Search at scale is challenging. As powerful as vector search is, it can be tough to know how to properly weigh key factors like accuracy, cost, and throughput for larger workloads. We recently released the MongoDB Benchmark for Atlas Vector Search, which outlines crucial performance optimization strategies for vector search, providing a comprehensive guide to achieving optimal results with large-scale datasets. The primary goal of our guide is to significantly reduce friction for your first vector test at scale (>10M vectors) when evaluating performance for Atlas Vector Search.
With this new guide, our aim is to provide more context around how to use the benchmark, to explore the dataset (including factors considered), and to summarize and contextualize the results. Let’s take a closer look!
A note on benchmarking data
Every good presentation includes the requisite safe harbor slide, and the art and science of benchmarking is no different. Embarking on a large-scale vector workload can present significant hurdles stemming from a lack of accurate information and the inherent friction of initial benchmarks. Furthermore, the landscape of vector search and embedding models is rapidly evolving, and information can become outdated quickly, leading users down inefficient or incorrect paths. Without clear, up-to-date guidance, users can struggle to predict system behavior, optimize configurations, and confidently allocate resources.
It’s also worth noting that numerous factors (quantization, dimensionality, filtering, search node configuration, concurrency, sharding, and more) interact in complex ways. Understanding these interactions and their specific impact on a particular workload requires deep, accurate insights. Without this, users might optimize one aspect only to inadvertently degrade another.
This informational vacuum—coupled with the considerable setup overhead, complex parameter tuning, and the cost of experimentation involved in running the first benchmark—creates a substantial barrier to proving out and scaling a solution. Nonetheless, we feel that these benchmarks provide confidence in POCs for our customers and give them a starting point to work with (as opposed to having no compass to start with).
With these factors in mind, let's jump into an overview of the dataset.
A look at the dataset
The core of this performance analysis revolves around tests conducted on subsets of the Amazon Reviews 2023 dataset, which contained 48M item descriptions across 33 product categories. The dataset was chosen due to the ability to provide a realistic, large-scale e-commerce scenario, as well as offering rich data, including user reviews (ratings, text, helpfulness votes), item metadata (price, images), and detailed item names and descriptions, which are ideal to search over. For the variable dimension tests, subsets of 5.5 million items were used, embedded with voyage-3-large to produce 2048-dimensional vectors. Views were then created to slice these into 1024, 512, and 256-dimensional vectors for testing different dimensionalities. For the large-scale, high-dimensional test, a 15.3 million-item subset—also embedded with 2048-dimensional vectors from voyage-3-large—was used.
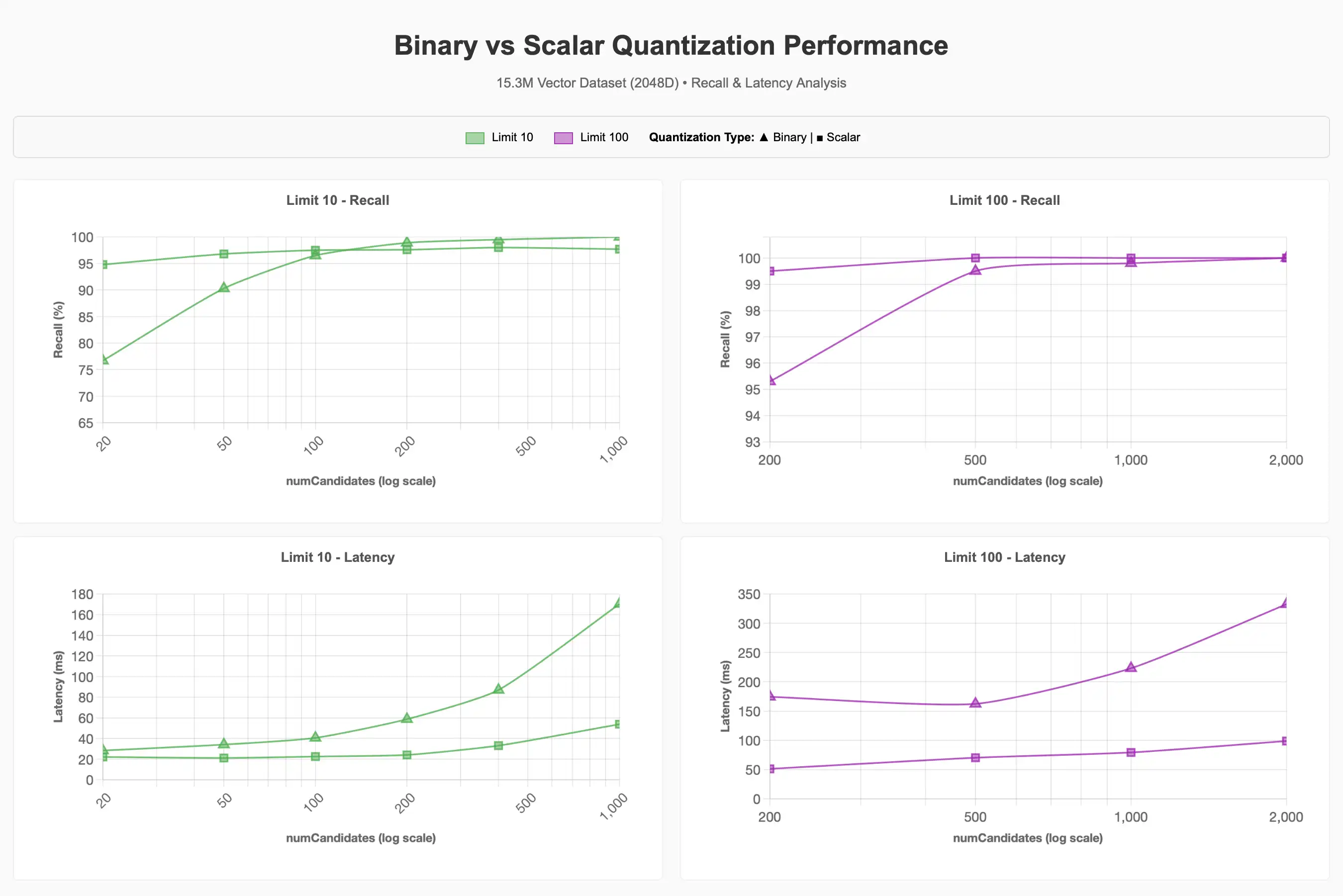
