I am using Mongo 4.2 (stuck with this) and have a collection say “product_data” with documents with the following schema:
_id:“2lgys2yxouhug5xj3ms45mluxw5hsweu_itmep53vy”
uIdHash:“2lgys2yxouhug5xj3ms45mluxw5hsweu”
userTS:1494055844000
systemTS:1582138336379
Case 1:
With this, I have the following indexes for the collection:
- _id: Regular and Unique (default)
- uIdHash: Hashed
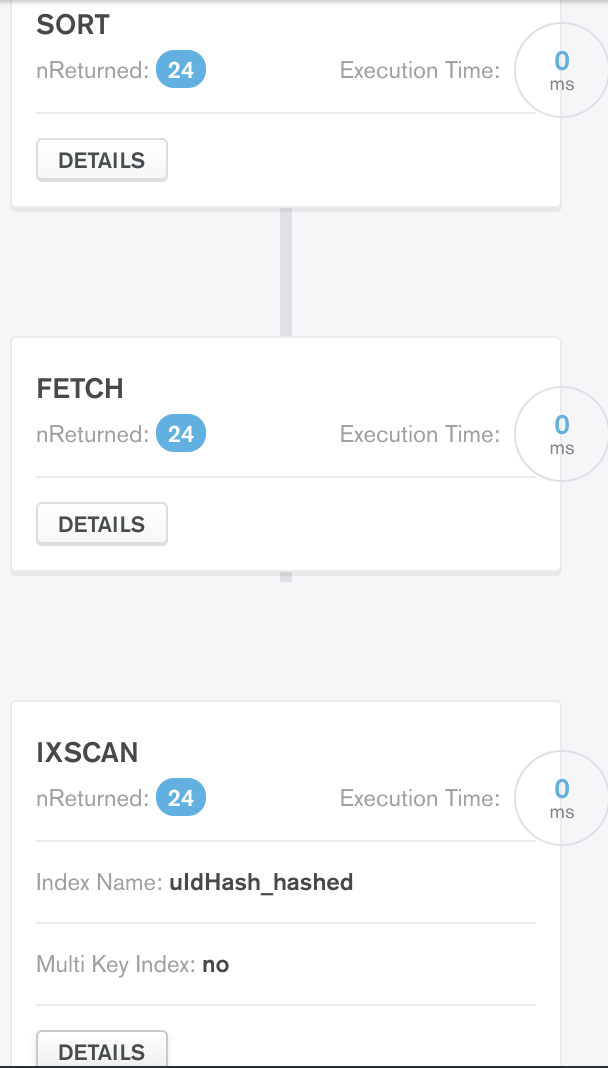
I tried to execute
db.product_data.find( {"uIdHash":"2lgys2yxouhug5xj3ms45mluxw5hsweu"}).sort({"userTS":-1}).explain()
and these are the stages in result:
Ofcourse, I could realize that it would make sense to have an additional compound index to avoid the mongo in-memory ‘Sort’ stage. So here is another case.
