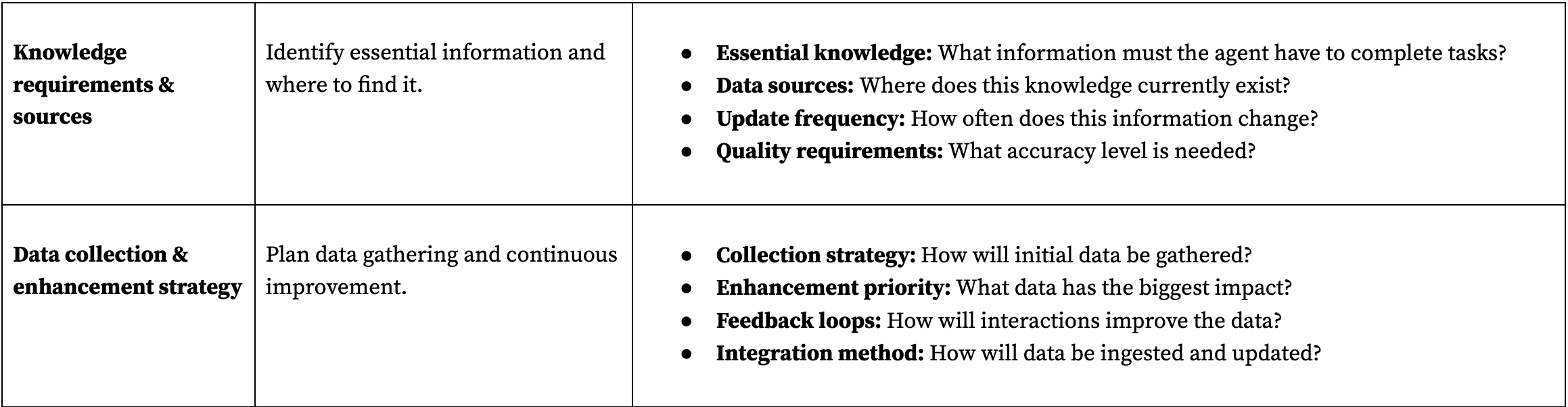
Phase 3: data requirements—what knowledge does it need?
Agents are only as good as their knowledge base, so identify exactly what information the agent needs to complete its tasks. This phase maps existing data sources and gaps before selecting models, ensuring you don't choose technology that can't handle your data reality. Understanding data requirements upfront prevents the costly mistake of selecting models that can't work with your actual information.
Phase 4: external model integration—which provider and how?
Only after defining data needs should you select external model providers and build the integration layer. This phase tests whether available models can handle your specific data and use case while staying within budget. The focus is on prompt engineering and API orchestration rather than model deployment, reflecting how modern AI agents actually get built.
Unified data architecture: solving the infrastructure chaos
Remember the infrastructure problem—teams managing three separate databases with different APIs and scaling characteristics? This is where a unified data platform becomes critical.
Agents need three types of data storage:
- Application database: For business data, user profiles, and transaction history
- Vector store: For semantic search, knowledge retrieval, and RAG
- Memory store: For agent context, conversation history, and learned behaviors
Instead of juggling multiple systems, teams can use a unified platform like MongoDB Atlas that provides all three capabilities—flexible document storage for application data, native vector search for semantic retrieval, and rich querying for memory management—all in a single platform.
This unified approach means teams can focus on prompt engineering and orchestration rather than model infrastructure, while maintaining the flexibility to evolve their data model as requirements become clearer. The data platform handles the complexity while you optimize how external models interact with your knowledge.
For embeddings and search relevance, specialized models like Voyage AI can provide domain-specific understanding, particularly for technical documentation where general-purpose embeddings fall short. The combination of unified data architecture with specialized embedding models addresses the infrastructure chaos that kills projects.
This unified approach means teams can focus on agent logic rather than database management, while maintaining the flexibility to evolve their data model as requirements become clearer.
