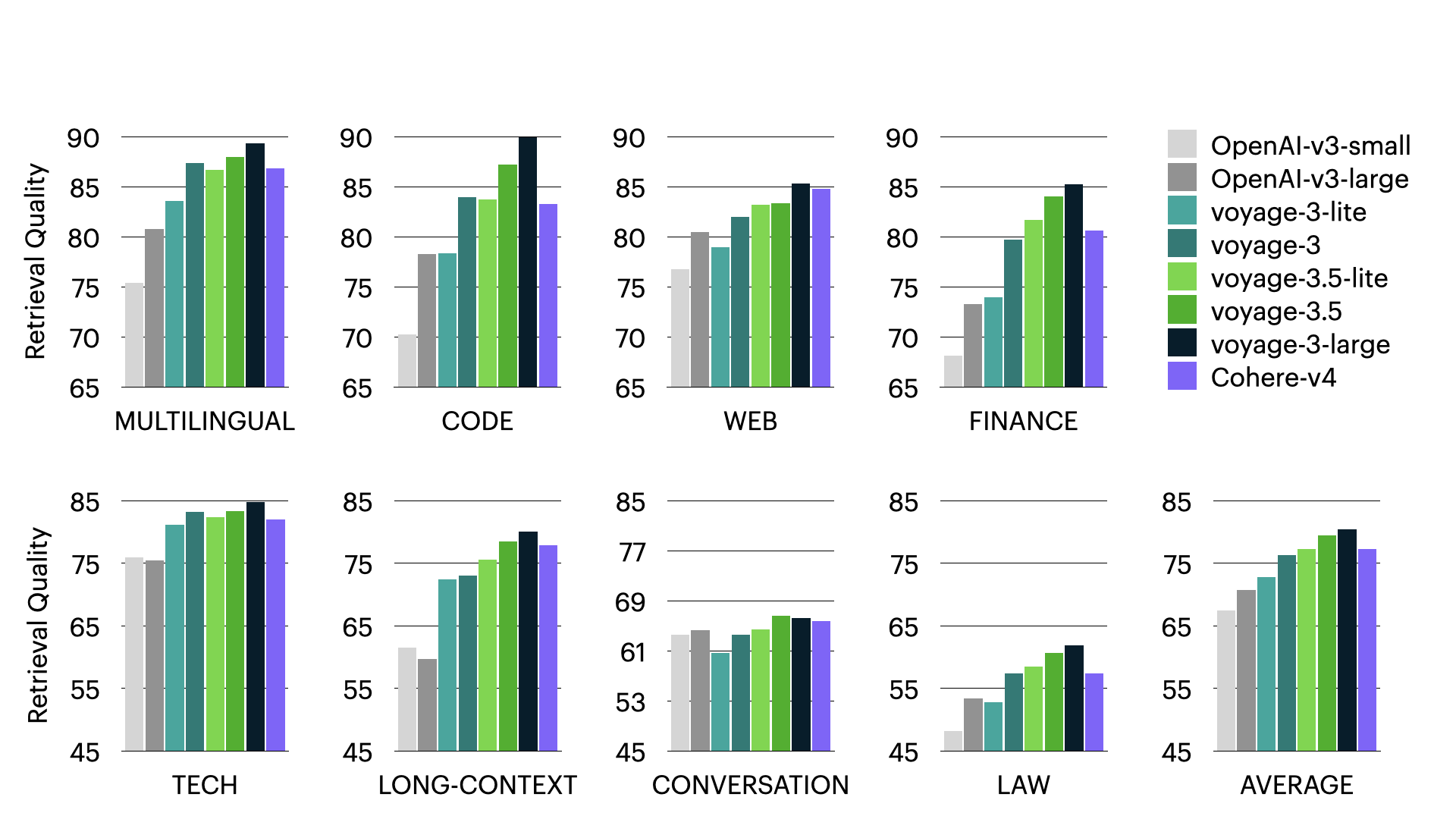From Niche NoSQL to Enterprise Powerhouse: The Story of MongoDB's Evolution
I joined MongoDB two years ago through the acquisition of Grainite, a database startup I co-founded. My journey here is built on a long career in databases, including many years at Google, where I was most recently responsible for the company’s entire suite of native databases—Bigtable, Spanner, Datastore, and Firestore—powering both Google's own products and Google Cloud customers. My passion has always been large-scale distributed systems, and I find that the database space offers the most exciting and complex challenges to solve.
