Vector search is often the first step in retrieval augmented generation (RAG) systems. In a previous post, we discussed the future of AI-powered search at MongoDB. At MongoDB, we’re making it easier to select an embedding model so your search solution can scale. At scale, the choice of vector representations and dimensionality can have a significant impact on the cost and performance of a vector search system.
In this blog post, we discuss options to reduce the storage and compute costs of your vector search solution.
The cost of dimensionality
Many MongoDB customers use vector indexes on the order of hundreds of gigabytes. An index’s size is determined by the number of documents and the dimensionality (or count of floating-point numbers) of the vector representation that encodes a document’s semantics. For example, it would require ~500 GB to store 41M documents if the embedding model uses 3072 dimensions to represent a document. At query time, each vector similarity computation will require 3072 floating-point operations.
However, if these documents could be represented by a 512-dimensional vector, a similar index would only require 84GB of storage—a six-fold reduction in storage costs, as well as less computation at query time. In sum, the dimensionality of a document’s vector representation will directly affect the storage and retrieval costs of the system. Smaller vectors are cheaper to store, index, and query since they are represented with fewer floating-point numbers, but this may come with a tradeoff in accuracy.
Put simply, an embedding model converts an input into a vector of fixed dimensions. The model was trained to ensure that vectors from similar documents are close to one another in the embedding space. The amount of storage and compute required for a vector search query is directly proportional to the dimensionality of the vector. If we can reduce the vector representation without compromising retrieval accuracy, our system can more quickly answer queries while using less storage space.
Matroyshka representation learning
So, how do we shrink vectors without losing meaning? One answer is Matroyshka Representation Learning (MRL) representations. Instead of reducing the vector size through quantization, MRL structures the embedding vector like a stacking doll, in which smaller representations are packed inside the full vector and appear very similar to the larger representation. This means we can select the level of fidelity we would like to use within our system because the similarity between lower-dimensional vectors approximates the similarity of their full-fidelity representations. With MRL representations, we can find the right balance of storage, compute, and accuracy.
To use MRL, we must first select an embedding model that was trained for it. When training with MRL, an additional term is added to the loss function that ensures the similarity between lower-dimensional representations approximates the similarities of the full-fidelity counterparts. Voyage AI’s latest text embedding models—voyage-3-large, voyage-3.5, and voyage-3.5-lite—are trained with MRL terms and allow the user to specify an output dimension of 256, 512, 1024, and 2048. We can use the output_dimension parameter to specify which representation we want to consider.
Let’s see how the similarities among shorter vectors can approximate the similarities among full-fidelity vectors with voyage-3.5:
We’ll use three MRL vectors, a query, a relevant document vector, and a non-relevant document vector. We expect the cosine similarity between the query and the relevant document vector to be larger than the similarity between the query and a non-relevant document vector. Cosine similarity measures the alignment between two vectors, where a high score indicates that the vectors point in the same direction in the embedding space. A score of 1.0 means the query and document vectors are identical, and a score of 0.0 means the vectors are orthogonal.
Let’s see if that’s the case:
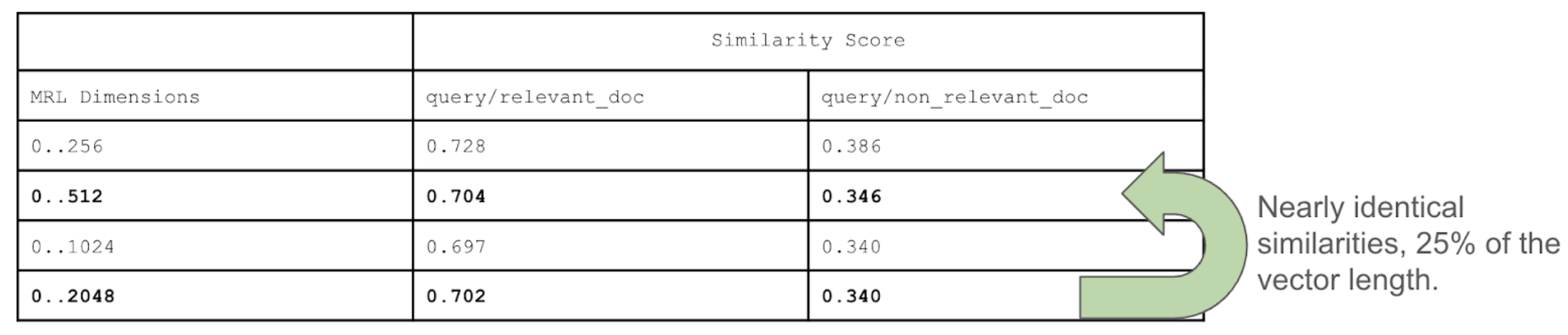
The full-fidelity similarity scores can be approximated well with the 256, 512, and 1024 dimension vectors, so using all 2048 dimensions may not be necessary. For example, the full fidelity scores, 0.702 and 0.340, are close to the cosine similarities of the 512-dimensional representations, 0.704 and 0.346. This suggests that indexes built using the shorter vectors will have similar performance to indexes that use the 2048-dimensional vectors.
MongoDB vector search collections. We will generate four vector search indexes, each with a different MRL configuration, and measure the retrieval performance on the dataset’s queries for each index (for existing vectors, we can build MRL indexes with Views). We will examine the normalized discounted cumulative gain (NDCG) and the mean reciprocal rank (MRR).
The results are below:
We can then analyze the plot of relative accuracy versus storage costs:
The results indicate that for this corpus, we can represent documents with vectors of 512 dimensions, as the system provides retrieval accuracies comparable to those of higher-dimensional vectors, while achieving a significant reduction in storage and compute costs.
This choice dramatically cuts the amount of storage and compute required for vector retrieval, so our system will provide the best retrieval quality for each dollar spent on storage, achieving ~99% relative performance at a quarter of the storage and compute cost.
Faster and cheaper search
This blog post demonstrates that we can easily assess shorter vector representations to reduce the cost of our vector search systems using MRL parameters exposed in VoyageAI’s models. Using retrieval quality analysis tools, we discover that a vector 25% the length of the full fidelity representation is suitable for our use case, so our system will be less expensive and faster.
MRL options enable our customers to select the optimal representation for their data. Evaluating new vector search options can lead to improved overall system performance. We’re continuing to make it easy to tune vector search solutions and will be releasing additional features to tune and measure search system performance.
For more information about Voyage AI's models, check out the Voyage AI documentation page.
Join our MongoDB Community to learn about upcoming events, hear stories from MongoDB users, and connect with community members from around the world.