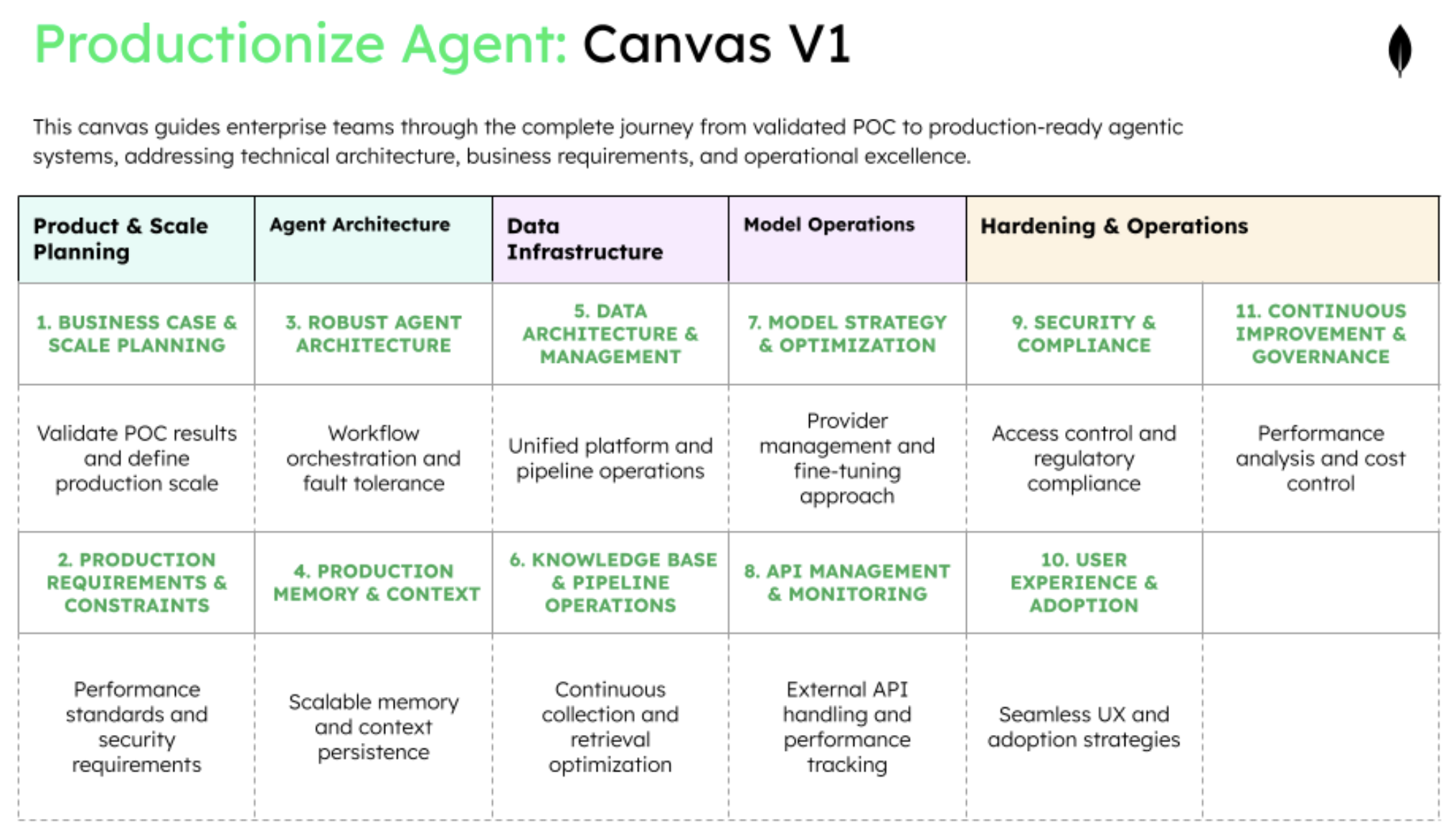
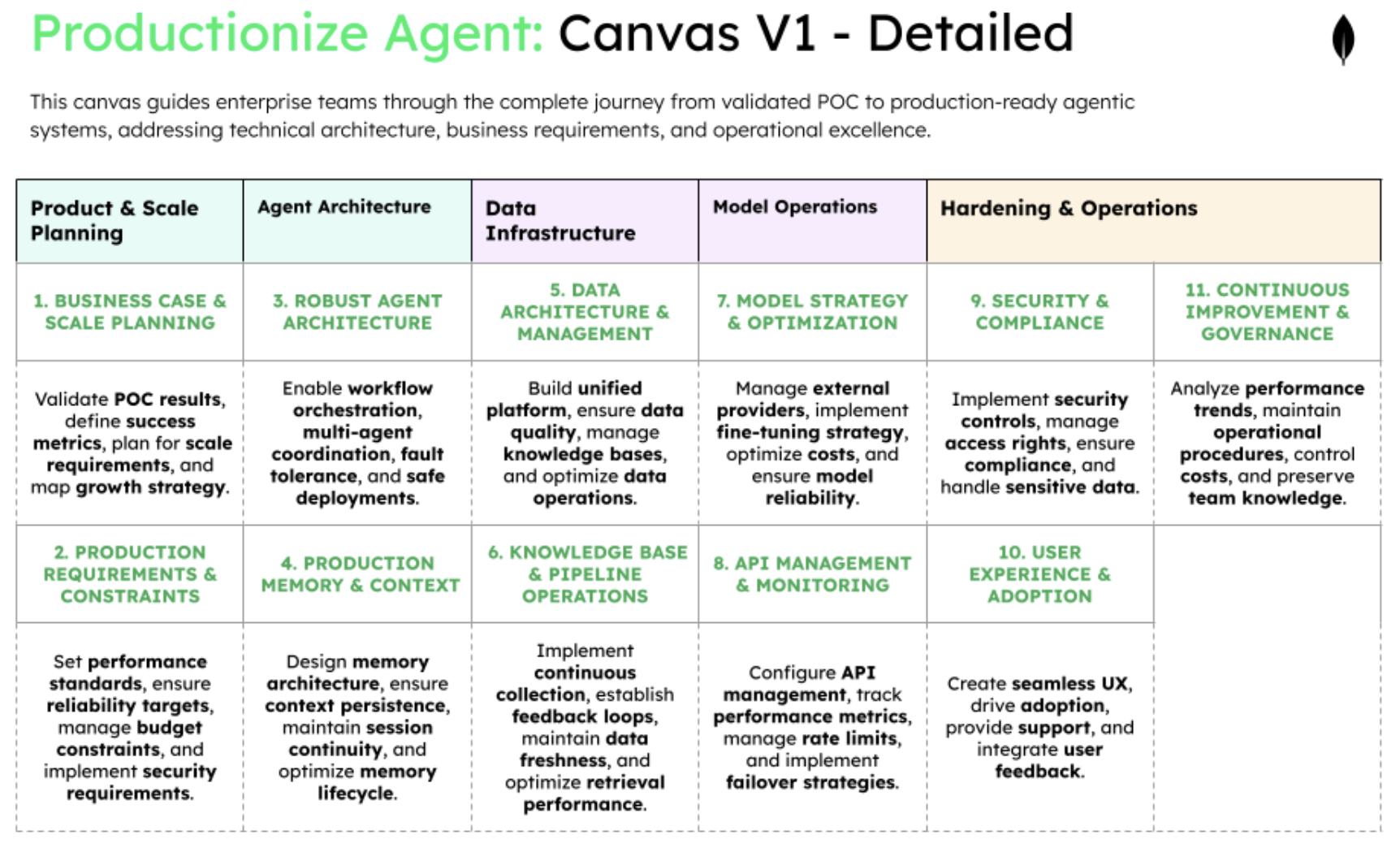
Canvas #2 - The production canvas for scaling your validated AI agent
When a POC succeeds, the production canvas guides the transition from "it works" to "it works at scale" through 11 squares organized following the same product → agent → data → model flow, with additional operational concerns:
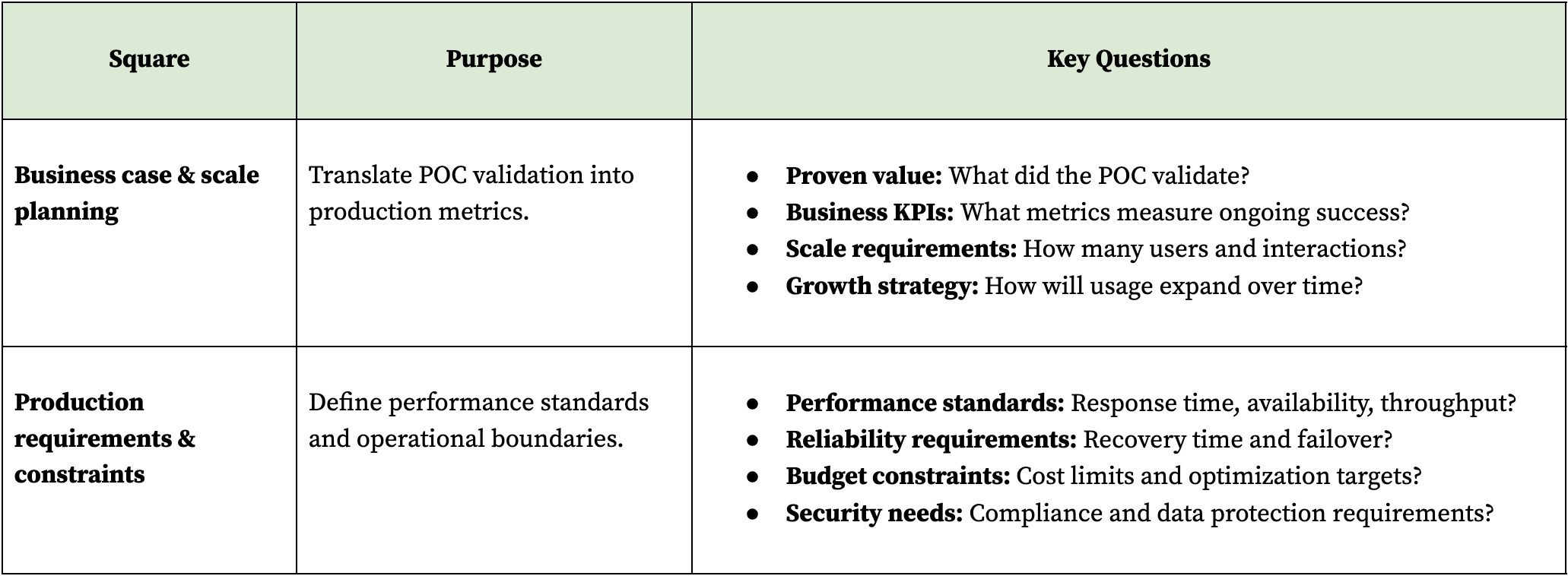
Phase 1: product and scale planning
Transform POC learnings into concrete business metrics and scale requirements for production deployment. This phase establishes the economic case for investment and defines what success looks like at scale. Without clear KPIs and growth projections, production systems become expensive experiments rather than business assets.
Phase 2: Agent architecture
Design robust systems that handle complex workflows, multiple agents, and inevitable failures without disrupting users. This phase addresses the orchestration and fault tolerance that POCs ignore but production demands. The architecture decisions here determine whether your agent can scale from 10 users to 10,000 without breaking.
