TL;DR – We’re excited to introduce voyage-3.5 and voyage-3.5-lite, the latest generation of our embedding models. These models offer improved retrieval quality over voyage-3 and voyage-3-lite at the same price, setting a new frontier for price-performance. Both models support embeddings in 2048, 1024, 512, and 256 dimensions, with multiple quantization options enabled by Matryoshka learning and quantization-aware training. voyage-3.5 and voyage-3.5-lite outperform OpenAI-v3-large by 8.26% and 6.34%, respectively, on average across evaluated domains, with 2.2x and 6.5x lower respective costs and a 1.5x smaller embedding dimension. Compared with OpenAI-v3-large (float, 3072), voyage-3.5 (int8, 2048) and voyage-3.5-lite (int8, 2048) reduce vector database costs by 83%, while achieving higher retrieval quality.
Note to readers: voyage-3.5 and voyage-3.5-lite are currently available through the Voyage AI APIs directly or through the private preview of automated text embedding in Atlas Vector Search. For access, sign up for Voyage AI or register your interest in the Atlas Vector Search private preview.
We’re excited to introduce voyage-3.5 and voyage-3.5-lite, which maintain the same sizes as their predecessors—voyage-3 and voyage-3-lite—but offer improved quality for a new retrieval frontier.
As we see in the figure below, voyage-3.5 improves retrieval quality over voyage-3 by 2.66%, and voyage-3.5-lite improves over voyage-3-lite by 4.28%—both maintaining a 32K context length and their respective price points of $0.06 and $0.02 per 1M tokens.