Case 2:
Now I have attempted to add another index with those which were existing
3. {uIdHash:1 , userTS:-1}: Regular and Compound
Up to my expectation, the result of execution here was able to optimize on the sorting stage:
<>
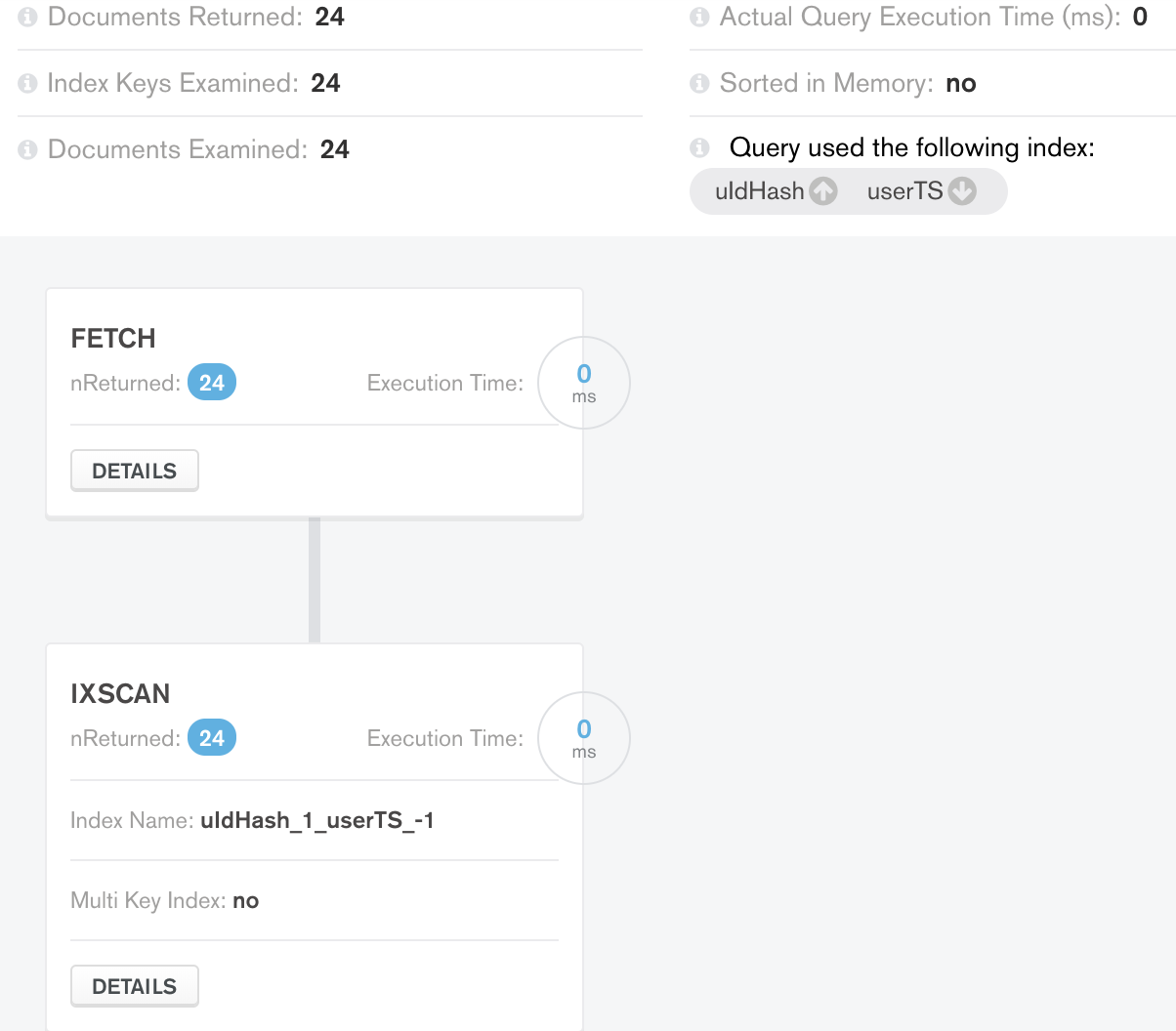
All good so far, now that I am looking to build for pagination on top of this query. I would need to limit the data queried. Hence the query further translates to