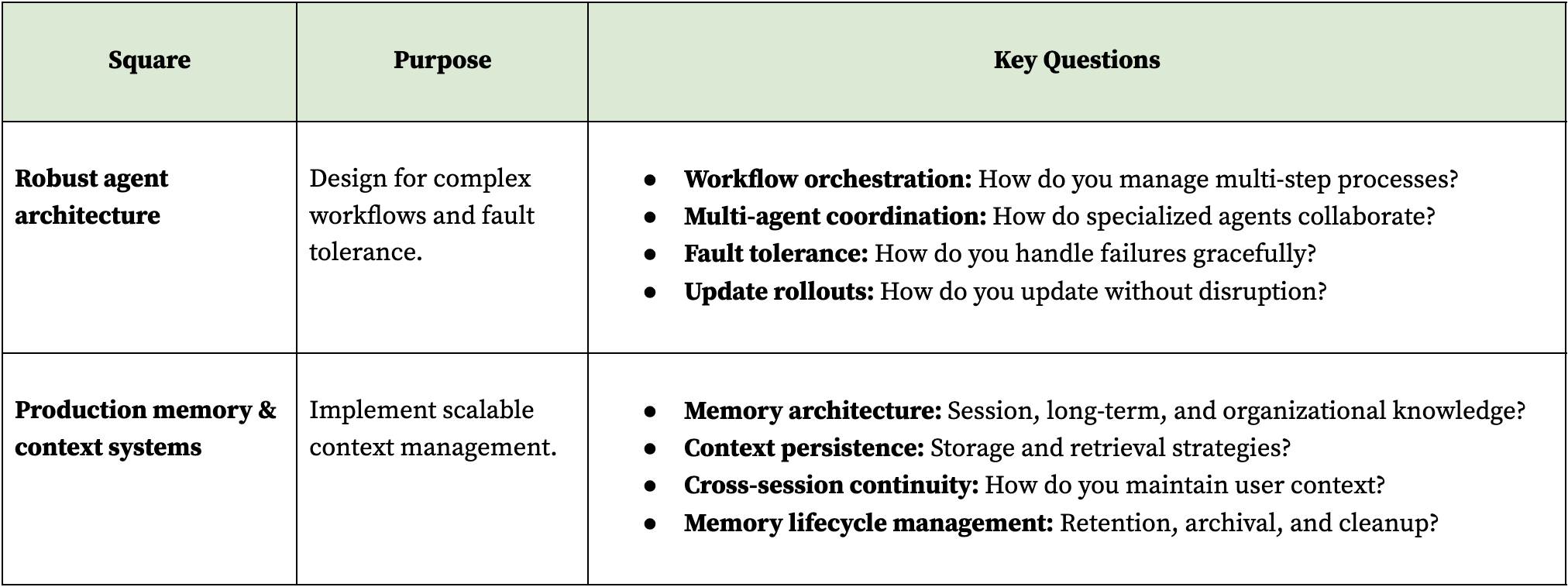
Phase 3: Data infrastructure
Build the data foundation that unifies application data, vector storage, and agent memory in a manageable platform. This phase solves the "three database problem" that kills production deployments through complexity. A unified data architecture reduces operational overhead while enabling the sophisticated retrieval and context management that production agents require.