At MongoDB my focus is on architectural improvements across the product stack. I've been impressed with the progression of MongoDB's capabilities and the team's continuous innovation ethos.
In this blog post, I’ll share some of my understanding of MongoDB’s history and how MongoDB became the de facto standard for document databases. I’ll also highlight select innovations we are actively exploring.
The dawn of NoSQL
During the "move fast and break things" era of Web 2.0, the digital landscape was exploding. Developers were building dynamic, data-rich applications at an unprecedented pace, and the rigid, tabular structures of legacy relational databases like Oracle and Microsoft SQL Server quickly became a bottleneck. A new approach was needed, one that prioritized developer productivity, flexibility, and massive scale. At the same time,
JSON's
popularity as a flexible, cross-language format for communicating between browsers and backends was surging. This collective shift toward flexibility gave rise to
NoSQL databases
, and MongoDB, with its native document-based approach, was at the forefront of the movement.
In the early days, there was a perception that MongoDB was great for use cases like social media feeds or product catalogs, but not for enterprise applications where data integrity is non-negotiable—like financial transactions. This view was never perfectly accurate, and it certainly isn't today. So, what created this perception? It came down to two main factors: categorization and maturity.
First, most early NoSQL databases were built on an “eventually consistent” model, prioritizing Availability and Partition Tolerance (AP) under the
CAP theorem
. MongoDB was an exception, designed to prioritize Consistency and Partition Tolerance (CP). But, in a market dominated by AP systems, MongoDB was often lumped in with the rest, leading to the imprecise label of having “light consistency.” Second, all new databases take time to mature for mission-critical workloads. Any established system-of-record database today has gone through many versions over many years to earn that trust. After more than 15 years of focused engineering, today MongoDB has the required codebase maturity, features, and proven track record for the most demanding enterprise applications.
The results speak for themselves. As our CEO Dev Ittycheria mentioned during the
Q2 2026 earnings
call, over 70% of the Fortune 500—as well as 7 of the 10 largest banks, 14 of the 15 largest healthcare companies, and 9 of the 10 largest manufacturers globally—are MongoDB customers. This widespread adoption by the world's most sophisticated organizations is a testament to a multi-year, deliberate engineering journey that has systematically addressed the core requirements of enterprise-grade systems.
MongoDB’s engineering journey: Building a foundation of trust
MongoDB’s evolution from being perceived as a niche database to an enterprise powerhouse wasn't an accident; it was the result of a relentless focus on addressing the core requirements of enterprise-grade systems. Improvements instrumental to this transformation include:
High availability
with replica sets:
The first step was eliminating single points of failure. Replica sets were introduced as self-healing clusters that provide automatic failover, ensuring constant uptime and data redundancy. Later, the introduction of a Raft-style consensus protocol provided even more reliable and faster failover and leader elections, especially in the event of a network partition. This architecture is the foundation for MongoDB’s current multi-region or run-anywhere deployments, and even allows a single replica set to span multiple cloud providers for maximum resilience.
Figure 1.
Horizontal scaling.
Massive scalability with horizontal sharding:
Introduced at the same time as replica sets,
sharding
is a native, foundational part of MongoDB. MongoDB built sharding to allow data to be partitioned across multiple servers, enabling virtually limitless horizontal scaling to support massive datasets and high-throughput operations. Advanced features like zone sharding further empower global applications by pinning data to specific geographic locations to reduce latency and comply with data residency laws like GDPR.
Tunable consistency:
Recognizing that not all data is created equal, MongoDB empowered developers with tunable read and write concerns. Within a single application, some data—like a 'page view count'—might not have the same consistency requirements as a 'order checkout value'. Instead of using separate, specialized databases for each use case, developers can use MongoDB for both. This moved the platform beyond a one-size-fits-all model, allowing teams to choose the precise level of consistency their application required per operation—from "fire and forget" for speed to fully acknowledged writes across a majority of replicas for guaranteed durability. This flexibility provides the best price/performance tradeoffs for modern applications.
The game-changer, multi-document
ACID transactions
:
From its inception, MongoDB has always provided atomic operations for single documents. The game-changing moment was the introduction of multi-document ACID transactions in 2018 with MongoDB 4.0, which was arguably the single most important development in its history. This feature, later extended to include sharded clusters, meant that complex operations involving multiple documents—like a financial transfer between two accounts—could be executed with the same atomicity, consistency, isolation, and durability (ACID) guarantees as a traditional relational database. This milestone shattered the biggest barrier to adoption for transactional applications. And the
recently released MongoDB 8.2
is the most feature-rich and performant version of MongoDB yet.