db.product_data.find( {"uIdHash":"2lgys2yxouhug5xj3ms45mluxw5hsweu"}).sort({"userTS":-1}).limit(10).explain()
The result for each Case now are as follows:
Case 1 Limit Result:
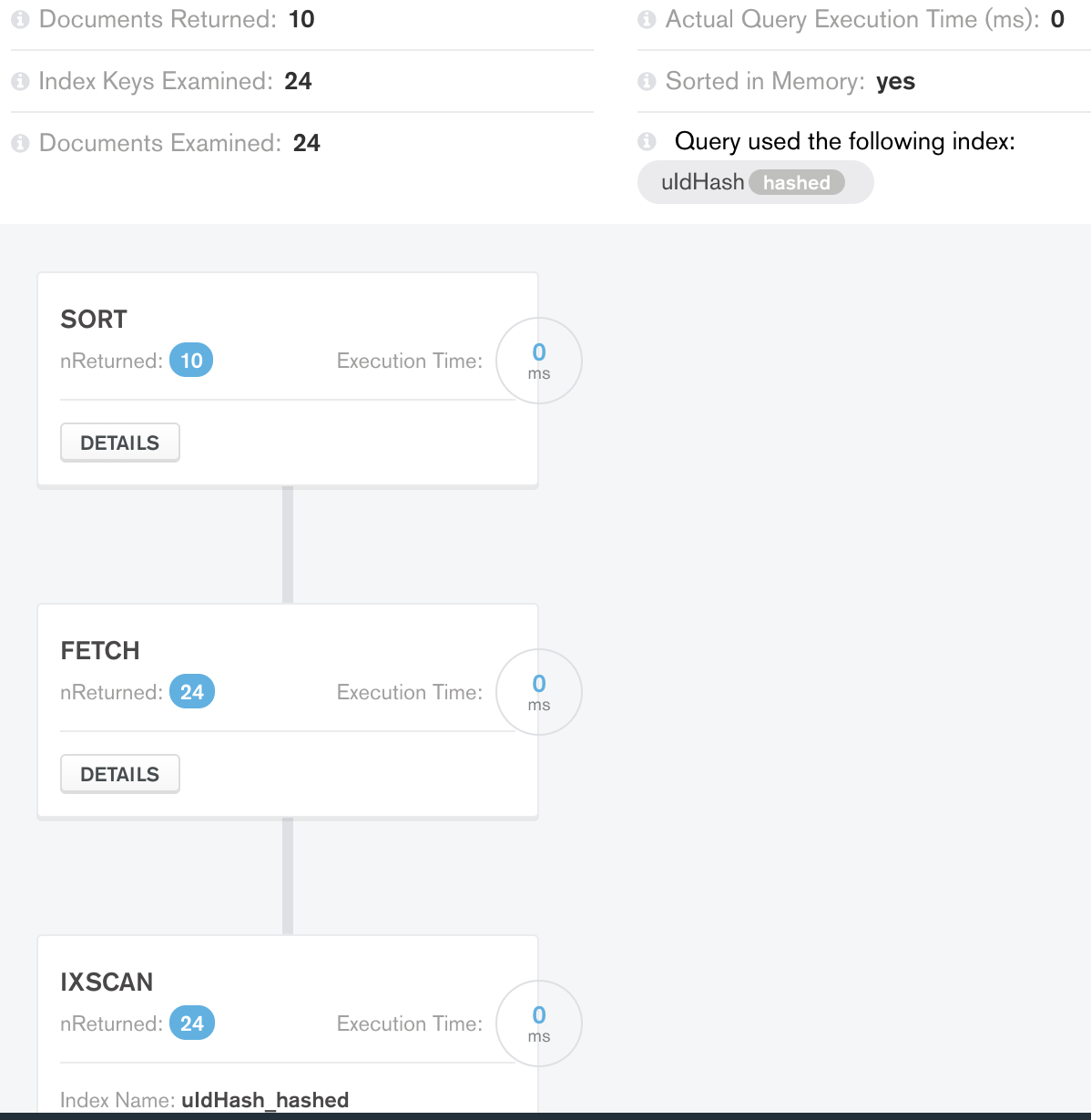
The in-memory sorting does less work (36 instead of 50) and returns the expected number of documents.
Fair enough, a good underlying optimization within the stage.
