In today's volatile geopolitical environment, the global automotive industry faces compounding disruptions that require a fundamental rethink of data and operations strategy. After decades of low import taxes, the return of tariffs as a tool of economic negotiations has led the global automotive industry to delay model-year transitions and disrupt traditional production and release cycles. As of June 2025, only 3% of US automotive inventory comprises next-model-year vehicles—less than half the number seen at this time in previous years.
This severe decline in new-model availability, compounded by a 12.2% year-over-year drop in overall inventory, is pressuring consumer pricing and challenging traditional dealer inventory management. In this environment of constrained supply, better tools are urgently needed to classify and control vehicle, spare part, and raw material inventories for both dealers and manufacturers.
Traditionally, dealerships and automakers have relied on ABC analysis to segment and control inventory by value. This widely used method classifies items into Category A, B, or C. For example, Category A items typically represent just 20% of stock but drive 80% of sales, while Category C items might comprise half the inventory yet contribute only 5% to the bottom line. This approach effectively helps prioritize resource allocation and promotional efforts.
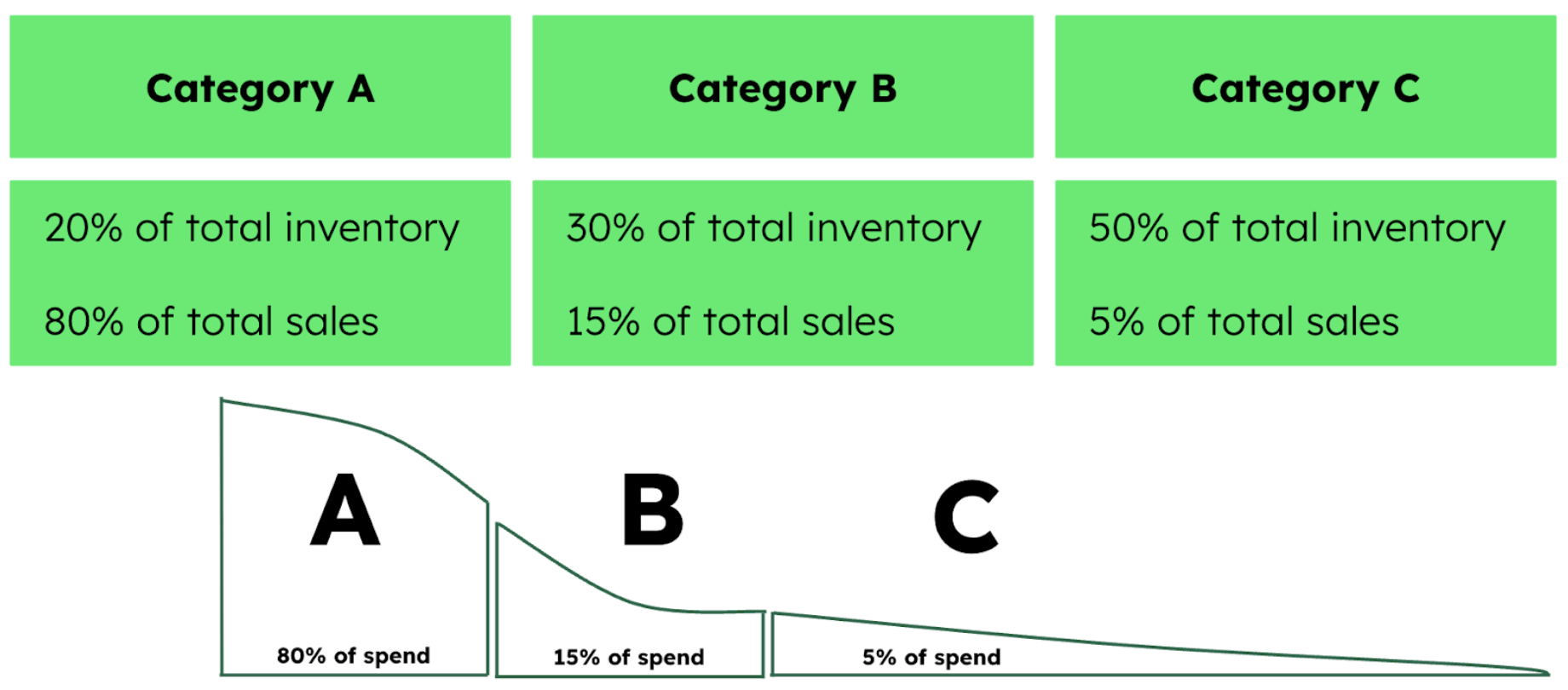
While ABC analysis is known for its ease of use, it has been criticized for its focus on dollar usage. For example, not all Category C items are necessarily low-priority, as some may be next-model-year units arriving early or aging stock affected by shifting consumer preferences. Other criteria—such as lead-time, commonality, obsolescence, durability, inventory cost, and order size requirements—have also been recognized as critical for inventory classification. A multi-criteria inventory classification (MCIC) methodology, therefore, adds additional criteria to dollar usage. MCIC can be achieved with methods like statistical clustering or unsupervised machine learning techniques.