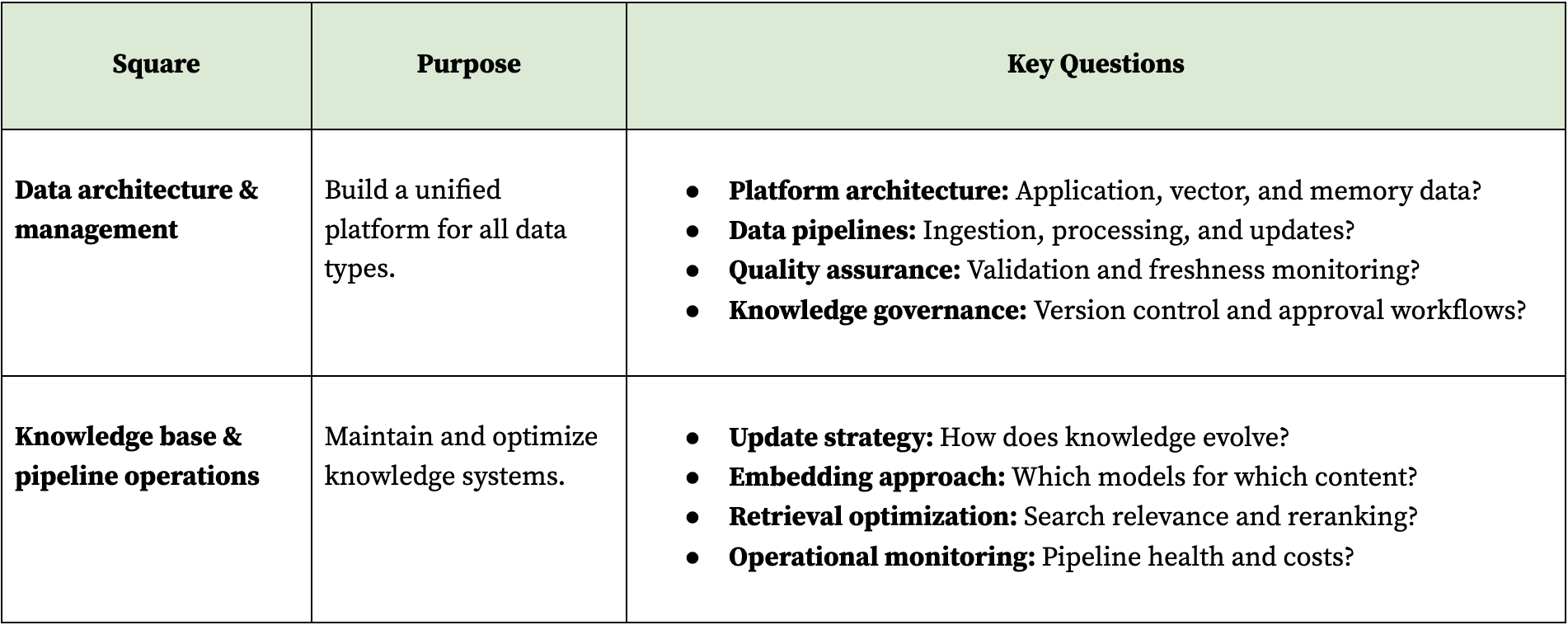
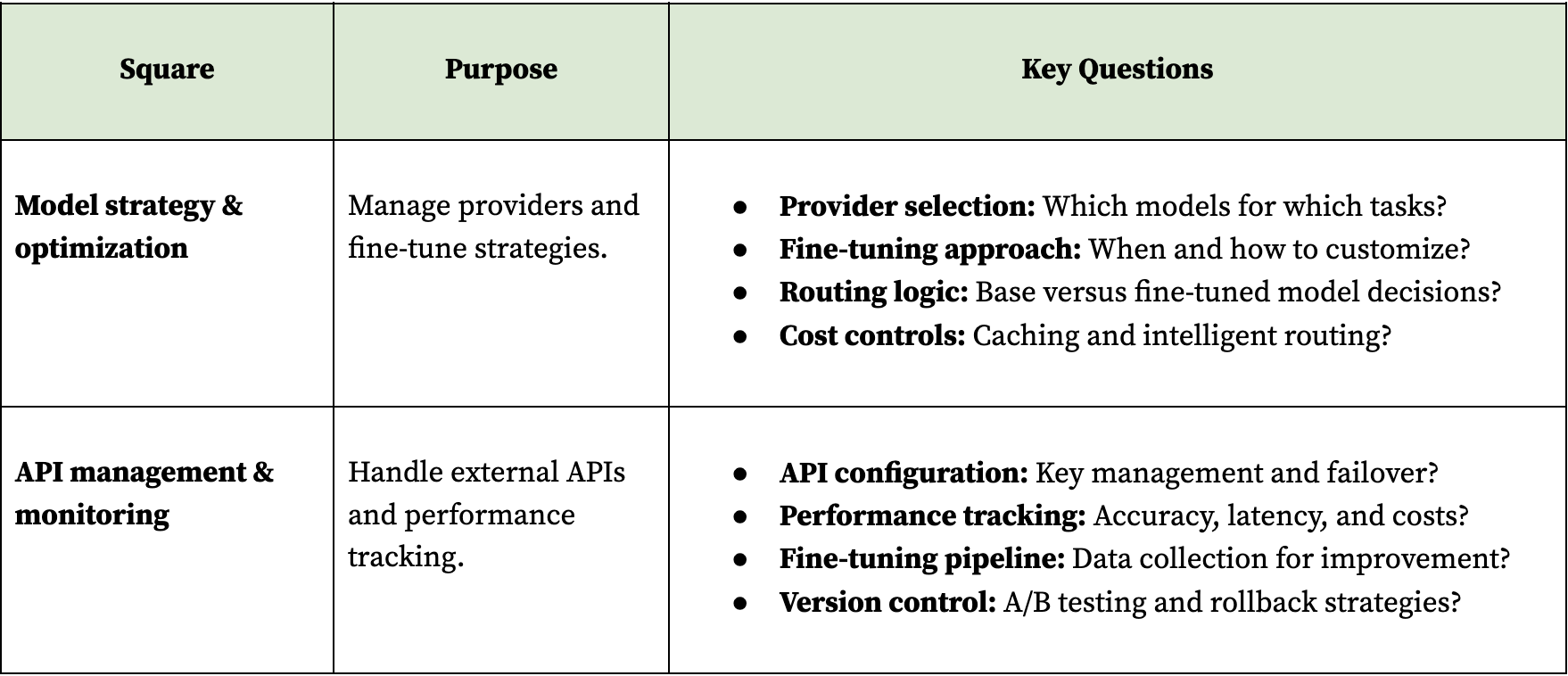
Phase 4: Model operations
Implement strategies for managing multiple model providers, fine-tuning, and cost optimization at production scale. This phase covers API management, performance monitoring, and the continuous improvement pipeline for model performance. The focus is on orchestrating external models efficiently rather than deploying your own, including when and how to fine-tune.