Strict security and compliance: To meet the stringent security demands of the enterprise, MongoDB layered in a suite of advanced security controls. Features like Role-Based Access Control (RBAC), detailed auditing, and Field-Level Encryption were just the beginning. The release of Queryable Encryption (
to which we recently introduced support for prefix, suffix, and substring queries
) marked a revolutionary breakthrough, allowing non-deterministic encrypted data to be queried without ever decrypting it on the server, ensuring data remains confidential even from the database administrator. To provide independent validation, MongoDB Atlas has achieved a number of internationally recognized security certifications and attestations, including
ISO/IEC 27001
,
SOC 2 Type II
,
PCI DSS
, and
HIPAA
compliance, demonstrating a commitment to meeting the rigorous standards of the world's most regulated industries.
Figure 2.
Queryable Encryption.
The ultimate proof of enterprise readiness lies in real-world adoption. Today, MongoDB is trusted by leading organizations across the most demanding sectors to run their core business systems.
For example,
Citizens Bank
, one of the oldest and largest financial institutions in the United States, moved to modernize its fraud detection capabilities from a slow, batch-oriented legacy system. They built a new, comprehensive fraud management platform on MongoDB Atlas that allows for near real-time monitoring of transactions.
This use case in a highly regulated industry requires high availability, low latency, and strong consistency to analyze transactions in real-time and prevent financial loss—a direct refutation of the old "eventual consistency" criticism.
Another example is that of
Bosch Digital
, the software and systems house for the Bosch Group. Bosch Digital uses MongoDB for its IoT platform, Bosch IoT Insights, to manage and analyze massive volumes of data from connected devices—from power tools used in aircraft manufacturing, to sensors in vehicles. IoT data arrives at high speeds, in huge volumes, and in variable structures. This mission-critical use case demonstrates MongoDB's ability to handle the demands of industrial-scale IoT, providing the real-time analytics needed to ensure quality, prevent errors, and drive innovation.
Then there’s
Coinbase
, which relies on MongoDB to seamlessly handle the volatile and unpredictable cryptocurrency market. Specifically, Coinbase architected a MongoDB Atlas solution that would accelerate scaling for large clusters. The result was that Coinbase end-users gained a more seamless experience. Previously, traffic spikes could impact some parts of the Coinbase app. Now, users don’t even notice changes happening behind the scenes.
These are just a few examples; customers across all verticals, industries, and sizes depend on MongoDB for their most demanding production use cases. A common theme is that real-world data is messy, variable, and doesn't fit neatly into rigid, tabular structures.
The old adage says that if all you have is a hammer, everything looks like a nail. For decades, developers only had the relational "hammer." With MongoDB, they now have a modern tool that adapts to how developers work and the data they need to manage and process.
The road ahead: Continuous innovation
MongoDB is not resting on its laurels. The team is as excited about what the future holds as they were when MongoDB was first launched, and we continue to innovate aggressively to meet—and anticipate—the modern enterprise’s demands. Here are select improvements we are actively exploring.
A critical need we hear from customers is how to support elastic workloads in a price-performant way. To address this, over the past two years we’ve rolled out Search Nodes, which is a unique capability in MongoDB that allows scaling of search and vector workloads independent from the database to improve availability and price performance.
We are now working closely with our most sophisticated customers to explore how to deliver similar capabilities across more of MongoDB. Our vision is to enable customers to
scale compute for high-throughput queries without over-provisioning storage
, and vice versa. We can do all this while building upon what is already one of the strongest security postures of any cloud database, as we continue to raise the bar for durability, availability, and performance.
Another challenge facing large enterprises is the significant cost and risk associated with modernizing legacy applications. To solve this, we are making a major strategic investment in
enterprise application modernization, and recently announced the
MongoDB Application Modernization Platform
. We have been engaged with several large enterprises in migrating their legacy relational database applications—code, data, and everything in between—over to MongoDB. This is not a traditional, manual migration effort capped by the number of bodies assigned. Instead, we are systematically developing Agentic tooling and AI-based frameworks, techniques, and processes that allow us to smartly migrate legacy applications into modern microservices-based architectures at scale.
One of the more exciting findings from a recent effort, working with a large enterprise in the insurance sector, was that optimized queries on MongoDB ran just as fast, and often significantly faster, than on their legacy relational database, even when schemas were translated 1:1 between relational tables and MongoDB collections, and lots of nested queries and joins were involved. Batch jobs implemented as complex stored procedures that took several hours to execute on the relational database could be completed in under five minutes, thanks to the parallelism MongoDB natively enables (for more, see the
MongoDB Developer Blog
).