Yet, a significant blind spot remains: the vast amount of unstructured data that organizations must deal with; unstructured data accounts for an estimated 80% of the world's total.
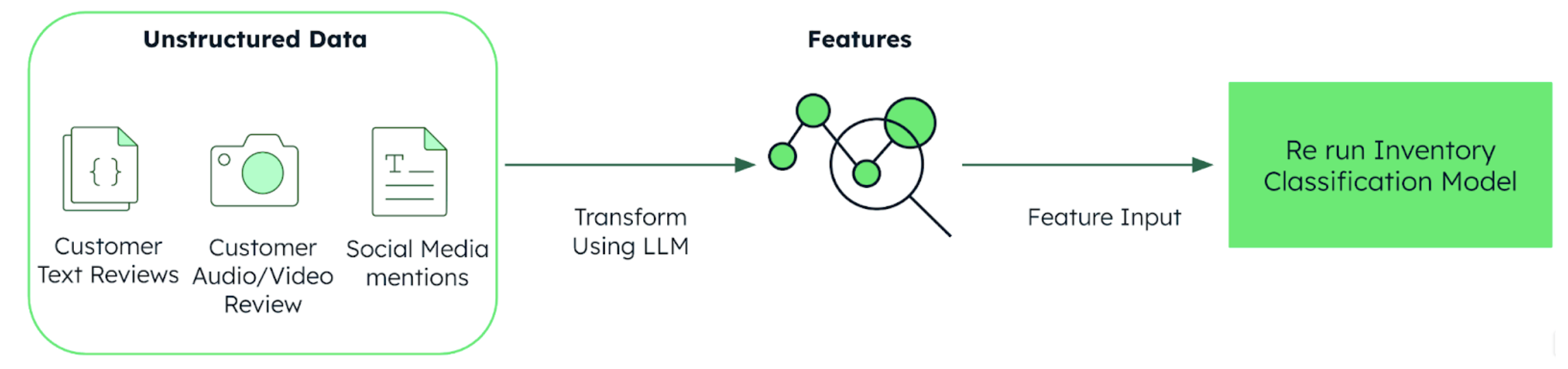
Traditional ABC analysis—and even MCIC—often overlook the growing influence of insights gleaned from unstructured sources like customer sentiment and product reviews on digital channels. But now, valuable intelligence from reviews, social media posts, and dealer feedback can be vectorized and transformed into actionable features using large language models (LLMs). For instance, analyzing product reviews can yield qualitative metrics like the probability of recommending or repurchasing a product, or insights into customer expectations vs. the reality of ownership. This textual analysis can also reveal customers' product perspectives, directly informing future demand.
By integrating these signals into inventory classification models, businesses can gain a deeper understanding of true product value and demand elasticity. This fusion of structured and unstructured data represents a crucial shift from reactive inventory management to predictive and customer-centric decision-making. In this blog post, we propose a novel methodology to convert unstructured data into powerful feature sets for augmenting inventory classification models.
How MongoDB enables AI-driven inventory classification
So, how does MongoDB empower the next generation of AI-driven inventory classification? It all comes down to four crucial steps, and MongoDB provides the robust technology and features to support every single one.