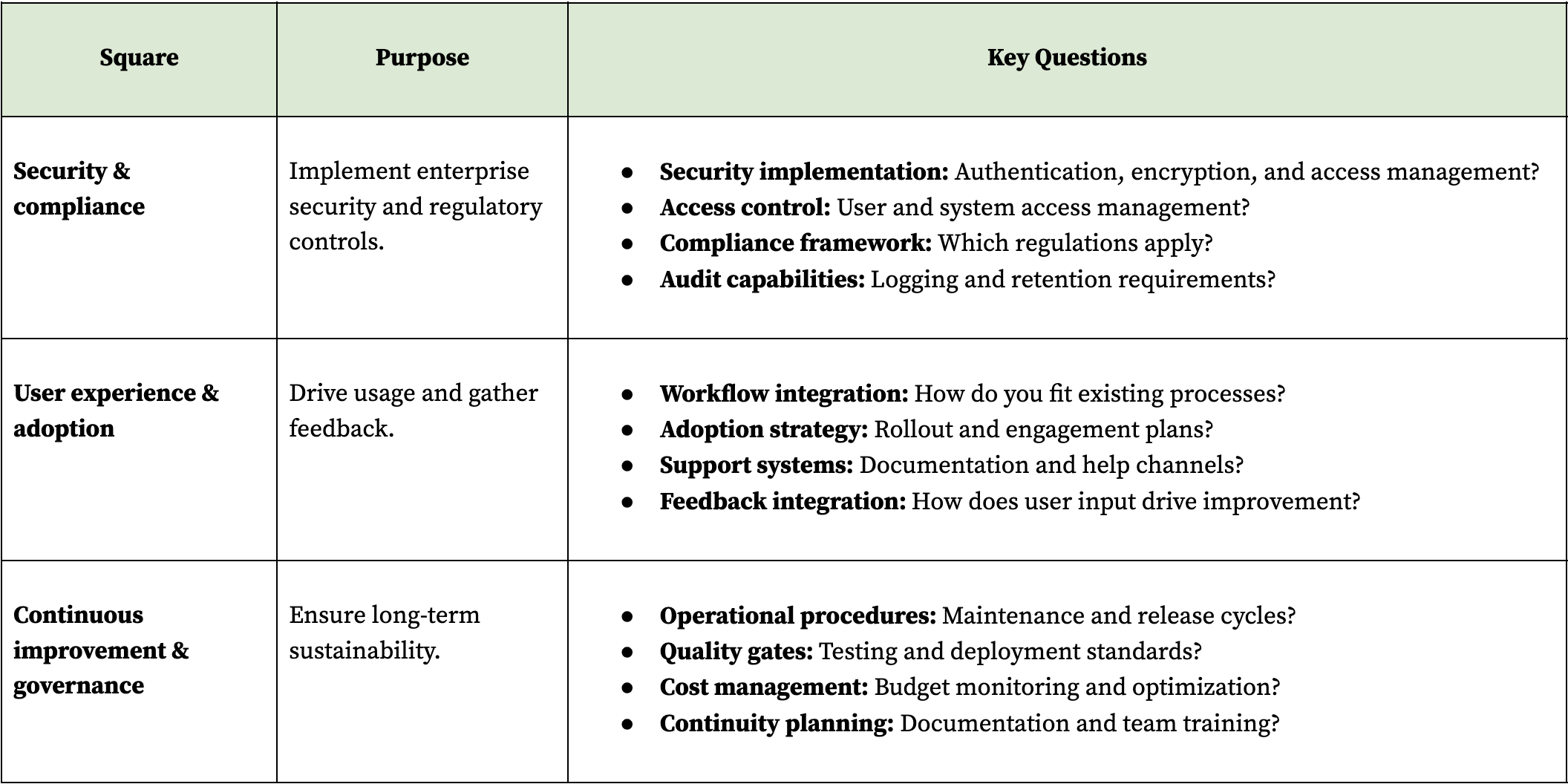
Phase 5: Hardening and operations
Add the security, compliance, user experience, and governance layers that transform a working system into an enterprise-grade solution. This phase addresses the non-functional requirements that POCs skip but enterprises demand. Without proper hardening, even the best agents remain stuck in pilot purgatory due to security or compliance concerns.