Based on the incredible performance gains seen in these modernization projects, we're addressing another common need: ensuring fast queries even when data models aren't perfectly optimized. We are actively exploring improvements to our
Query Optimizer
that will improve lookup and join performance. While the document model will always be the most performant way to model your data, we are ensuring that even when you don't create the ideal denormalized data model, MongoDB will deliver performance that is at par or better than the alternatives.
Finally, developers today are often burdened with stitching together multiple services to build modern, AI-powered applications. To simplify this, the platform is expanding far beyond a traditional database, focused on providing a
unified developer experience
. This includes a richer ecosystem with integrated capabilities like
Atlas Search
for full-text search,
Atlas Vector Search
for AI-powered semantic search, and native
Stream Processing
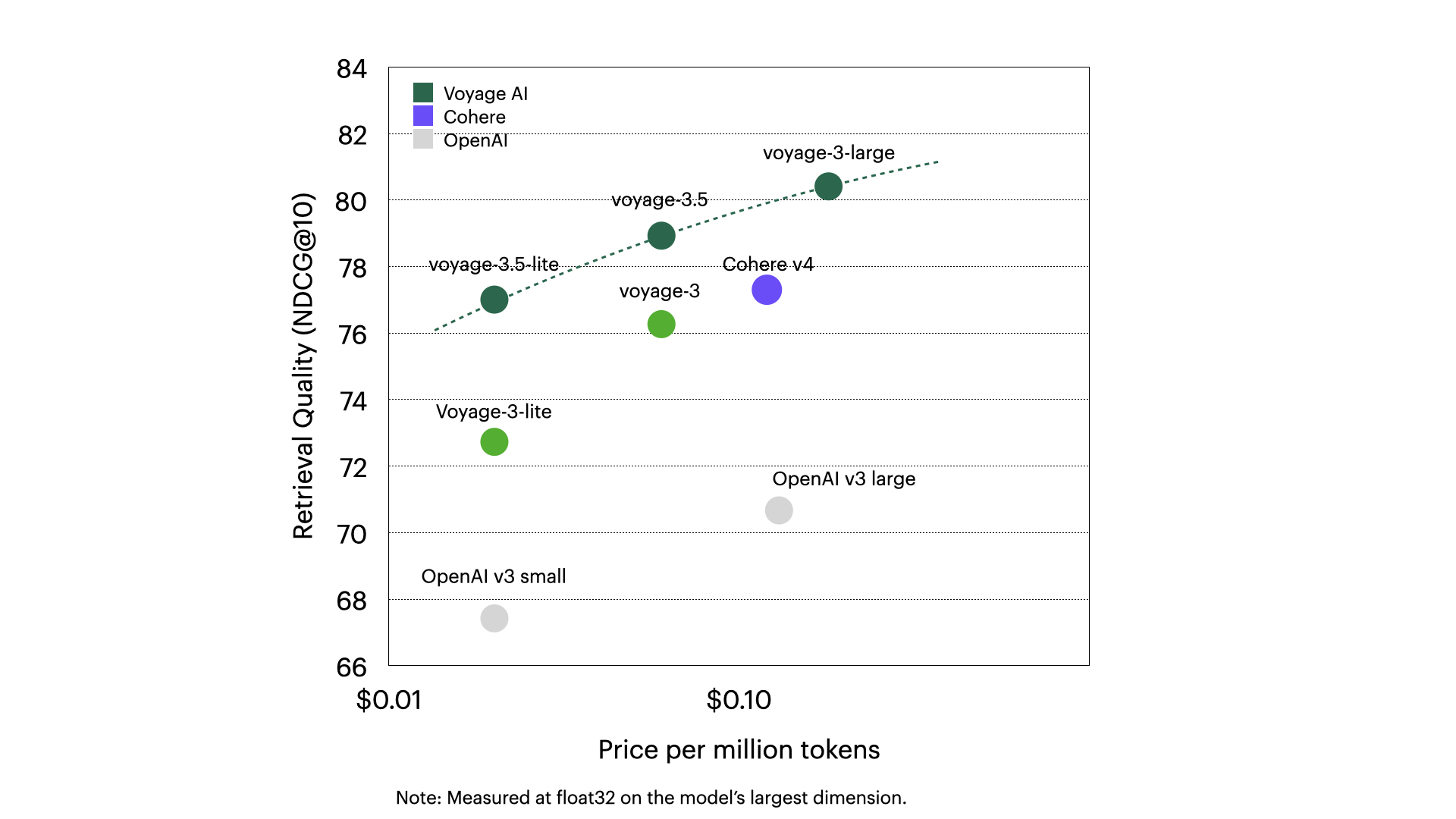
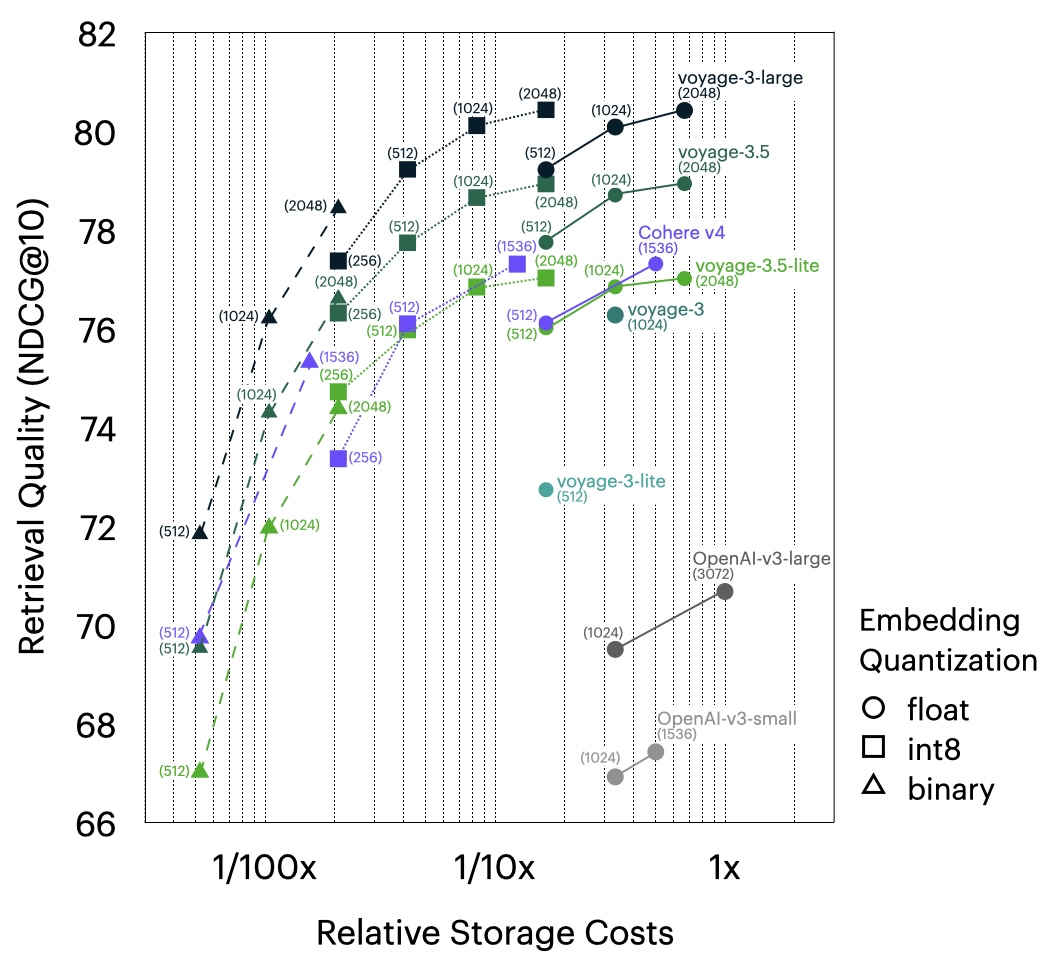
to handle real-time data. We are already working on our first integrations, and continue to explore how embedding generation as a service within MongoDB Atlas, powered by our own Voyage AI models, can further simplify application development.
From niche to necessity
MongoDB began its journey as a (seemingly) niche NoSQL database with perceptions and tradeoffs that made it unsuitable for many core business applications. But, through a sustained and deliberate engineering effort, it has delivered the high availability, tunable consistency, ACID transactions, and robust security that enterprises demand. The perceptions of the past no longer match the reality of the present. When 7 of the 10 largest banks are already using MongoDB, isn’t it time to re-evaluate MongoDB for your most critical applications?
For more on why innovation requires a modern, AI-ready database—and why companies like Nationwide, Wells Fargo, and The Knot Worldwide chose MongoDB over relational databases—
see the MongoDB customer use case site
.
September 25, 2025