Case 2 Limit Result:
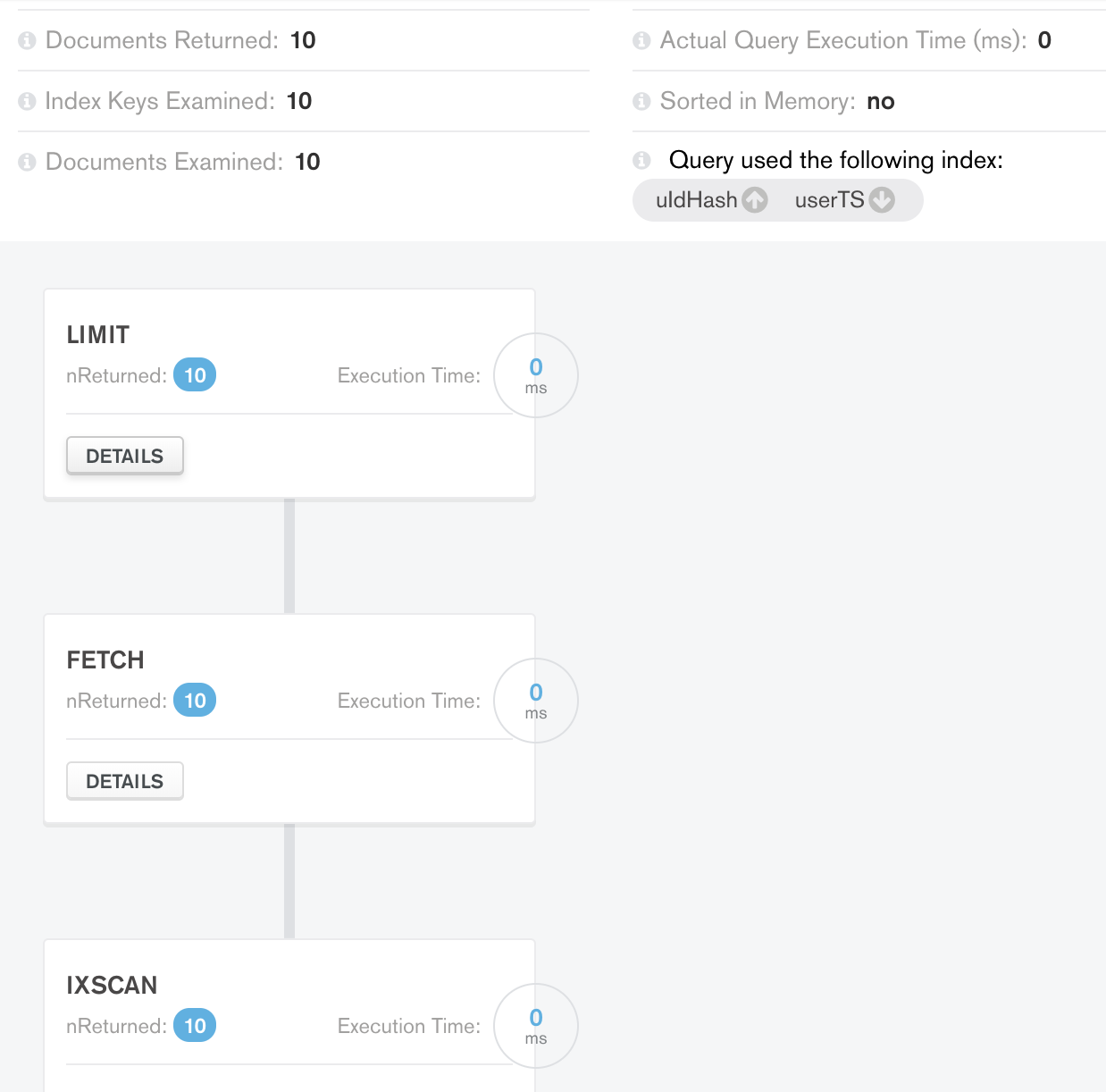
Surprisingly, with the compound index in use and the data queried, there is an additional Limit stage added to processing!
The doubts now I have are as follows:
-
Why do we need an additional stage for LIMIT, when we already have 10 documents returned from the FETCH stage?
-
What would be the impact of this additional stage? Given that I need pagination, shall I stick with Case 1 indexes and not use the last compound index?