Next steps: start building AI agents that deliver ROI
MIT's research found that 66% of executives want systems that learn from feedback, while 63% demand context retention (pg.14). The dividing line between AI and human preference is memory, adaptability, and learning capability.
The canvas framework directly addresses the failure patterns plaguing most projects by forcing teams to answer critical questions in the right order—following the product → agent → data → model flow that successful teams have discovered.
For your next agentic AI initiative:
Start with the POC canvas to validate concepts quickly.
Focus on user problems before technical solutions.
Leverage AI tools to rapidly prototype after completing your canvas.
Only scale what users actually want with the production canvas.
Choose a unified data architecture to reduce complexity from day one.
Remember: The goal isn't to build the most sophisticated agent possible—it's to build agents that solve real problems for real users in production environments.
Ready to start building? Download the agentic AI canvas templates to begin your systematic approach to AI agent development.
Resources
Download Combined POC + Production Canvas (Excel) - Get both canvases in a single Excel file, with example prompts and blank templates.
Full references list
McKinsey & Company. (2025). "Seizing the agentic AI advantage." https://www.mckinsey.com/capabilities/quantumblack/our-insights/seizing-the-agentic-ai-advantage
MIT NANDA. (2025). "The GenAI Divide: State of AI in Business 2025." Report, Form
Gartner. (2025). "Gartner Predicts Over 40% of Agentic AI Projects Will Be Canceled by End of 2027." https://www.gartner.com/en/newsroom/press-releases/2025-06-25-gartner-predicts-over-40-percent-of-agentic-ai-projects-will-be-canceled-by-end-of-2027
IBM. (2025). "IBM Study: Businesses View AI Agents as Essential, Not Just Experimental." https://newsroom.ibm.com/2025-06-10-IBM-Study-Businesses-View-AI-Agents-as-Essential,-Not-Just-Experimental
Carnegie Mellon University. (2025). "TheAgentCompany: Benchmarking LLM Agents." https://www.cs.cmu.edu/news/2025/agent-company
Swyx. (2023). "The Rise of the AI Engineer." Latent Space. https://www.latent.space/p/ai-engineer
SailPoint. (2025). "SailPoint research highlights rapid AI agent adoption, driving urgent need for evolved security." https://www.sailpoint.com/press-releases/sailpoint-ai-agent-adoption-report
SS&C Blue Prism. (2025). "Generative AI Statistics 2025." https://www.blueprism.com/resources/blog/generative-ai-statistics-2025/
PagerDuty. (2025). "State of Digital Operations Report." https://www.pagerduty.com/newsroom/2025-state-of-digital-operations-study/
Wall Street Journal. (2024). "How Moderna Is Using AI to Reinvent Itself." https://www.wsj.com/articles/at-moderna-openais-gpts-are-changing-almost-everything-6ff4c4a5
Next Steps
For hands-on guidance on memory management, check out our webinar on YouTube, which covers essential concepts and proven techniques for building memory-augmented agents.
Head over to the MongoDB AI Learning Hub to learn how to build and deploy AI applications with MongoDB.