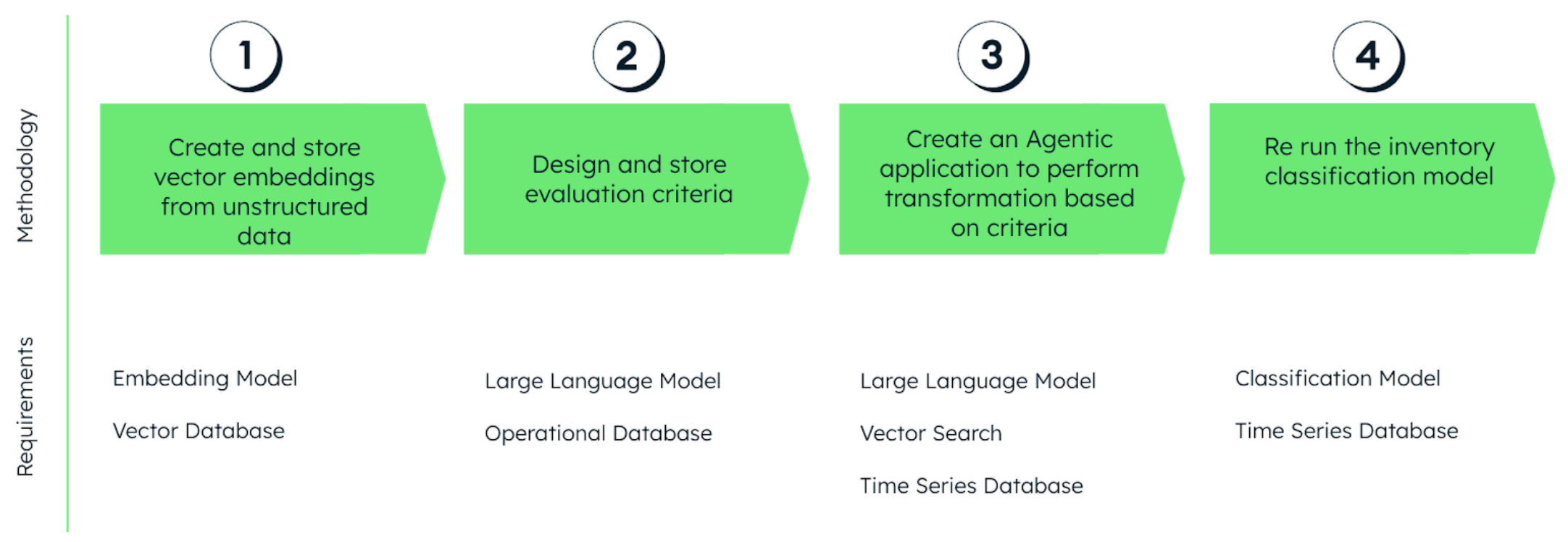
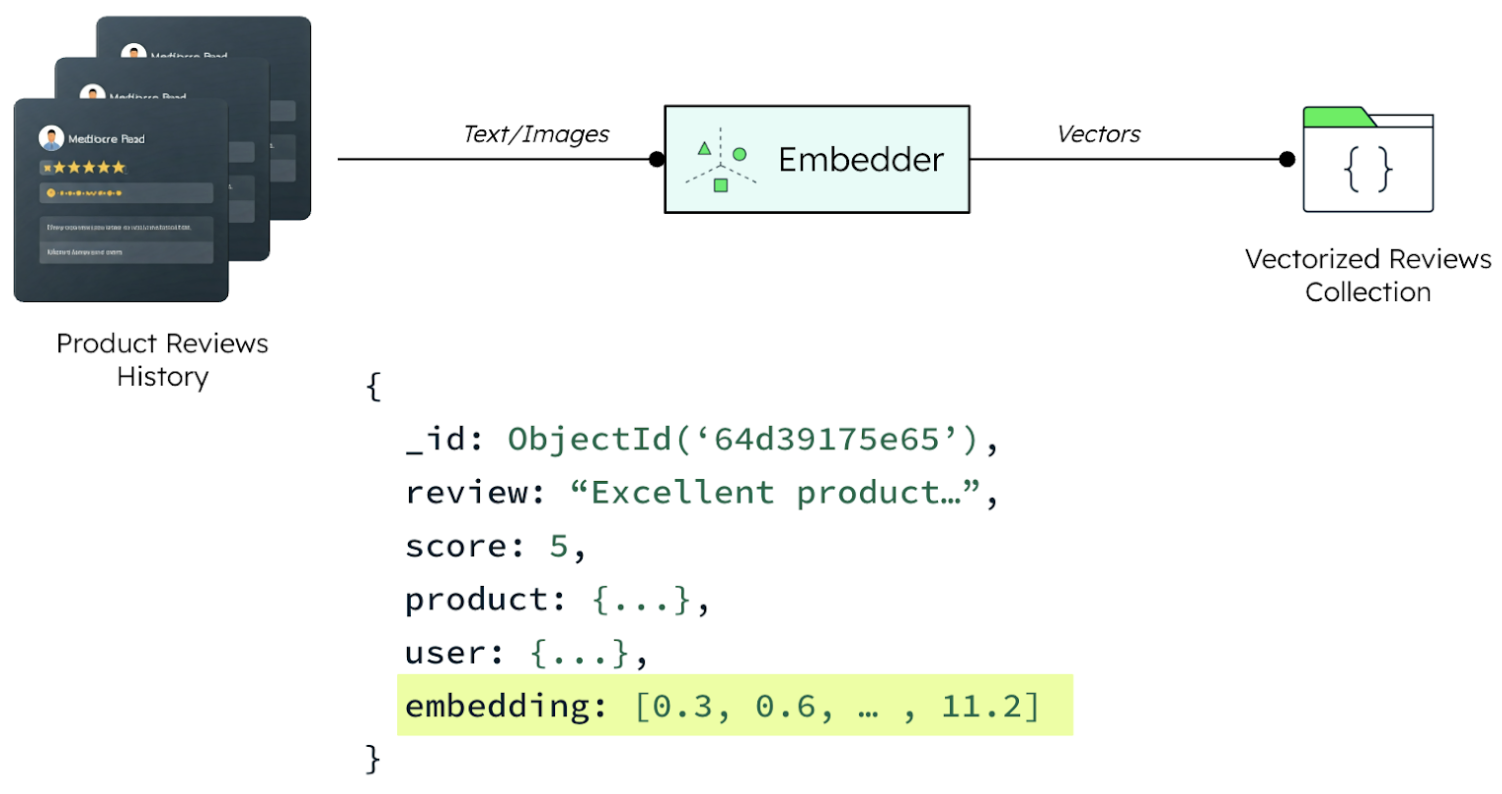
Step 1: Create and store vector embeddings from unstructured data
MongoDB Atlas enables modern vector search workflows. Unstructured data like product reviews, supplier notes, or customer support transcripts can be vectorized via embedding models (such as Voyage AI models) and ingested into MongoDB Atlas, where they are stored next to the original text chunks. This data then becomes searchable using MongoDB Atlas Vector Search, which allows you to run native semantic search queries directly inside the database.
Unlike solutions that require separate databases for structured and vector data, MongoDB stores them side by side using the flexible document model, enabling unified access via one API. This reduces system complexity, technical debt, and infrastructure footprint—and allows for low-latency semantic searches.