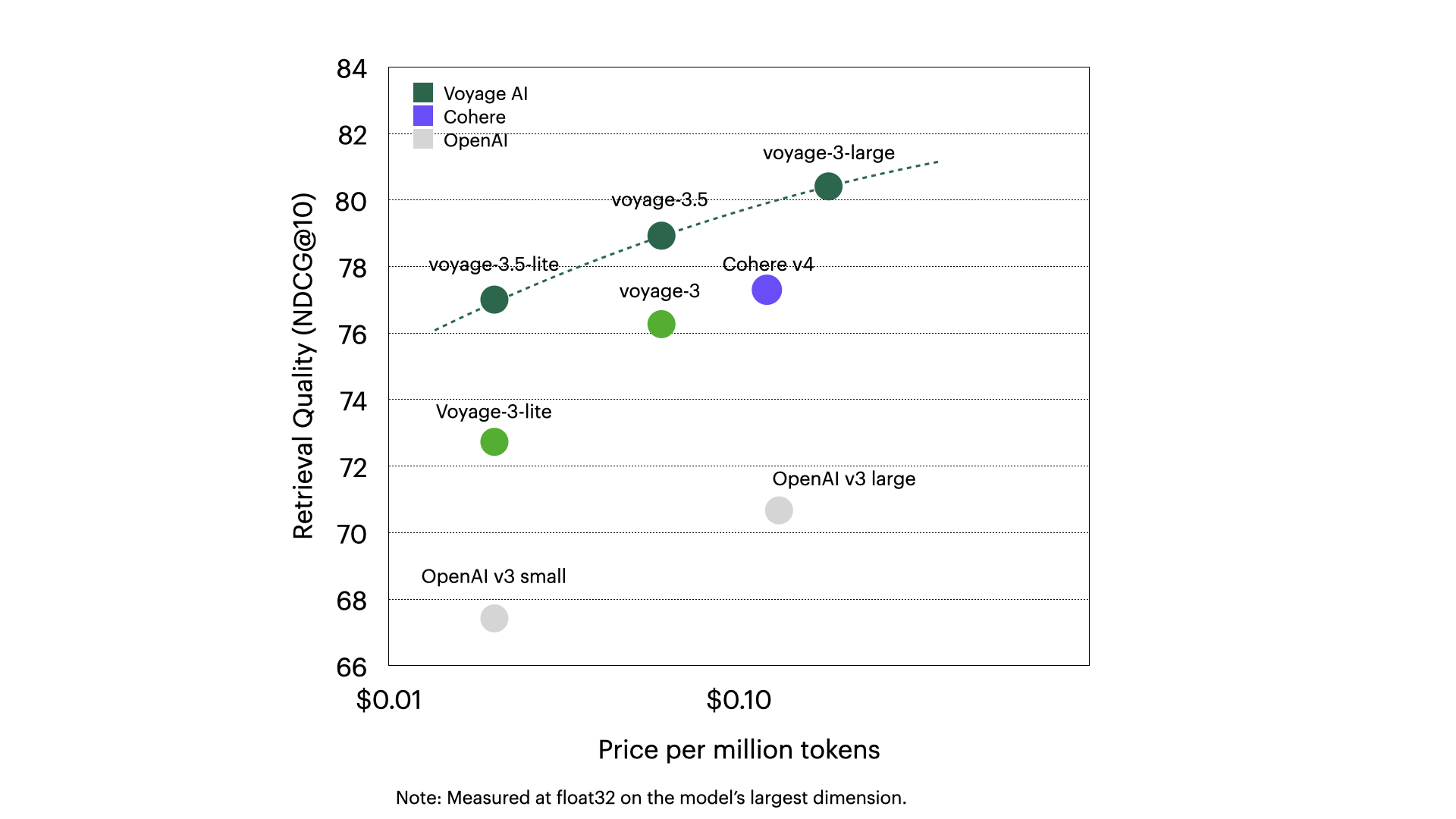
voyage-3.5 and voyage-3.5-lite also outperforms OpenAI-v3-large by 8.26% and 6.34%, respectively, with voyage-3.5 also outperforming Cohere-v4 by 1.63%. voyage-3.5-lite achieves retrieval quality within 0.3% of Cohere-v4 at 1/6 the cost. Both models advance the cost-performance ratio of embedding models to a new state-of-the-art through an improved mixture of training data, distillation from voyage-3-large, and the use of Voyage AI rerankers.
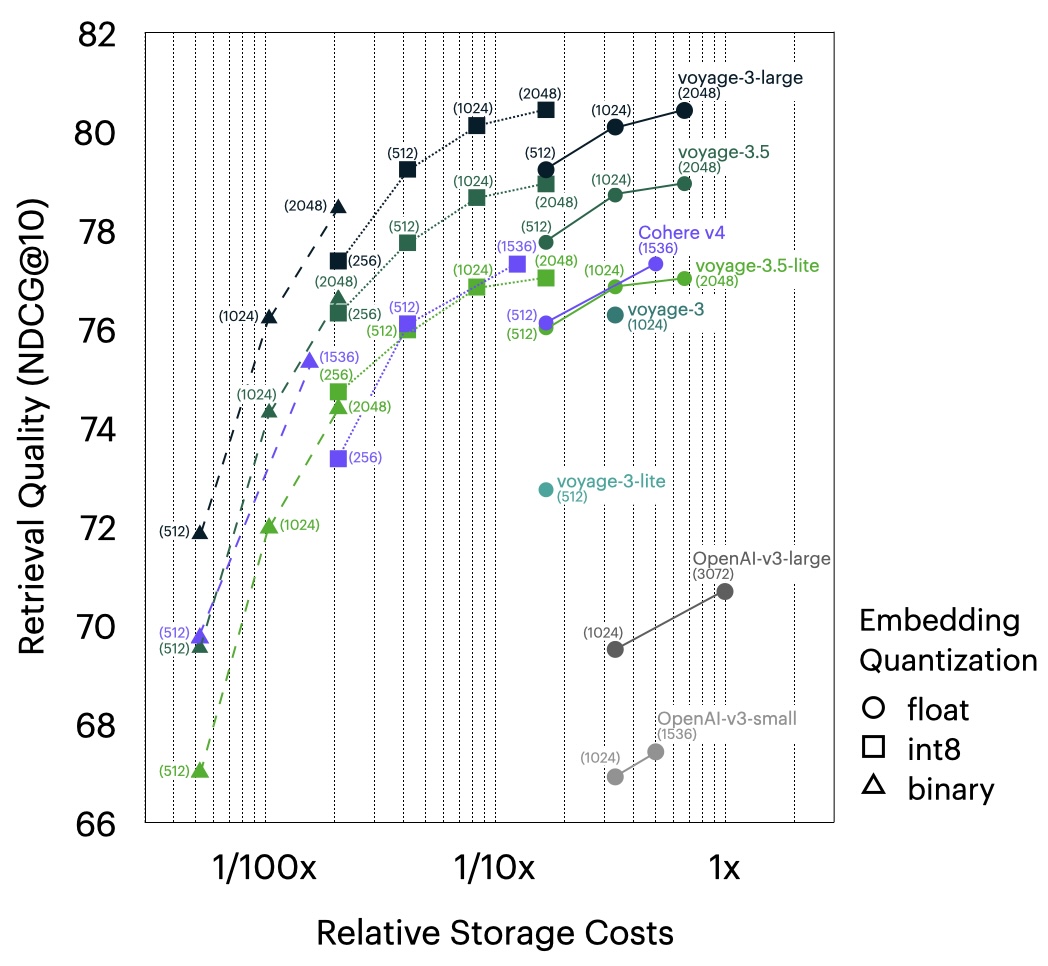
Matryoshka embeddings and quantization: voyage-3.5 and voyage-3.5-lite support 2048, 1024, 512, and 256-dimensional embeddings enabled by Matryoshka learning and multiple embedding quantization options—including 32-bit floating point, signed and unsigned 8-bit integer, and binary precision—while minimizing quality loss. Compared with OpenAI-v3-large (float, 3072), voyage-3.5 and voyage-3.5-lite (both int8, 2048) reduce vector database costs by 83%, while achieving outperformance of 8.25% and 6.35% respectively. Further, comparing OpenAI-v3-large (float, 3072) with voyage-3.5 and voyage-3.5-lite (both binary, 1024), vector database costs are reduced by 99%, with outperformance of 3.63% and 1.29% respectively.
Evaluation details