One of the key takeaways from the report is that at the highest dimensionality (15.3M vectors using voyage-3-large embeddings at 2048 dimensions), Atlas Vector Search with scalar or binary quantization configured retains 90–95% accuracy with less than 50ms of query latency. One item of note is that binary quantization can have higher latency when the number of candidates requested is in the hundreds due to the additional cost of rescoring with full-fidelity vectors, but still might be preferable for many large scale workloads due to cost effectiveness.
Methodology: Benchmarking with the Amazon reviews dataset
Now that we talked a little bit about the data itself and the information included, let’s outline some of the key factors that impact performance for Atlas Vector Search, and how we configured our benchmark to test them. It's also important to acknowledge why these variables are critical: Not every customer will be optimizing their search for the same thing. With that in mind, we will also attempt to identify the interplay and trade-offs between them.
While this list is not exhaustive (see the full report for more details), let’s review some of the key performance factors:
Recall: Recall (a measure of search accuracy) is significantly impacted by quantization and vector dimensionality. The report highlights that while scalar quantization generally starts with higher recall, binary quantization can approach similar accuracy levels by increasing numCandidates, though this often incurs higher latency due to an additional rescoring step. Furthermore, higher-dimensional vectors (1024d and 2048d) consistently maintain better recall, especially with larger datasets and quantization, compared to lower dimensions (256d and 512d), which struggle to exceed 70-80% recall.
Sizing and cost: The table in the benchmark details the resources required (RAM, storage) and associated costs for different search node tiers based on three different test cases involving varying dataset sizes, vector dimensions, and quantization methods (scalar or binary). The guide provides an example of a sample dataset noting the resource requirements scale linearly, noting how quantization reduces memory requirements substantially.
Concurrency and throughput: Throughput is evaluated with multiple requests issued concurrently. Scalar quantization generally achieves higher queries per second (QPS) across various limit values due to less work per query and no rescoring. Concurrency bottlenecks are often observed, indicating that higher latency can occur. Scaling out the number of search nodes or increasing available vCPUs is recommended to resolve these bottlenecks and achieve higher QPS.

Optimizing your vector search performance
This benchmark report thoroughly examines the performance of MongoDB Atlas Vector Search across various configurations and large datasets, specifically the Amazon Reviews 2023 dataset. It explores the impact of factors such as quantization (scalar and binary), vector dimensionality, filtering, search node configurations, binData compression, concurrency, and sharding on recall, latency, and throughput.
While there is never a “silver bullet” due to everyone’s definition of search “success” being different, we wanted to highlight some of the various levers to consider, and methods to get the most out of your own deployment. Our goal is to provide some key considerations for how to evaluate and improve your own vector search performance, and help you to properly weigh and contextualize the key factors. Ready to optimize your vector search experience?
Explore the guide in our documentation.
Run it yourself with our GitHub repo.