Step 2: Design and store evaluation criteria
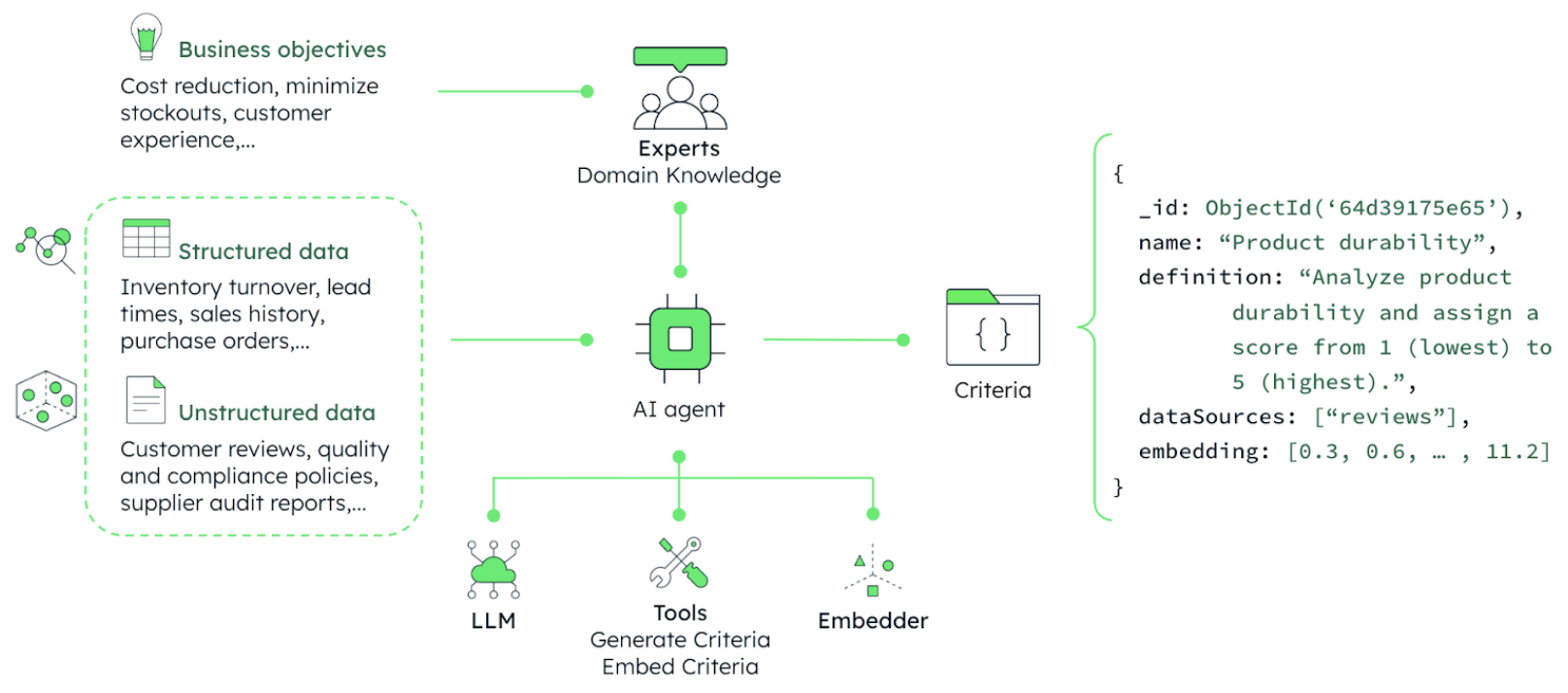
In a gen AI-powered inventory classification system, evaluation criteria are no longer a set of static rules stored in a spreadsheet. Instead, the criteria are dynamic and data-backed, and are generated via an AI agent using structured and unstructured data—and enriched by domain experts using business objectives and constraints.
As shown in Figure 5, the criteria for features like “Product Durability” can be defined based on relevant unstructured data stored in MongoDB (product reviews, audit reports) as well as structured data like inventory turnover and sales history. Such criteria are not just instructions or rules, but are knowledge objects with structure and semantic depth.
The AI agent uses tools such as generate_criteria and embed_criteria tool and iterates over each product in the inventory. It leverages the LLM to create the criteria definition and uses an embedding model (e.g., voyage-3-large) to generate embeddings of each definition.
MongoDB Atlas is uniquely suited to store these dynamic criteria. Each rule is modeled as a flexible JSON document containing the name of the feature, criteria definition, data sources use, and the embeddings. Since there are different types of products (different car models/makes and different car parts), the documents can evolve over time without requiring schema migrations and be queried and retrieved by the AI agent in real time. MongodB Atlas provides all the necessary tools for this design—a flexible document model database, vector search, and full search tools—that can be leveraged by the AI agent to create the criteria.