Datasets: We evaluate on 100 datasets spanning eight domains: technical documentation, code, law, finance, web reviews, multilingual, long documents, and conversations. Each dataset consists of a corpus (e.g., technical documentation, court opinions) and queries (e.g., questions, summaries). The following table lists the datasets in the eight categories, except multilingual, which includes 62 datasets covering 26 languages. A list of all evaluation datasets is available in this spreadsheet.
Models: We evaluate voyage-3.5 and voyage-3.5-lite alongside several alternatives, including: OpenAI-v3 small (text-embedding-3-small) and large (text-embedding-3-large), Cohere-v4 (embed-v4.0), voyage-3-large, voyage-3, and voyage-3-lite.
Metrics: Given a query, we retrieve the top 10 documents based on cosine similarities and report the normalized discounted cumulative gain (NDCG@10), a standard metric for retrieval quality and a variant of the recall.
Results
All the evaluation results are available in this spreadsheet.
Domain-specific quality: The bar charts below illustrate the average retrieval quality of voyage-3.5 and voyage-3.5-lite with full precision and 2048 dimensions, both overall and for each domain. voyage-3.5 outperforms OpenAI-v3-large, voyage-3, and Cohere-v4 by an average of 8.26%, 2.66%, and 1.63%, respectively across domains. voyage-3.5-lite outperforms OpenAI-v3-large and voyage-3-lite by an average of 6.34% and 4.28%, respectively across domains.