Step 3: Create an agentic application to perform transformation based on the criteria
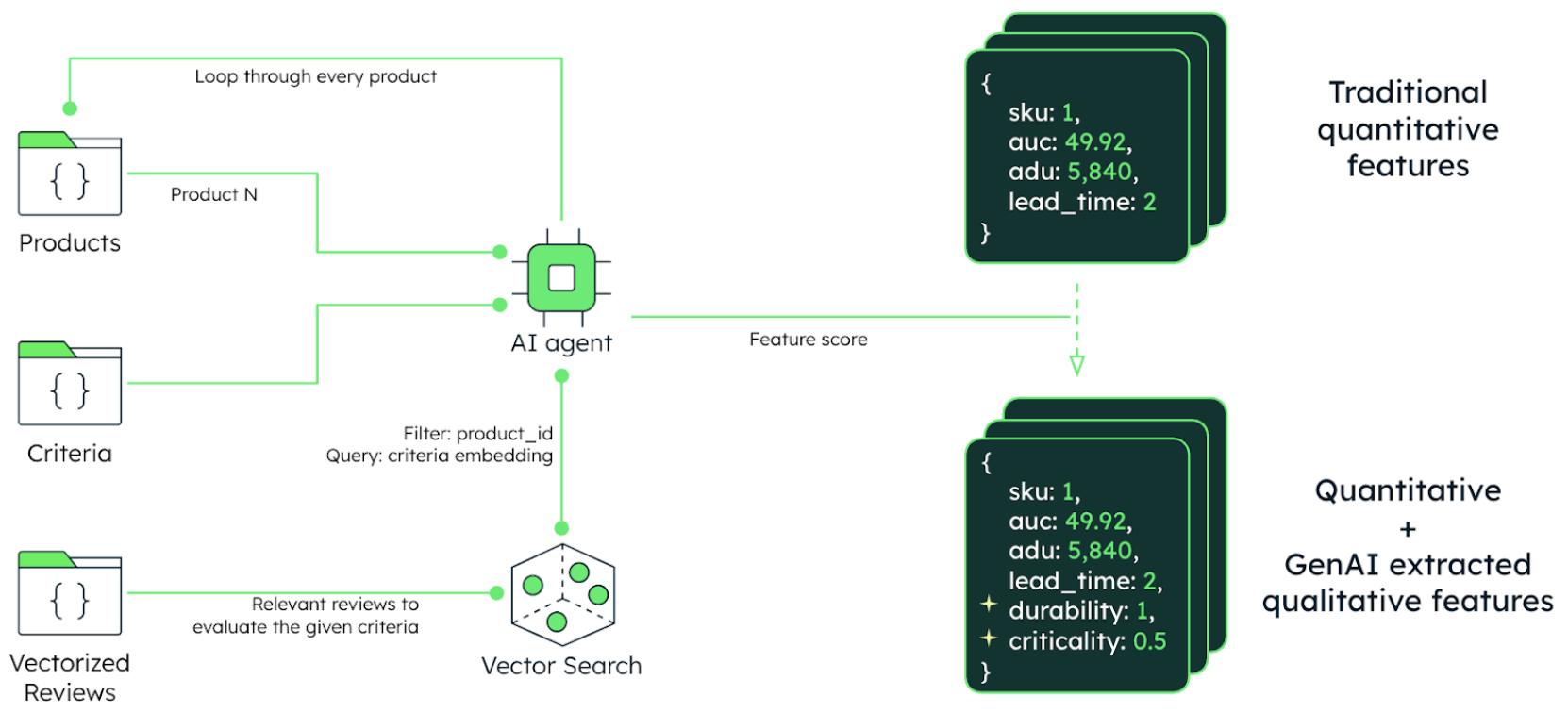
In the third step, we have another AI agent that operates over products, criteria, and unstructured data to generate enriched feature sets. This agent iterates over every product and uses MongoDB Atlas Vector Search to find relevant customer reviews to apply the criteria to and calculate a numerical feature score. The new features are added to the original features JSON document in MongoDB. In Figure 6, the agent has created “durability” and “criticality” features from the product reviews.
MongoDB Atlas is the ideal foundation for this agentic architecture. Again, it provides the agent the tools it needs for features to evolve, adding new dimensions without requiring schema redesign. This results in an adaptive classification dataset that contains both structured and unstructured data.
Step 4: Rerun the inventory classification model with new features added
As a final step, the inventory classification domain experts can assign or balance weights to existing and new features, choose a classification technique, and rerun inventory classification to find new inventory classes.
Figure 7 shows the process where generative AI features are used in the existing inventory classification algorithm.
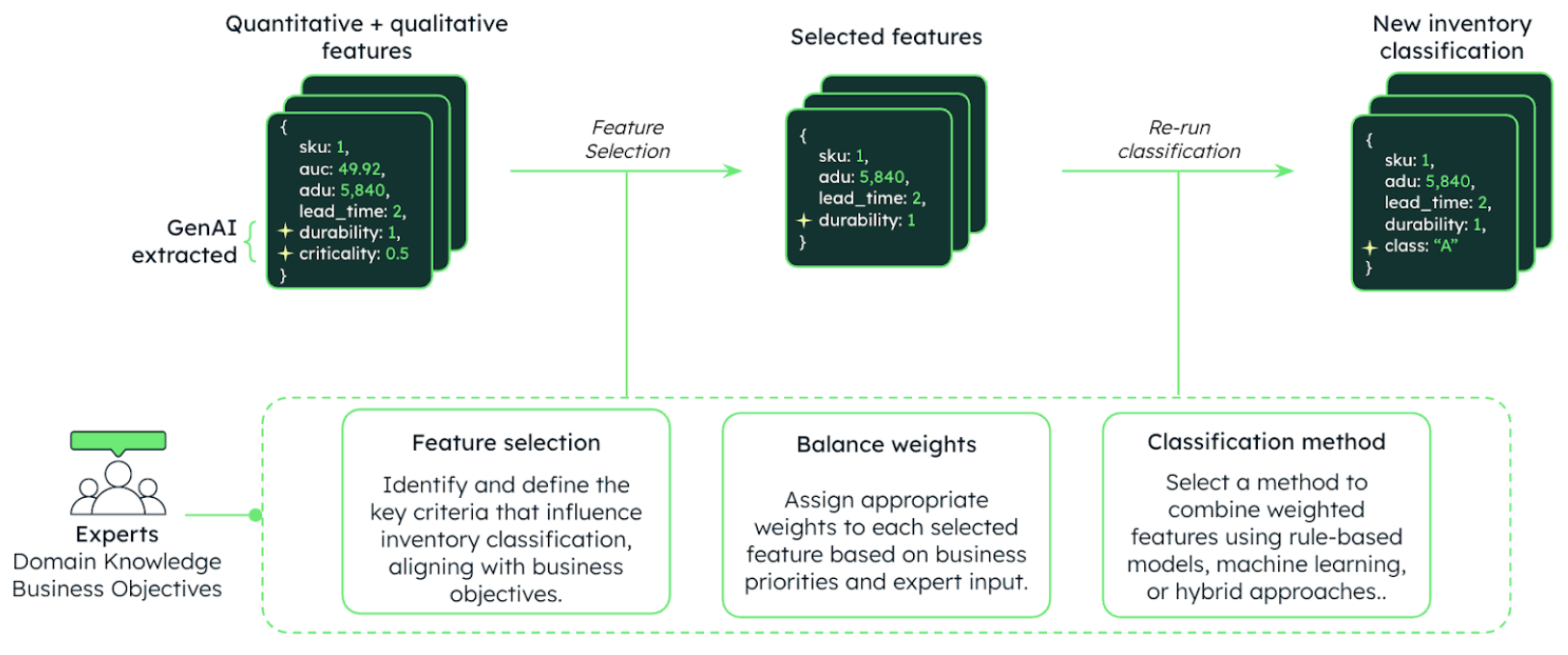
Figure 8 shows the solution in action. The customer satisfaction score is created by LLM a using customer reviews vectorized collection and then utilized in the inventory classification model with a new weight of 0.2.

Driving smarter inventory decisions
As the automotive industry navigates slowing sales and uneven inventory, traditional inventory classification techniques also need to evolve. Though such techniques provide a solid foundation, they fall short in the face of geopolitical uncertainty, tariff-driven supply shifts, and fast-evolving consumer expectations.
By combining structured sales and consumption data with unstructured insights, and enabling agentic AI using MongoDB, the automotive industry can enable a new era of inventory intelligence where products are dynamically classified based on all available data—both structured and unstructured.
Clone the GitHub repository if you are interested in trying out this solution yourself. To learn more about MongoDB’s role in the manufacturing industry, please visit our manufacturing and automotive webpage.