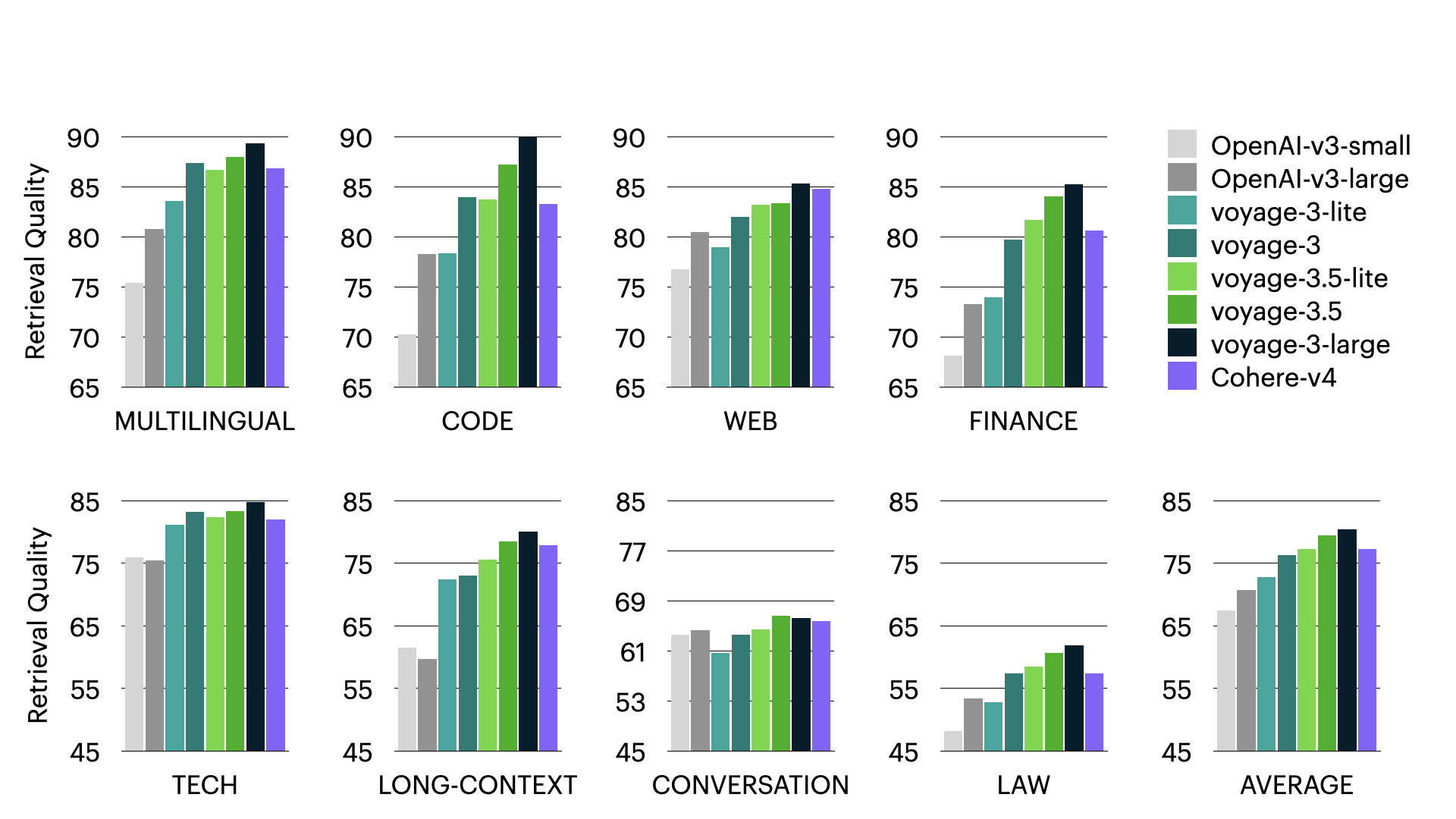
Binary rescoring: In some cases, users retrieve an initial set of documents using binary embeddings (e.g., 100 in our evaluation) and then rescore them with full-precision embeddings. For voyage-3.5 and voyage-3.5-lite, this binary rescoring approach yields up to 6.38% and 6.89% improvements, respectively, in retrieval quality over standard binary retrieval.
Try voyage-3.5 and voyage-3.5-lite!
Interested in getting started today via the Voyage API? The first 200 million tokens are free. Visit the docs to learn more.
Interested in using voyage-3.5 or voyage-3.5-lite alongside MongoDB Atlas? Register your interest in the private preview for automated embedding in Atlas Vector Search.